一种解答模型的训练方法与流程
【】本发明涉及自然语言处理,特别涉及一种解答模型的训练方法。
背景技术
0、
背景技术:
1、如何提高模型的逻辑推理能力,是自然语言处理领域中的一个重要任务,并长期受到学术界与工业界的广泛关注。近年来,随着深度学习的发展,一系列大语言模型在各类自然语言处理任务中不断取得令人瞩目的效果,但包括gpt系列在内的众多语言模型在算数、常识、符号推理等任务的表现效果上与人类仍有较大的差距。
2、在金融领域中,金融类的数学应用题目往往含有较多的专业术语,并涉及相关公式。尽管大模型在预训练阶段可能已经使用过包含这些信息的数据,但由于其接受的训练数据过于庞大,往往会产生信息遗忘的现象,从而对专业背景知识的理解能力存在不足,进而影响解题;同时大模型针对金融类的数学应用题目的推理能力也表现薄弱,单纯扩大模型的规模,并不能有效提高模型的推理能力。
技术实现思路
0、
技术实现要素:
1、为了解决上述问题,本发明提供一种解答模型的训练方法。
2、本发明为解决上述技术问题,提供如下的技术方案:一种解答模型的训练方法,包括以下步骤:
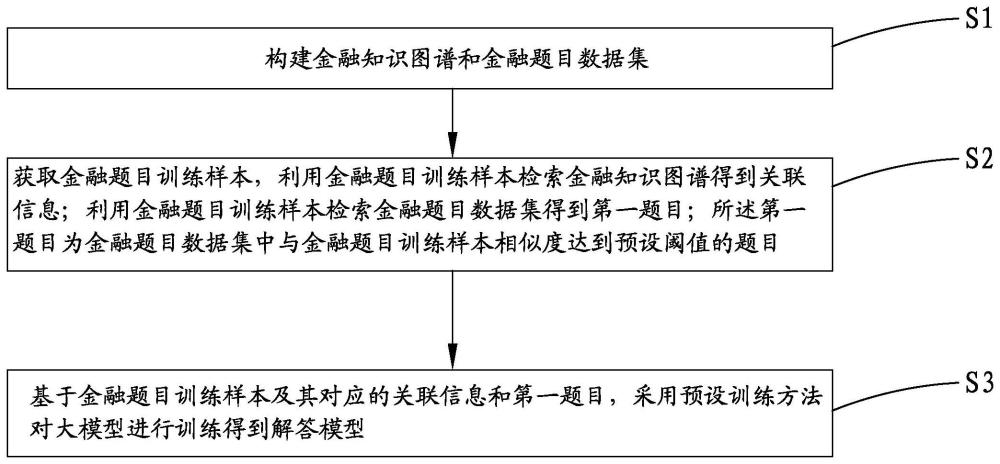
3、构建金融知识图谱和金融题目数据集;
4、获取金融题目训练样本,利用金融题目训练样本检索金融知识图谱得到关联信息;利用金融题目训练样本检索金融题目数据集得到第一题目;第一题目为金融题目数据集中与金融题目训练样本相似度达到预设阈值的题目;
5、基于金融题目训练样本及其对应的关联信息和第一题目,采用预设训练方法对大模型进行训练得到解答模型。
6、优选地,构建金融知识图谱具体包括以下步骤:
7、获取金融数据,对金融数据进行预设处理,得到实体数据及关系数据;
8、基于实体数据抽取其属性数据;
9、基于实体数据、关系数据和属性数据进行预设操作并导入图数据库,形成金融知识图谱。
10、优选地,获取金融数据,对金融数据进行预设处理,得到实体及其关系数据具体包括以下步骤:
11、获取金融数据;
12、使用预设命名实体识别模型与预设关系抽取模型对金融数据进行信息抽取,获得实体原始数据及关系原始数据;
13、对实体原始数据进行实体对齐、语义消歧操作得到实体数据,对关系原始数据进行语义消歧操作得到关系数据。
14、优选地,属性数据包括名词释义、概念属性、性质特点、关联公式中的一种或多种。
15、优选地,构建金融题目数据集具体包括以下步骤:
16、构建种子数据集;
17、基于种子数据集采用预设方法生成第二题目;
18、评判第二题目准确性,保存符合预设评判标准的第二题目形成金融题目数据集。
19、优选地,基于种子数据集采用预设方法生成第二题目具体包括以下步骤:
20、拓展种子数据集中题目的推理步骤形成纵向第二题目;
21、增添种子数据集中题目涉及知识点信息量形成横向第二题目。
22、优选地,第二题目包括题面、解题思路与答案。
23、优选地,利用金融题目训练样本检索金融知识图谱得到关联信息具体包括以下步骤:
24、使用预设命名实体识别模型抽取金融题目训练样本的关键实体;
25、基于关键实体利用金融知识图谱检索关键实体相邻实体与其属性数据;
26、根据预设判断标准将符合金融题目训练样本描述的关键实体相邻实体与其属性数据作为关联信息。
27、优选地,利用金融题目训练样本检索金融题目数据集得到第一题目具体包括以下步骤:
