强化学习模型微调方法、装置、计算机设备及存储介质与流程
本发明涉及模型微调方法,更具体地说是指强化学习模型微调方法、装置、计算机设备及存储介质。
背景技术:
1、近年来,多模态生成式大模型在科技领域取得了迅猛发展,为各行各业带来了革命性的突破。这些大模型结合了自然语言处理和计算机视觉等多种模态的信息,能够实现更加丰富多样的任务和应用。然而,当前所部署的生成式大模型主要以通用型为主,即通过在大规模公开数据集上的训练,使其具备了相对严密的逻辑推理能力和语言表达能力。尽管它们在逻辑推理和语言生成方面表现出色,却缺乏对于垂直领域的专业知识。为了使这些生成式大模型真正适用于垂直领域,通常需要进行领域微调。
2、目前多模态大模型常用的微调方法包括以下三种,第一种是将预训练的部分网络层固定,只微调某些特定的层,以便保留模型的通用特征;该方法可能会导致部分特征的丢失,尤其是那些需要根据特定任务微调的低级特征;选择哪些层应该被冻结,哪些应该被微调,需要一些试错和调整。不正确的层选择可能会导致模型性能下降或微调效果不佳。第二种是通过对生成式模型的prompt(机器学习预测优化,predictive optimization withmachine learning)参数进行调整来实现特定任务的微调。设计一个有效的prompt可能并不容易,特别是在涉及复杂领域知识或多样化任务的情况下。生成式模型在不同的初始化和微调设置下可能表现不稳定,某些prompt的微调结果可能在不同的试验中有所不同。第三种事引入低秩矩阵来近似大模型的高维结构,通过微调低秩矩阵来适应特定的任务,虽然低秩矩阵降低了微调的复杂度,但也引入来一些近似误差。
3、综上所述,现有的微调方法存在模型性能下降、垂直领域专业能力不足、设计困难、稳定性较差等问题。
4、因此,有必要设计一种新的方法,实现解决传统微调方法带来的性能下降、特征丢失、设计困难、稳定性较差等问题。
技术实现思路
1、本发明的目的在于克服现有技术的缺陷,提供强化学习模型微调方法、装置、计算机设备及存储介质。
2、为实现上述目的,本发明采用以下技术方案:强化学习模型微调方法,包括:
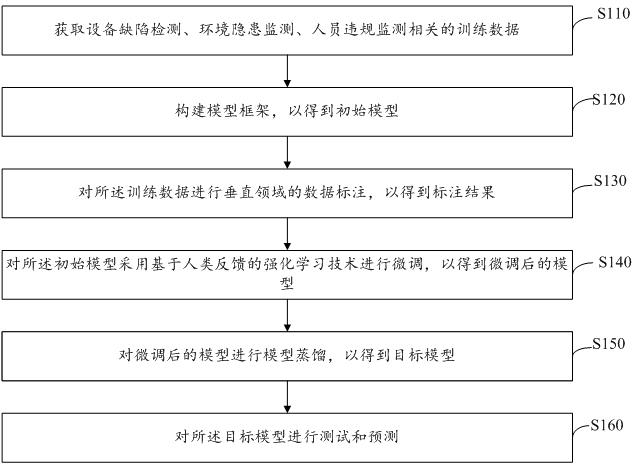
3、获取设备缺陷检测、环境隐患监测、人员违规监测相关的训练数据;
4、构建模型框架,以得到初始模型;
5、对所述训练数据进行垂直领域的数据标注,以得到标注结果;
6、对所述初始模型采用基于人类反馈的强化学习技术进行微调,以得到微调后的模型;
7、对微调后的模型进行模型蒸馏,以得到目标模型;
8、对所述目标模型进行测试和预测。
9、其进一步技术方案为:所述构建模型框架,以得到初始模型,包括:
10、确定视觉大模型;
11、确定语言大模型;
12、采用视觉特征的映射方式对所述视觉大模型的输出与所述语言大模型的输入进行对齐,以得到初始模型。
13、其进一步技术方案为:所述对所述训练数据进行垂直领域的数据标注,以得到标注结果,包括:
14、对所述训练数据中出现的设定目标进行目标框标注和多边形分割标注,以得到第一标注结果;
15、对所述训练数据图片进行描述性标注,以得到第二标注结果;
16、将所述第一标注结果以及所述第二标注结果组合形成标注结果。
17、其进一步技术方案为:所述对所述初始模型采用基于人类反馈的强化学习技术进行微调,以得到微调后的模型,包括:
18、采用所述标注结果对所述初始模型进行微调,以得到第一微调结果;
19、根据所述第一微调结果构建并训练奖励模型;
20、利用所述奖励模型所输出的标量奖励采用强化学习方式微调所述第一微调结果,以得到微调后的模型。
21、其进一步技术方案为:所述根据所述第一微调结果构建并训练奖励模型,包括:
22、获取从问题库中选择的问题,并使用所述第一微调结果输出多个答案;
23、对多个答案进行排序,以得到排序结果;
24、将所述第一微调结果中的最后一层结构修改为线性层,利用所述排序结果来进行反向传播训练修改后的第一微调结果,以得到奖励模型。
25、其进一步技术方案为:所述利用所述奖励模型所输出的标量奖励采用强化学习方式微调所述第一微调结果,以得到微调后的模型,包括:
26、利用所述奖励模型所输出的标量奖励采用ppo算法微调所述第一微调结果,以得到微调后的模型。
27、其进一步技术方案为:所述对微调后的模型进行模型蒸馏,以得到目标模型,包括:
