一种面向知识点的科技资源推荐方法及系统
本发明涉及科教案例、文献分析的人工智能处理技术,具体涉及一种面向知识点的科技资源推荐方法及系统。
背景技术:
1、目前,学习者能够通过互联网和数字技术获取大量的科技资源,如在线课程、学术论文、教学视频等。然而,面对如此庞大的资源量,学习者往往面临着如何选择适合自己学习需求和知识点的科技资源的难题。科技论文作为科学研究的记录和科研成果的载体,是知识点的总和,也是科技资源中最核心的一种。然而随着科技出版物的爆炸式增长,高效、全面地找到符合需求、适配知识点的科技论文变得越来越困难。当前的引文推荐系统旨在为给定的文本上下文或论文内容推荐科技论文列表。然而,现有的引文推荐系统都仅把输入论文的参考文献列表中的论文作为标准,但输入论文的参考文献列表通常也是不完美的,需要推荐其他合适的引文作为补充。一个常见的例子是,在学术出版场景中,投稿论文在同行评审过程中被审稿人认为缺少对重要论文的引用。
2、通常引文推荐模型分为两类:整体引文推荐,为给定的论文稿件推荐参考文献列表;局部引文推荐,为论文中某一特定的发生引用的上下文片断推荐引文。总的来说,引文推荐任务旨在为给定的文本上下文或缺少参考文献的论文草稿自动推荐适当的引文。现有的研究仅将论文内容作为研究中心,忽略了输入论文本身的参考文献潜在的不完善之处,以及缺失重要引文的负面影响,以致投稿论文由于各种原因被审稿人认为缺乏重要引文成为常见现象。因此,针对现有科技资源推荐方法,如何实现知识点的融合以提高推荐的效果,已成为一项亟待解决的关键技术问题。
技术实现思路
1、本发明要解决的技术问题:针对现有技术的上述问题,提供一种面向知识点的科技资源推荐方法及系统,本发明旨在结合论文内容文本和已有引文来提高对投稿论文的遗漏引文推荐的准确度,提高推荐准确度以及引文推荐效率。
2、为了解决上述技术问题,本发明采用的技术方案为:
3、一种面向知识点的科技资源推荐方法,包括:
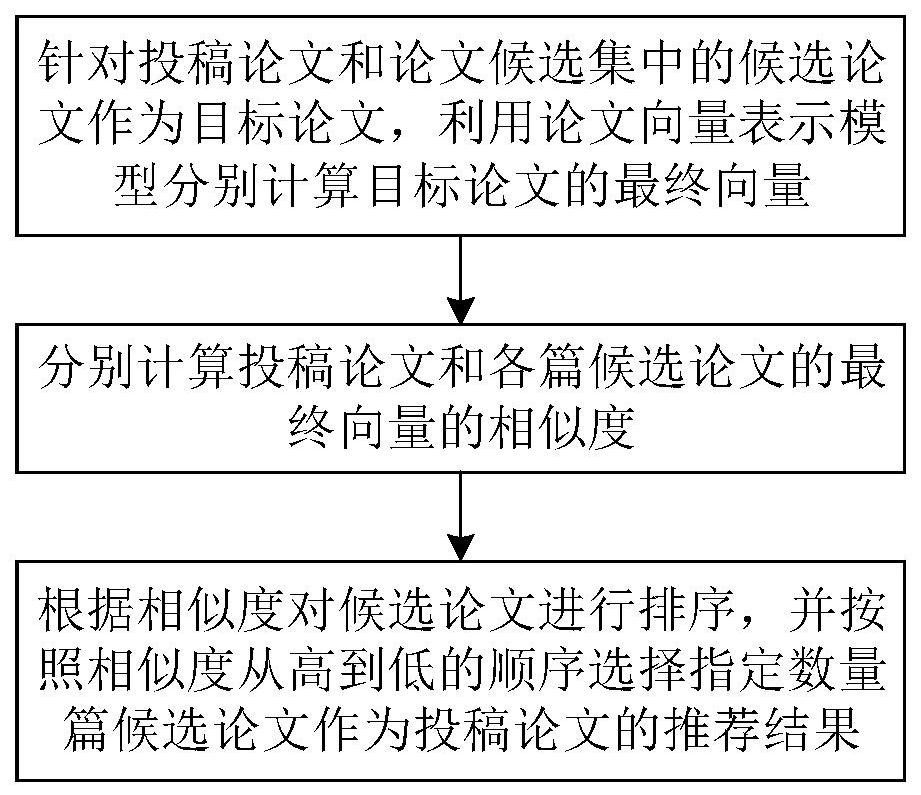
4、s101,针对投稿论文和论文候选集中的候选论文作为目标论文,利用论文向量表示模型分别计算目标论文的最终向量;所述论文向量表示模型包括:文本编码器,用于分别从输入的目标论文的标题t和摘要a,以及目标论文的n篇参考文献的标题t中挖掘知识点并编码为对应的隐藏状态;线性层,用于将隐藏状态线性处理得到目标论文的向量表示vcontent以及n篇参考文献的标题向量表示引文解析器,用于将目标论文的向量表示vcontent以及n篇参考文献的标题向量表示基于交叉注意力机制挖掘潜在的引用偏好和可能遗漏的知识点,得到参考文献向量表示vr;拼接层,用于将目标论文的向量表示vcontent和参考文献向量表示vr拼接后作为目标论文的最终向量;
5、s102,分别计算投稿论文和各篇候选论文的最终向量的相似度;
6、s103,根据相似度对候选论文进行排序,并按照相似度从高到低的顺序选择指定数量篇候选论文作为投稿论文的推荐结果。
7、可选地,文本编码器将输入的目标论文的标题t和摘要a挖掘知识点并编码为对应的隐藏状态包括:首先将目标论文的标题t和摘要a拼接,并在它们之间插入句子分隔符标记、最前面插入前序标记后输入到bert编码器中以获得一系列隐藏状态:
8、
9、上式中,h[c]为前序标记[cls]对应的隐藏状态,为对应的隐藏状态,为对应的隐藏状态,bert为bert编码器,[c]为bert编码器添加到序列前面的前序标记[cls],分别为标题t中的第1~i个单次,[s]为bert编码器添加句子分隔符标记[sep],分别为摘要a的第j个单词,bert编码器为输入的每一个单次或标记均生成一个对应的隐藏状态;然后将前序标记[cls]对应的隐藏状态h[c]输入一个线性层,得到目标论文的向量表示vcontent。