28、使用预设语义编码模型,将金融题目训练样本的题目编码为第一向量,将金融题目数据集中的题目编码为第二向量;
29、基于第一向量和第二向量根据预设方法对第二向量评分;
30、将评分满足预设标准的第二向量所对应的金融题目数据集的题目作为第一题目。
31、优选地,采用预设训练方法对大模型进行训练得到解答模型具体包括:大模型获取关联信息补充背景信息,并获取第一题目使用上下文学习和/或思维链策略进行训练得到解答模型。
32、与现有技术相比,本发明所提供的一种解答模型的训练方法,具有如下的有益效果:
33、1、本发明实施例中提供的一种解答模型的训练方法,构建金融知识图谱和金融题目数据集;获取金融题目训练样本,利用金融题目训练样本检索金融知识图谱和金融题目数据集得到关联信息和第一题目;第一题目为金融题目数据集中与金融题目训练样本相似度达到预设阈值的题目;基于金融题目训练样本及其对应的关联信息和第一题目,采用预设训练方法对大模型进行训练得到解答模型。构建金融知识图谱可以通过对金融文本等非结构化数据处理得到结构化数据,并进行处理得到金融知识图谱,能够为大模型提供金融常识以及相关的背景知识,辅助其理解金融计算应用题,可以缓解现有大模型在金融领域大量训练容易产生知识遗忘的问题。构建金融题目数据集,能够为大模型提供大量的相似题目进行对应训练,为大模型进行上下文学习和使用思维链技术奠定基础;利用金融题目训练样本检索金融知识图谱和金融题目数据集得到关联信息和第一题目,第一题目为金融题目数据集中与金融题目训练样本相似度达到预设阈值的题目;使得大模型可以在进行训练时将关联信息和第一题目同时输入,大模型可以学习相关金融常识背景知识,同时第一题目作为参考供大模型学习,采用上下文学习的模型训练方法,激发大模型的数学推理能力,使得大模型的推理能力有较大提升。
34、2、本发明实施例提供的构建金融知识图谱具体包括以下步骤:获取金融数据,对金融数据进行预设处理,得到实体数据及关系数据;基于实体数据抽取其属性数据;基于实体数据、关系数据和属性数据进行预设操作并导入图数据库,形成金融知识图谱。通过对金融数据进行处理,得到实体数据和对应的关系数据,使得非结构化数据可以被加工处理为结构化数据,提高了数据的利用效率。基于实体数据抽取其属性数据解决了面对金融数学应用题涉及到的知识具有较高的专业性,仅仅提供常见实体和关系很难提高模型效果的问题。基于实体数据、关系数据和属性数据进行预设操作并导入图数据库,形成金融知识图谱,可以为大模型提供金融常识以及相关的背景知识,帮助其理解金融计算应用题,提高了针对金融计算应用题的计算准确率,采用面向金融领域常识的知识图谱可以缓解现有大模型在金融领域大量训练容易产生知识遗忘的问题。
35、3、本发明实施例提供的获取金融数据,对金融数据进行预设处理,得到实体数据及关系数据具体包括以下步骤:获取金融数据;使用预设命名实体识别模型与预设关系抽取模型对金融数据进行信息抽取,获得实体原始数据及关系原始数据;对实体原始数据进行实体对齐、语义消歧操作得到实体数据,对关系原始数据进行语义消歧操作得到关系数据。使用预设命名实体识别模型与预设关系抽取模型对金融数据进行信息抽取,获得实体原始数据和关系原始数据具有自动化程度高,效率高的优势,进行实体对齐、语义消歧操作得到实体数据及关系数据,使得所得到的实体及其关系数据的准确性得到了保障,实体数据及关系数据具有较高的准确度,避免了由于实体数据及关系数据的不准确对于大模型的训练所造成的干扰。
