一种面向灯塔认知多场景鲁棒的视觉3D目标检测方法
本技术涉及自动驾驶,尤其是涉及一种面向灯塔认知多场景鲁棒的视觉3d目标检测方法。
背景技术:
1、视觉3d目标检测在自动驾驶系统中起着至关重要的作用,它可以帮助自动驾驶车辆感知周围环境,准确识别和定位障碍物等信息。但不同的天气条件会导致图像的对比度和清晰度不同,不同的地理环境会导致图像中检测数据分布不同,因此单一视觉3d检测模型只能应对一个场景,自动驾驶汽车需要整合多个感知模型来实现全面的场景感知能力,从而拓展自动驾驶感知能力。但这种做法需要更多的软件和硬件资源,增加了汽车系统的复杂性和成本,不同模型之间的参数和设置可能会相互影响,导致系统不稳定。
技术实现思路
1、有鉴于此,本技术提供了一种面向灯塔认知多场景鲁棒的视觉3d目标检测方法,以解决上述技术问题。
2、第一方面,本技术实施例提供一种面向灯塔认知多场景鲁棒的视觉3d目标检测方法,包括:
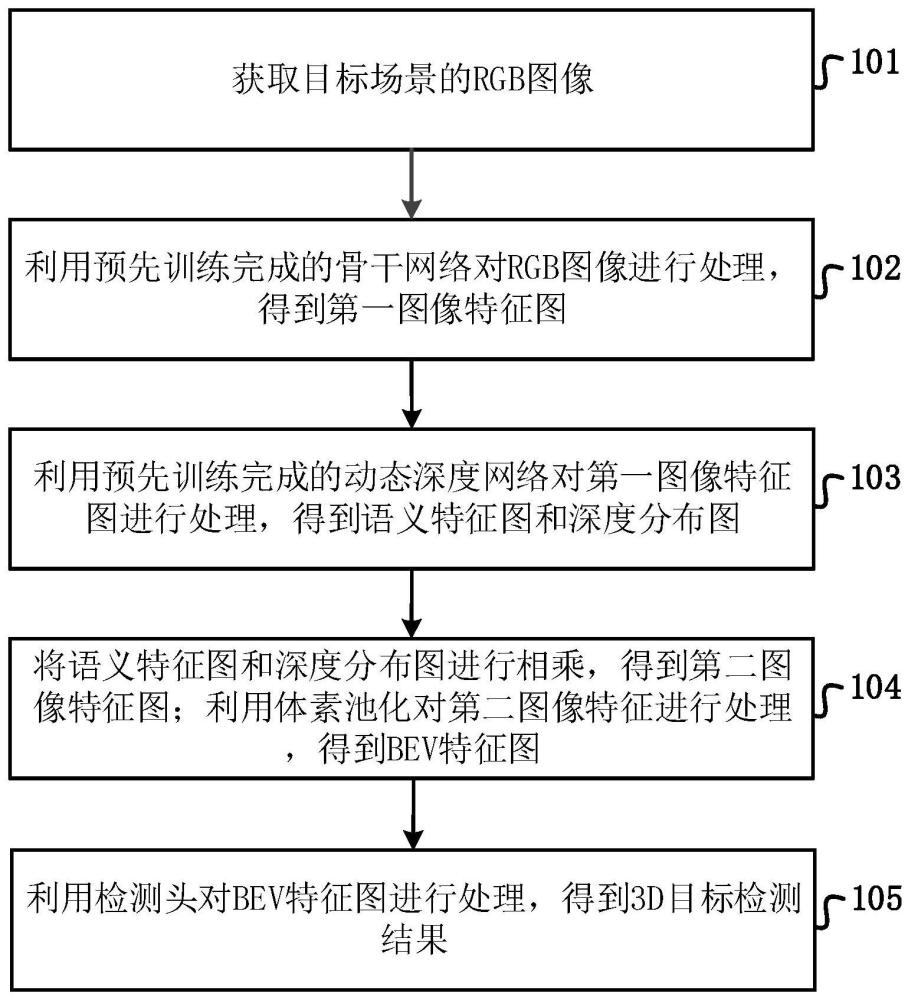
3、获取目标场景的rgb图像;
4、利用预先训练完成的骨干网络对rgb图像进行处理,得到第一图像特征图;
5、利用预先训练完成的动态深度网络对第一图像特征图进行处理,得到语义特征图和深度分布图;
6、将语义特征图和深度分布图进行相乘,得到第二图像特征图;利用体素池化对第二图像特征进行处理,得到bev特征图;
7、利用检测头对bev特征图进行处理,得到3d目标检测结果。
8、进一步地,所述动态深度网络包括:场景感知鉴别器、语义处理分支和深度处理分支;
9、利用预先训练完成的骨干网络对rgb图像进行处理,得到第一图像特征图;包括:
10、利用所述场景感知鉴别器对第一图像特征图进行处理,得到场景概率向量p,将场景概率向量p分别输出至语义处理分支和深度处理分支;
11、利用所述语义处理分支对第一图像特征图和场景概率向量p进行处理,得到语义特征图;
12、利用所述深度处理分支对第一图像特征图和场景概率向量p进行处理,得到深度分布图。
13、进一步地,所述场景感知鉴别器包括:全局平均池化层、1×1卷积核、第一sigmoid函数、第一全连接层、relu激活函数、第二全连接层和第二sigmoid函数;其中,全局平均池化层分别与1×1卷积核和第一全连接层连接;第一sigmoid函数分别与1×1卷积核和第一全连接层连接;第一全连接层、relu激活函数、第二全连接层和第二sigmoid函数依次连接;
14、利用所述场景感知鉴别器对第一图像特征图进行处理,得到场景概率向量p;包括:
15、利用全局平均池化层将第一图像特征图中每个通道的信息压缩为一个标量,得到长度为通道数的压缩向量;
16、利用1×1卷积核对压缩向量进行处理,得到一个融合特征图;
17、利用第一sigmoid函数将融合特征图转化为0到1之间的值,将该值与压缩向量相乘,得到加强特征的压缩向量;
18、利用第一全连接层和relu激活函数对加强特征的压缩向量进行处理,得到一个长度为k的激活向量;
19、利用第二全连接层和sigmoid函数对激活向量进行加权和归一化处理,得到一个长度为k的场景概率向量p=(π1,π2,...,πk),其中,πi为rgb图像为第i个场景的概率值,1≤i≤k。
20、进一步地,语义处理分支包括动态卷积层;所述动态卷积层包括:k个并行的卷积核、加权处理单元、bn层和激活层;其中,k个并行的卷积核包括:卷积核conv1、…、卷积核convk;所述加权处理单元利用场景概率向量p对k个并行的卷积核的输出进行加权处理,输出加权特征图