10、可选地,文本编码器将输入的目标论文的n篇参考文献的标题t挖掘知识点并编码为对应的隐藏状态时,针对目标论文的任意第x篇参考文献的编码包括:首先将第x篇参考文献的标题t最后面插入句子分隔符标记、最前面插入前序标记后输入到bert编码器中以获得一系列隐藏状态:
11、
12、上式中,为第x篇参考文献的前序标记[cls]对应的隐藏状态,分别为第x篇参考文献的第1~mx个单词对应的隐藏状态,bert为bert编码器,[c]为bert编码器添加到序列前面的前序标记[cls],分别为第x篇参考文献的第1~mx个单词,[s]为bert编码器添加句子分隔符标记[sep];然后将前序标记[cls]对应的隐藏状态输入一个线性层,得到第x篇参考文献的标题向量表示
13、可选地,引文解析器将目标论文的向量表示vcontent以及n篇参考文献的标题向量表示基于交叉注意力机制挖掘潜在的引用偏好和可能遗漏的知识点得到参考文献向量表示vr包括:
14、s201,根据下式计算注意力层的交叉注意力权重向量α:
15、
16、上式中,softmax为softmax激活函数,交叉注意力权重向量α中任意第x维的元素αx为第x篇参考文献的标题向量表示的权重;
17、s202,根据下式将n篇参考文献的标题向量表示引入注意力层的,从而得到参考文献向量表示vr:
18、
19、上式中,αx为交叉注意力权重向量α中任意第x维的元素,为第x篇参考文献的标题向量表示,n为参考文献的数量。
20、可选地,拼接层将目标论文的向量表示vcontent和参考文献向量表示vr拼接后作为目标论文的最终向量的表达式为:
21、
22、上式中,v为目标论文的最终向量,t表示向量的转置操作。
23、可选地,步骤s101之前包括采用样本论文p、正样例论文p+和负样例论文p-来训练论文向量表示模型,其中正样例论文p+为契合样本论文p的知识点的论文,负样例论文p-为未被样本论文p引用或审稿人推荐引用的论文,且训练论文向量表示模型采用的损失函数为三元组边际损失函数。
24、可选地,所述三元组边际损失函数的函数表达式为:
25、l=max{s(vp,v-)-s(vp,v+)+m,0},
26、上式中,l为三元组边际损失函数,max为取最大值,vp为样本论文p利用论文向量表示模型得到的最终向量,v+为正样例论文p+利用论文向量表示模型得到的最终向量,v-为负样例论文p-利用论文向量表示模型得到的最终向量,s为计算相似度,m为损失边际超参数。
27、可选地,所述采用样本论文p、正样例论文p+和负样例论文p-来训练论文向量表示模型时,负样例论文p-的来源包括:(1)从语料库中随机选择的论文;(2)针对样本论文p及其候选负样例论文,分别计算样本论文p和各篇候选负样例论文的最终向量的相似度,并根据相似度对候选论文进行排序,排除相似度最高的指定数量篇候选负样例论文,剩余的候选负样例论文中选择的相似度最高的一篇或多篇候选负样例论文。
28、此外,本发明还提供一种面向知识点的科技资源推荐系统,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行所述面向知识点的科技资源推荐方法。
29、此外,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序用于被微处理器编程或配置以执行所述面向知识点的科技资源推荐方法。
30、和现有技术相比,本发明主要具有下述优点:
31、1.本发明利用引文解析器对输入论文的参考文献列表里的论文进行表征学习,并和论文内容进行融合,挖掘了论文潜在的引用偏好和可能遗漏的方面,能够帮助推荐性能提升。
32、2.本发明不仅能处理传统引文推荐任务,即为论文内容推荐相关引文;还能为输入论文已有的引用列表进行补全,拓展了应用场景。
- 还没有人留言评论。精彩留言会获得点赞!