图像分类模型训练数据选取方法、装置及图像分类方法与流程
本发明属于图像处理领域,涉及一种图像分类模型训练数据选取方法、装置及图像分类方法。
背景技术:
1、各行各业新兴的大数据已成为技术和经济发展的驱动力,数据的作用在于训练各种模型,通过模型来赋能更行各业。对于图像分类模型,在进行训练时通常面对多个图像数据集,基于训练条件和时间等要求,实际情况下并不能将所有的图像数据集均用于图像分类模型的训练中,通常是挑选一部分图像数据集来进行训练。而图像数据集的质量决定了模型的好坏,为了挑选质量更好的图像数据集,需要评估图像数据集的数据价值的方法。图像数据集的数据价值很大程度上取决于它在特定的机器学习模型的贡献度,这里的核心挑战是如何公平地、准确地评估图像数据集中每个图像数据对特定性能指标的学习算法的贡献。
2、解决此问题的最广泛使用的算法是排列抽样算法(也称为蒙特卡洛抽样),其首先对各图像数据集进行随机排列采样,然后从排列中的第一个元素到最后一个元素逐个扫描,计算每个元素对其前面元素集合的边际贡献,最后重复相同的过程在多个排列上,并将它们所有边际贡献的平均值作为夏普利值的近似值,然后使用夏普利值来评估数据价值,进而实现图像数据集选取。但是,这种方法的边际贡献需要基于训练图像分类模型来实现,并且需要不断地重复训练图像分类模型,当图像数据集较多时,训练次数会指数级增长,假设图像数据集个数为n,那么图像分类模型需要训练的次数为n的阶乘,计算效率很低,而且单个图像数据集中的图像数据较多时也会增加单次训练的时间,导致较高的实施成本。
技术实现思路
1、本发明的目的在于克服上述现有技术的缺点,提供一种图像分类模型训练数据选取方法、装置及图像分类方法。
2、为达到上述目的,本发明采用以下技术方案予以实现:
3、本发明第一方面,提供一种图像分类模型训练数据选取方法,包括:
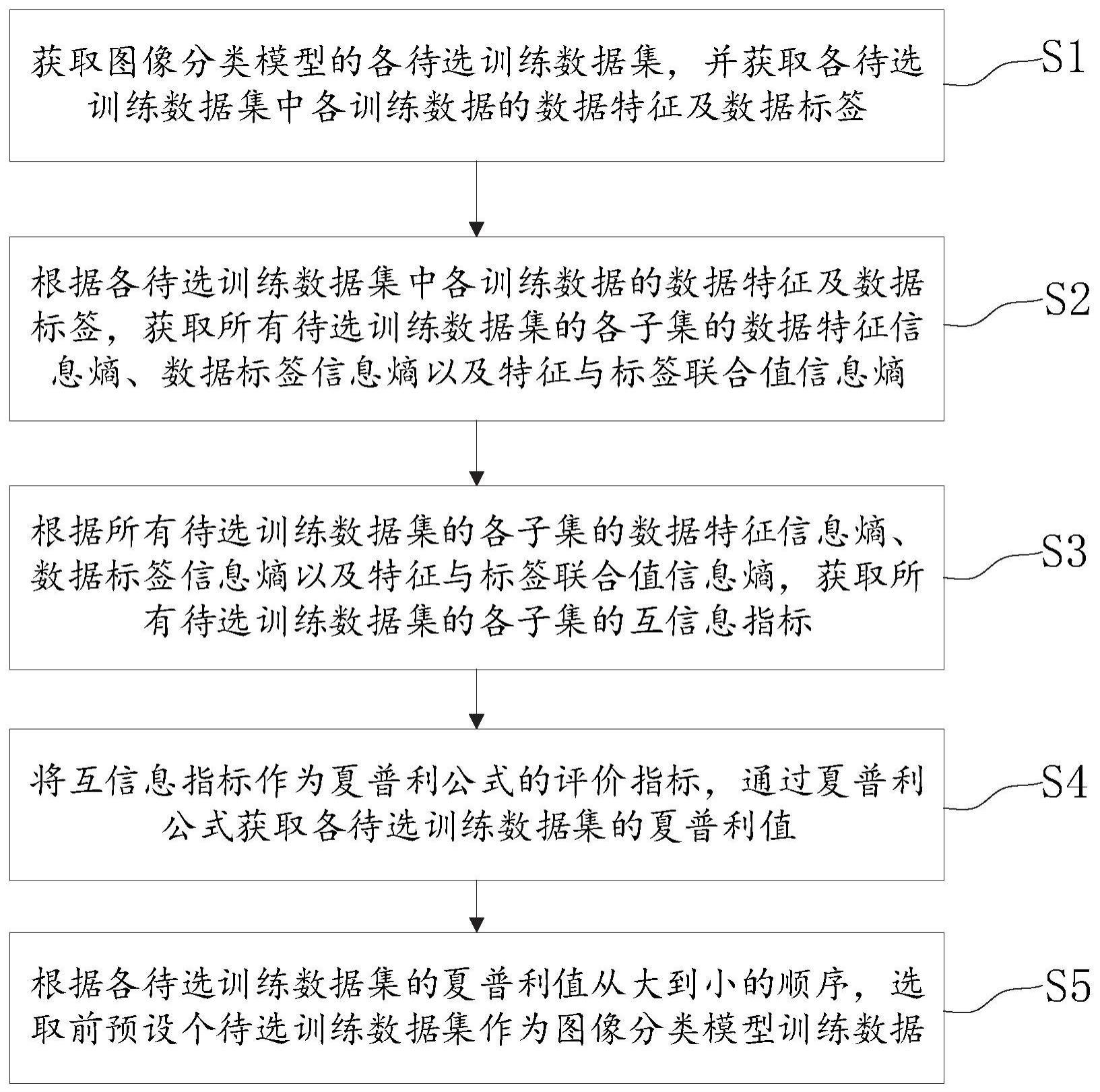
4、获取图像分类模型的各待选训练数据集,并获取各待选训练数据集中各训练数据的数据特征及数据标签;
5、根据各待选训练数据集中各训练数据的数据特征及数据标签,获取所有待选训练数据集的各子集的数据特征信息熵、数据标签信息熵以及特征与标签联合值信息熵;
6、根据所有待选训练数据集的各子集的数据特征信息熵、数据标签信息熵以及特征与标签联合值信息熵,获取所有待选训练数据集的各子集的互信息指标;
7、将互信息指标作为夏普利公式的评价指标,通过夏普利公式获取各待选训练数据集的夏普利值;
8、根据各待选训练数据集的夏普利值从大到小的顺序,选取前预设个待选训练数据集作为图像分类模型训练数据。