21、
22、其中,fi为卷积核convi对第一图像特征图f进行处理后输出的特征图。
23、进一步地,所述深度处理分支包括四个依次连接的动态卷积块dyblock;动态卷积块dyblock由多个动态卷积层堆叠而成。
24、进一步地,所述方法还包括:
25、获取训练集;所述训练集包括k个场景的多个rgb图像样本,rgb图像样本的标签包括:图像标注结果和k维的标签向量,对于第j个场景的rgb图像样本,k维的标签向量yj=[0,0,...,1,...,0],其中1出现在标签向量的第j个位置上;
26、利用骨干网络对rgb图像样本进行处理,得到第一图像样本特征图;
27、利用动态深度网络对第一图像样本特征图进行处理,得到样本语义特征图和样本深度分布图;
28、将样本语义特征图和样本深度分布图进行相乘,得到第二图像样本特征图;利用体素池化对第二图像样本特征进行处理,得到样本bev特征图;
29、利用检测头对样本bev特征图进行处理,得到预测结果;
30、根据动态深度网络中场景感知鉴别器输出的k位二进制码和标签向量,计算二进制交叉熵损失函数lsce;
31、根据rgb图像样本的预测结果和图像标注结果,计算第一损失函数ldet;
32、计算总损失函数值l:
33、l=ldet+lsce
34、利用总损失函数值l,对骨干网络和动态深度网络的参数进行更新。
35、进一步地,根据动态深度网络中场景感知鉴别器输出的k位二进制码和标签向量,计算二进制交叉熵损失函数lsce;包括:
36、将场景感知鉴别器的第二全连接层的输出设置为k个神经元,每个神经元的输出表示二进制码的一个位;
37、将每个神经元的输出值通过第二sigmoid函数进行激活,并将其截断到0和1之间,即将输出值大于等于0.5的设置为1,小于0.5的设置为0,得到一个k位二进制码;
38、二进制交叉熵损失函数lsce的计算公式为:
39、
40、其中,n是rgb图像样本数量,yij是第i个rgb图像样本的k维标签向量的第j位,是通过第i个rgb图像样本预测得到的k位二进制码的第j位。
41、第二方面,本技术实施例提供一种面向灯塔认知多场景鲁棒的视觉3d目标检测装置,包括:
42、获取单元,用于获取目标场景的rgb图像;
43、特征提取单元,用于利用预先训练完成的骨干网络对rgb图像进行处理,得到第一图像特征图;
44、第一处理单元,用于利用预先训练完成的动态深度网络对第一图像特征图进行处理,得到语义特征图和深度分布图;
45、第二处理单元,用于将语义特征图和深度分布图进行相乘,得到第二图像特征图;利用体素池化对第二图像特征进行处理,得到bev特征图;
46、目标检测单元,用于利用检测头对bev特征图进行处理,得到3d目标检测结果。
47、第三方面,本技术实施例提供一种电子设备,包括:存储器、处理器和存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本技术实施例的方法。
48、第四方面,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令被处理器执行时实现本技术实施例的方法。
49、本技术提高了多场景的目标检测精度。
- 还没有人留言评论。精彩留言会获得点赞!