基于融合终端贡献度的量测数据动态联邦学习方法及系统
本发明涉及电力数据共享,具体而言,涉及基于融合终端贡献度的量测数据动态联邦学习方法及系统。
背景技术:
1、新型电力系统的数字赋能以数据作为核心要素,以数据流引领和优化能量流、业务流。量测系统贯穿电力系统发输配用各环节的数据采集,采集的量测数据是最基础和最重要的数据,潜能巨大。
2、结合配电网现状,多数量测数据属于机密数据。除本地分析外,一旦涉及数据间流通,就有可能面临数据泄漏的风险,若数据间不流通,就无法实现各方数据全面化电力分析。因此“数据不动模型动”的联邦学习框架逐渐成为有效保护数据隐私的多方合作训练模型新范式。而如何更好的让联邦学习在配电网场景落地应用,让更多拥有优质电力数据的融合终端参与联邦学习,需要对各参与方电力数据在联邦学习合作中的贡献度进行评估,并基于此给予激励。有效促进联邦学习在电力领域的良性发展,保护数据隐私。
3、各融合终端的电力数据价值评估存在主观性和业务性,较难获取数据标签统一、标签质量相同的完备测试集。因此,数据价值评估需要对是否具有良好测试集具备鲁棒性。
4、参与方电力数据在联邦学习合作中的贡献度评估不能仅仅通过数据价值来体现,否则拥有重合度高且数据量大的参与方贡献会被高估,而拥有少量互补数据,能够大大提高模型性能边际增益的参与方贡献会被低估,从而导致贡献评估不合理。
5、随着数字赋能的电力行业趋势,数据流通作为其方式会使得越来越多电力数据拥有方参与联邦合作以提升数据价值,这会使得联邦参与方组合数呈指数级增长,且联邦学习中数据价值评估需要重复训练,这使得所需的计算资源非常大;因此,急需设计一种新的基于联邦学习的配电网数据的动态量测技术,在不暴露各方数据的前提下,以解决数据孤岛以及隐私保护等技术问题。
技术实现思路
1、为了解决上述问题,本发明采用联邦学习这种新的机器学习范式,构建在配电网场景下的联邦学习流程及动态聚合策略,在不暴露各方数据的前提下达到解决数据孤岛以及隐私保护的目的
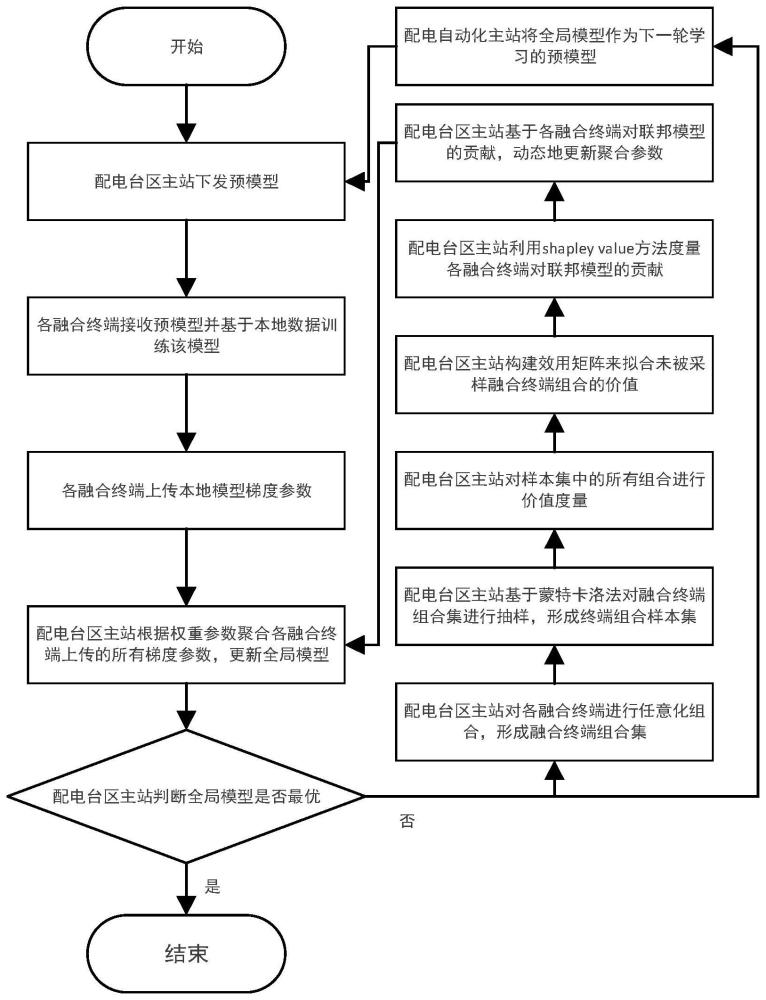
2、为了实现上述目的,本技术提供了基于融合终端贡献度的量测数据动态联邦学习方法,包括以下两个阶段:
3、面向配电网的联邦学习阶段:在保证各融合终端本地数据隐私安全的前提下,利用联邦学习框架,实现配电网的配电台区主站与各融合终端之间的数据价值流通;
4、联邦学习动态参数调整阶段:通过计算每轮次中融合终端的贡献大小,基于贡献加权下一轮联邦训练各融合终端的参与程度,对联邦学习动态参数进行调整。
5、优选地,在面向配电网的联邦学习阶段,利用联邦学习框架,实现配电网的配电台区主站与各融合终端之间的数据价值流通,具体包括以下过程:
6、参数广播:通过配电网的配电台区主站,将全局模型参数以广播的形式发往各融合终端;
7、本地训练:各融合终端利用本地数据集,对配电台区主站下发的预模型,进行训练并更新本地模型;
8、模型上传:各融合终端将该轮次模型梯度参数上传至配电台区主站,将配电台区主站接收到的梯度参数进行汇总,形成的梯度参数集;
9、模型聚合:通过配电台区主站,利用前一轮次计算得到的融合终端聚合权重参数,对梯度参数集进行聚合,得到聚合后该轮次的总体梯度参数,并更新全局模型。
10、优选地,在面向配电网的联邦学习阶段进行模型聚合的过程中,控制配电台区主站在聚合模型参数时的损失函数最小化,使得全局模型和各融合终端本地模型均满足精度要求,其中,当不满足精度要求时,则将全局模型下发至各融合终端作为下一轮迭代运算的预模型。
11、优选地,在联邦学习动态参数调整阶段,通过减小低贡献融合终端所影响到的模型参数比例,并增大高贡献融合终端所影响到的模型参数比例,对联邦学习动态参数进行调整。