9、可选的,所述根据各待选训练数据集中各训练数据的数据特征及数据标签,获取所有待选训练数据集的各子集的数据特征信息熵、数据标签信息熵以及特征与标签联合值信息熵包括:
10、遍历所有待选训练数据集的各子集,通过下式得到当前子集的数据特征信息熵h(dest):
11、
12、其中,destpi为当前子集中各训练数据的数据特征中第i种数据特征的概率,t为当前子集中各训练数据的数据特征总种数;
13、遍历所有待选训练数据集的各子集,通过下式得到当前子集的数据标签信息熵h(src):
14、
15、其中,srcpi为当前子集中各训练数据的数据标签中第i种数据标签的概率,m为当前子集中各训练数据的数据标签总种数;
16、遍历所有待选训练数据集的各子集,通过下式得到当前子集的特征与标签联合值信息熵h(dest-src):
17、
18、其中,dest-srcpi为当前子集中各训练数据的特征与标签联合值中第i种特征与标签联合值的概率,k为当前子集中各训练数据的特征与标签联合值总种数,特征与标签联合值通过在数据特征后附加数据标签得到。
19、可选的,所述根据各待选训练数据集中各训练数据的数据特征及数据标签,获取所有待选训练数据集的各子集的数据特征信息熵、数据标签信息熵以及特征与标签联合值信息熵前,将数据特征进行离散化处理。
20、可选的,所述将数据特征进行离散化处理包括:通过基于数量的分箱方法、等距分箱方法或聚类方法将数据特征进行离散化处理。
21、可选的,所述根据所有待选训练数据集的各子集的数据特征信息熵、数据标签信息熵以及特征与标签联合值信息熵,获取所有待选训练数据集的各子集的互信息指标包括:
22、遍历所有待选训练数据集的各子集,通过下式得到当前子集的互信息指标:
23、i(q)=h(dest)+h(src)-h(dest-src)
24、其中,i(q)为当前子集q的互信息指标,h(dest)为当前子集的数据特征信息熵,h(src)为当前子集的数据标签信息熵,h(dest-src)为当前子集的特征与标签联合值信息熵。
25、可选的,所述将互信息指标作为夏普利公式的评价指标,通过夏普利公式获取各待选训练数据集的夏普利值包括:
26、通过下式获取各待选训练数据集的夏普利值:
27、
28、其中,φi(i)为第i个待选训练数据集的夏普利值,n为待选训练数据集总数,s为所有待选训练数据集的子集,|s|为s中包含的待选训练数据集的个数,di为第i个待选训练数据集,dn为所有待选训练数据集的集合,i(s∪{di})为s∪{di}的互信息指标,i(s)为s的互信息指标。
29、本发明第二方面,提供一种图像分类方法,包括:
30、获取待分类图像,将待分类图像输入预设的图像分类模型中,得到待分类图像的图像分类结果;
31、其中,所述图像分类模型基于上述的图像分类模型训练数据选取方法选取的图像分类模型训练数据训练得到。
32、本发明第三方面,提供一种图像分类模型训练数据选取系统,包括:
33、数据获取模块,用于获取图像分类模型的各待选训练数据集,并获取各待选训练数据集中各训练数据的数据特征及数据标签;
34、信息熵计算模块,用于根据各待选训练数据集中各训练数据的数据特征及数据标签,获取所有待选训练数据集的各子集的数据特征信息熵、数据标签信息熵以及特征与标签联合值信息熵;
35、互信息计算模块,用于根据所有待选训练数据集的各子集的数据特征信息熵、数据标签信息熵以及特征与标签联合值信息熵,获取所有待选训练数据集的各子集的互信息指标;
36、夏普利值计算模块,用于将互信息指标作为夏普利公式的评价指标,通过夏普利公式获取各待选训练数据集的夏普利值;
37、选取模块,用于根据各待选训练数据集的夏普利值从大到小的顺序,选取前预设个待选训练数据集作为图像分类模型训练数据。
38、本发明第四方面,提供一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述图像分类模型训练数据选取方法的步骤。
39、本发明第五方面,提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述图像分类模型训练数据选取方法的步骤。
40、与现有技术相比,本发明具有以下有益效果:
41、本发明图像分类模型训练数据选取方法,通过获取各待选训练数据集中各训练数据的数据特征及数据标签,然后根据各待选训练数据集中各训练数据的数据特征及数据标签,获取所有待选训练数据集的各子集的数据特征信息熵、数据标签信息熵以及特征与标签联合值信息熵,进而计算所有待选训练数据集的各子集的互信息指标,并将互信息指标作为夏普利公式的评价指标,通过夏普利公式获取各待选训练数据集的夏普利值,最终根据各待选训练数据集的夏普利值从大到小的顺序,选取前预设个待选训练数据集作为图像分类模型训练数据。数据信息熵是和数据集尺寸成正比的,信息熵与数据的丰富程度是成正比的,数据集的数据信息熵是基于该数据集训练的分类模型的分类正确率的单调增函数,并且信息熵的计算是高效的,这些特点使得用基于信息熵的互信息评价指标代替基于模型训练的评估指标变得非常的合适,通过计算数据特征与标签之间的互信息指标来作为夏普利公式的评价指标,不需要重复地训练模型,计算互信息指标的时间很快,即使数据量很大,这样可以大大地减少成本。
- 还没有人留言评论。精彩留言会获得点赞!