36、4、本发明实施例提供的属性数据包括名词释义、概念属性、性质特点、关联公式中的一种或多种。面对金融数学应用题涉及到的知识具有较高的专业性,仅仅提供常见实体和关系很难提高模型效果,提供包括名词释义、概念属性、性质特点、关联公式中的一种或多种的属性数据能够为大模型的训练尽可能广泛的提供相关的背景信息供大模型学习,辅助其理解金融计算应用题。
37、5、本发明实施例提供的构建金融题目数据集具体包括以下步骤:构建种子数据集;基于种子数据集采用预设方法生成第二题目;评判第二题目准确性,保存符合预设评判标准的第二题目形成金融题目数据集。通过种子数据集采用预设方式裂变变形生成大量的第二题目,能够为大模型提供大量的相似题目进行对应训练,为大模型进行上下文学习和使用思维链技术奠定基础;评判第二题目准确性,保存符合预设评判标准的第二题目构建起大规模的金融题目数据集使得金融题目数据集以足够的数量、高准确度契合大模型训练的要求。
38、6、本发明实施例提供的基于种子数据集采用预设方法生成第二题目具体包括以下步骤:拓展种子数据集中题目的推理步骤形成纵向第二题目;增添种子数据集中题目涉及知识点信息量形成横向第二题目。通过拓展题目所需的推理步骤,使解题过程更加困难,通过拓展题目涉及的知识点,使题目蕴含更多的信息,使得第二题目的纵向难度和横向难度均有所增加,用这样的第二题目形成金融题目数据集能够进一步激发大模型的数学推理能力,得到推理能力更强的解答模型。
39、7、本发明实施例提供的第二题目包括题面、解题思路与答案,包含题面、解题思路与答案的第二题目相较于单纯只包含题目问题能够提供更加丰富详细的信息供大模型进行学习和逻辑推理。
40、8、本发明实施例提供的利用金融题目训练样本检索金融知识图谱得到关联信息具体包括以下步骤:使用预设命名实体识别模型抽取金融题目训练样本的关键实体;基于关键实体利用金融知识图谱检索关键实体相邻实体与其属性数据;根据预设判断标准将符合金融题目训练样本描述的关键实体相邻实体与其属性数据作为关联信息。通过使用预设命名实体识别模型抽取金融题目训练样本的关键实体,并以此检索知识图谱,得到关键实体相邻实体与其属性数据作为关联信息,能够为大模型提供较为精准的相关金融常识以及背景知识,辅助其理解金融计算应用题,可以缓解现有大模型在金融领域大量训练容易产生知识遗忘的问题。
41、9、本发明实施例提供的利用金融题目训练样本检索金融题目数据集得到第一题目具体包括以下步骤:使用预设语义编码模型,将金融题目训练样本的题目编码为第一向量,将金融题目数据集中的题目编码为第二向量;基于第一向量和第二向量根据预设方法对第二向量评分;将评分满足预设标准的第二向量所对应的金融题目数据集的题目作为第一题目。使用向量检索能够实现快速检索,并且较为精准的检索到与金融题目训练样本的题目较为相似的题目,作为第一题目以供大模型进行训练。
42、10、本发明实施例提供的采用预设训练方法对大模型进行训练得到解答模型具体包括:大模型获取关联信息补充背景信息,并获取第一题目使用上下文学习和/或思维链策略进行训练得到解答模型。大模型通过关联信息补充背景信息,通过第一题目使用上下文学习和/或思维链策略进行训练,并促使大模型输出完整的解题过程,提高最终结果的正确率,有效提高大模型对金融领域专业知识的掌握程度并获得了良好的推理能力。
- 还没有人留言评论。精彩留言会获得点赞!