28、将所述标注结果输入至初始模型中进行前向传递,输出的向量经过softmax处理,以得到软化后的类别概率;
29、将所述标注结果输入至微调后的模型,并输出向量升高与所述初始模型相同的温度后,经过softmax处理,并将得到的目标与软化后的类别概率进行kl散度计算,以得到第一损失值;
30、将所述标注结果输入至微调后的模型,输出向量,经过softmax处理,并将得到的目标与标注结果中的标注内容进行交叉熵计算,以得到第二损失值;
31、将微调后的模型的总损失函数确定为第一损失值与第二损失值的加权求和结果。
32、本发明还提供了强化学习模型微调装置,包括:
33、数据获取单元,用于获取设备缺陷检测、环境隐患监测、人员违规监测相关的训练数据;
34、初始模型构建单元,用于构建模型框架,以得到初始模型;
35、标注单元,用于对所述训练数据进行垂直领域的数据标注,以得到标注结果;
36、微调单元,用于对所述初始模型采用基于人类反馈的强化学习技术进行微调,以得到微调后的模型;
37、模型蒸馏单元,用于对微调后的模型进行模型蒸馏,以得到目标模型;
38、测试与预测单元,用于对所述目标模型进行测试和预测。
39、本发明还提供了一种计算机设备,所述计算机设备包括存储器及处理器,所述存储器上存储有计算机程序,所述处理器执行所述计算机程序时实现上述的方法。
40、本发明还提供了一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述的方法。
41、本发明与现有技术相比的有益效果是:本发明通过获取训练数据,并构建初始模型,对垂直领域的训练数据进行标注,并基于人类反馈的强化学习微调,可以让初始模型学习到垂直领域的专业知识,使得初始模型在垂直领域的专业性更强,输出的内容更符合设定的观点,此后,再引入知识蒸馏对微调后的模型进行处理,可以有效降低微调带来的模型性能下降问题,让微调后的模型学习到垂直领域的专业知识,同时保留初始模型的性能,实现解决传统微调方法带来的性能下降、特征丢失、设计困难、稳定性较差等问题。
42、下面结合附图和具体实施例对本发明作进一步描述。
技术特征:
1.强化学习模型微调方法,其特征在于,包括:
2.根据权利要求1所述的强化学习模型微调方法,其特征在于,所述构建模型框架,以得到初始模型,包括:
3.根据权利要求1所述的强化学习模型微调方法,其特征在于,所述对所述训练数据进行垂直领域的数据标注,以得到标注结果,包括:
4.根据权利要求1所述的强化学习模型微调方法,其特征在于,所述对所述初始模型采用基于人类反馈的强化学习技术进行微调,以得到微调后的模型,包括:
5.根据权利要求4所述的强化学习模型微调方法,其特征在于,所述根据所述第一微调结果构建并训练奖励模型,包括:
6.根据权利要求4所述的强化学习模型微调方法,其特征在于,所述利用所述奖励模型所输出的标量奖励采用强化学习方式微调所述第一微调结果,以得到微调后的模型,包括:
7.根据权利要求1所述的强化学习模型微调方法,其特征在于,所述对微调后的模型进行模型蒸馏,以得到目标模型,包括:
8.强化学习模型微调装置,其特征在于,包括:
9.一种计算机设备,其特征在于,所述计算机设备包括存储器及处理器,所述存储器上存储有计算机程序,所述处理器执行所述计算机程序时实现如权利要求1至7中任一项所述的方法。
10.一种存储介质,其特征在于,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述的方法。
技术总结
本发明实施例公开了强化学习模型微调方法、装置、计算机设备及存储介质。所述方法包括:获取设备缺陷检测、环境隐患监测、人员违规监测相关的训练数据;构建模型框架,以得到初始模型;对所述训练数据进行垂直领域的数据标注,以得到标注结果;对所述初始模型采用基于人类反馈的强化学习技术进行微调,以得到微调后的模型;对微调后的模型进行模型蒸馏,以得到目标模型;对所述目标模型进行测试和预测。通过实施本发明实施例的方法可实现解决传统微调方法带来的性能下降、特征丢失、设计困难、稳定性较差等问题。
技术研发人员:甘家旭,豆泽阳,蒋阳
受保护的技术使用者:珠高智能科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!