12、优选地,在联邦学习动态参数调整阶段,对联邦学习动态参数的调整过程,具体包括如下过程:
13、构建融合终端样本组合集,根据前一时刻的聚合权重参数,对融合终端样本组合集的梯度参数进行聚合,通过对比总体梯度和样本中组合梯度的距离,来度量融合终端组合的数据在联合训练中的第一价值;
14、利用价值矩阵拟合未被采样融合终端组合的第二价值;
15、通过第一价值和第二价值,度量各融合终端对联邦模型的贡献,通过对度量的各融合终端贡献值进行归一化处理,得到更新后的聚合参数集。
16、优选地,在构建融合终端样本组合集的过程中,对各参与联邦学习的融合终端进行任意化组合,形成融合终端组合集;
17、通过配电台区主站,采用蒙特卡洛法对融合终端组合集中的元素进行抽样,构建融合终端样本组合集,其中,抽样过程用于降低空间和时间复杂度的同时实现价值拟合。
18、优选地,在对梯度参数进行聚合的过程中,通过配电台区主站,根据前一时刻的聚合权重参数,对融合终端组合样本的梯度参数进行聚合,并通过对比总体梯度和样本中组合梯度的距离,来度量融合终端组合的数据在联合训练中的第一价值,其中,距离采用余弦相似度来定义。
19、优选地,在获取第二价值的过程中,通过配电台区主站,采用基于因式分解的低秩矩阵,补全法来补全价值矩阵,利用补全后的价值矩阵拟合未被采样融合终端组合的第二价值。
20、优选地,在度量各融合终端对联邦模型的贡献的过程中,通过配电台区主站,采用基于夏普利博弈的方式,度量各融合终端对联邦模型的贡献,其中,在度量贡献时,满足以下融合终端贡献度评估公平性要求:
21、合理性:联邦学习过程中全部融合终端参与下数据总价值应完全分配给各融合终端;
22、对称性:若两个融合终端的数据在任意组合下,对联邦模型产生的相同的边际增益则认为有着相同的贡献;
23、零贡献:若某融合终端的数据对联邦模型无贡献,即在任意子集下的边际增益均为0时,该融合终端对联邦学习的贡献为0;
24、叠加性:当融合终端的数据价值函数为多个业务指标的线性叠加时,其贡献度评估结果也满足线性叠加。
25、本发明公开了基于融合终端贡献度的量测数据动态联邦学习系统,包括:
26、联邦学习模块,用于完成面向配电网的联邦学习阶段:在保证各融合终端本地数据隐私安全的前提下,利用联邦学习框架,实现配电网的配电台区主站与各融合终端之间的数据价值流通;
27、动态调整模块,用于完成联邦学习动态参数调整阶段:通过计算每轮次中融合终端的贡献大小,基于贡献加权下一轮联邦训练各融合终端的参与程度,对联邦学习动态参数进行调整。
28、本发明公开了以下技术效果:
29、本发明对各融合终端电力数据在联邦学习合作中的贡献度进行评估,并基于此给予激励,以促进联邦学习在电力领域的良性发展,保护数据隐私;
30、本发明提出了不依赖于测试集的数据价值评估策略,此策略通过度量各终端组合梯度与总体梯度之间的余弦相似度来定义此组合的数据价值,实现了在不依赖测试集前提下,较为准确、有效地反映数据对联邦模型的价值;
31、本发明通过各终端组合的价值矩阵因式分解补全策略来实现在约束范围内近似计算各终端组合价值的同时,极大的降低了运算开销;
32、本发明利用基于夏普利博弈(shapley game)的方式,通过遍历计算各终端组合估值并按照各组合概率加权计算普利值(shapley value),再将其定义为各融合终端的贡献,最终实现各终端贡献度评估的公平性;
33、本发明采用动态加权的聚合方式,通过基于各终端贡献度来动态调整聚合权重参数的方式,实现联邦模型的高效率收敛。
- 还没有人留言评论。精彩留言会获得点赞!