一种基于人工智能的信息存储管理系统的制作方法
本发明涉及语义识别,具体涉及一种基于人工智能的信息存储管理系统。
背景技术:
1、随着信息技术的普及,大量的文档、报告、电子邮件等以文本形式存在。这些文本信息需要被有效地存储和管理,以提高工作效率和信息查找的便利性。但是大量的文本资料在进行存储时,将所有文本资料进行压缩和存储,不会区分文本资料中的重要内容和次要内容,对重要内容不进行提取,造成存储的内容冗余,杂乱,且占用大量内存,不便于信息的查找。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的一种基于人工智能的信息存储管理系统解决了现有信息存储管理系统对文本进行全部存储,存在存储的文本包含大量无用信息,占用大量内存的问题。
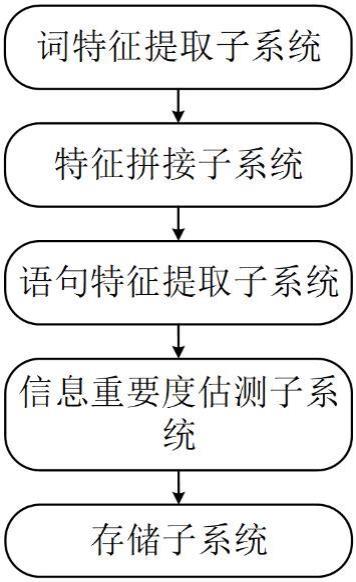
2、为了达到上述发明目的,本发明采用的技术方案为:一种基于人工智能的信息存储管理系统,包括:词特征提取子系统、特征拼接子系统、语句特征提取子系统、信息重要度估测子系统和存储子系统;
3、所述词特征提取子系统用于将文本进行拆分成词,基于词的向量,构建词矩阵,并提取词矩阵的词特征;
4、所述特征拼接子系统用于将一条语句对应的所有词特征进行拼接,得到词拼接特征;
5、所述语句特征提取子系统用于将词拼接特征进行提取特征,得到语句特征;
6、所述信息重要度估测子系统用于根据语句特征,计算出每条语句的信息重要度;
7、所述存储子系统用于根据信息重要度筛选出重要语句进行压缩和存储。
8、进一步地,所述词特征提取子系统包括:文本拆分单元、语句拆分单元、向量化处理单元、词矩阵构建单元和词特征提取单元;
9、所述文本拆分单元用于将文本拆分成多条语句;
10、所述语句拆分单元用于将每条语句拆分成多个词;
11、所述向量化处理单元用于将每个词进行向量化处理,得到词向量;
12、所述词矩阵构建单元用于将词向量构建为词矩阵;
13、所述词特征提取单元用于对词矩阵提取词特征。
14、上述进一步地方案的有益效果为:本发明中将文本拆分成词,并构建词矩阵,保障词信息的完整性。
15、进一步地,构建所述词矩阵的表达式为:v = vt v,其中,v为词矩阵,v为词向量,t为转置运算。
16、进一步地,所述词特征提取单元包括:第一卷积层、第二卷积层、第三卷积层、第一注意力模块、第二注意力模块、乘法器m1、乘法器m2和加法器a1;
17、所述第一卷积层的输入端作为词特征提取单元的输入端,其输出端与第二卷积层的输入端连接;所述第二卷积层的输出端分别与第一注意力模块的输入端、第二注意力模块的输入端、乘法器m1的第一输入端和乘法器m2的第一输入端连接;所述乘法器m1的第二输入端与第一注意力模块的输出端连接,其输出端与加法器a1的第一输入端连接;所述乘法器m2的第二输入端与第二注意力模块的输出端连接,其输出端与加法器a1的第二输入端连接;所述第三卷积层的输入端与加法器a1的输出端连接,其输出端作为词特征提取单元的输出端。
18、上述进一步地方案的有益效果为:本发明中设置两路注意力模块,分别计算出不同特征的注意力,实现对不同特征进行施加不同的关注度,避免部分特征被施加上过高的关注度。
19、进一步地,所述第一注意力模块的表达式为:
20、,
21、其中,z1为第一注意力模块的输出,softmax为归一化激活函数,为卷积核大小为的卷积层,relu为线性整流激活函数,maxpool为最大池化操作,x为第二卷积层输出的特征。
22、上述进一步地方案的有益效果为:本发明的第一注意力模块中通过最大池化操作提取出显著特征,第一注意力模块根据显著特征的情况,对第二卷积层输出的特征施加关注度。
23、进一步地,所述第二注意力模块的表达式为:
24、,
25、其中,z2为第二注意力模块的输出,softmax为归一化激活函数,为卷积核大小为的卷积层,relu为线性整流激活函数,avgpool为平均池化操作,x为第二卷积层输出的特征。
26、上述进一步地方案的有益效果为:本发明的第二注意力模块中通过平均池化操作提取出全局特征,第二注意力模块根据全局特征的情况,对第二卷积层输出的特征施加关注度。
27、进一步地,所述语句特征提取子系统包括:拼接层、第一lstm层、第二lstm层和第四卷积层;
28、所述拼接层的第一输入端作为语句特征提取子系统的输入端,其输出端与第一lstm层的输入端连接;所述第二lstm层的输入端与第一lstm层的输出端连接,其输出端分别与拼接层的第二输入端和第四卷积层的输入端连接,所述第四卷积层的输出端作为语句特征提取子系统的输出端。
29、上述进一步地方案的有益效果为:本发明中拼接层是用于将词拼接特征和第二lstm层历史输出特征输入第一lstm层,虽然lstm本身具备记忆性,但是该记忆性是在同一个lstm层的细胞单元间传递,考虑的是各个输入特征之间的关系,在语义识别中,各个语句之间也存在语义关系,因此,本发明将第二lstm层的输出输入到第一lstm层,进一步地加强语句特征提取子系统的记忆性。
30、进一步地,所述第一lstm层的一个细胞单元中遗忘门的表达式为:
31、,
32、输入门的表达式为:
33、,
34、,
35、状态更新门的表达式为:
36、,
37、输出门的表达式为:
38、,
39、,
40、其中,ft为遗忘门第t时刻的输出,ht-1为细胞单元第t-1时刻的输出,xt为细胞单元第t时刻输入的词拼接特征,yt-1为第二lstm层第t-1时刻的输出,wf为遗忘门的权重,bf为遗忘门的偏置,it为输入门第t时刻的第一输出,rt为输入门第t时刻的第二输出,wi为输入门的第一权重,wc为输入门的第二权重,bi为输入门的第一偏置,bc为输入门的第二偏置,ct-1为状态更新门第t-1时刻的输出,ct为状态更新门第t时刻的输出,ot为输出门第t时刻的输出,wo为输出门的权重,bo为输出门的偏置,ht为细胞单元第t时刻的输出,σ为sigmoid激活函数,tanh为双曲正切激活函数。
41、进一步地,所述信息重要度估测子系统的表达式为:
42、,
43、其中,y为语句的信息重要度,yi为第四卷积层的输出,wy为信息重要度估测子系统的权重,| |为取整运算,e为自然常数。
44、进一步地,所述存储子系统包括:信息筛选单元、编码单元和压缩存储单元;
45、所述信息筛选单元用于将信息重要度大于重要度阈值的语句作为重要语句;
46、所述编码单元用于将信息重要度编码成二进制数,与对应重要语句进行按位异或操作,得到编码数据:
47、所述压缩存储单元用于将编码数据进行压缩和存储。
48、上述进一步地方案的有益效果为:本发明将信息重要度低的语句丢弃,保留重要语句,在进行编码时,融合重要语句对应的信息重要度,编码过程相当于是对重要语句进行了加密,虽然加密方式一致,均为按位异或操作,但是加密的内容不相同,再对编码数据进行压缩和存储,能提高重要语句的保密性。
49、综上,本发明的有益效果为:本发明通过对文本进行拆分,构建每个词的词特征,将一条语句对应的所有词特征进行拼接,得到词拼接特征,通过词拼接特征来表达原本语句的内容,减少信息量,更好用于计算每条语句的信息重要度,通过信息重要度对文本中每条语句进行筛选,丢弃不重要的语句,减少无用内容的存储。
- 还没有人留言评论。精彩留言会获得点赞!