一种知识库检索方法和装置与流程
本申请属于计算机,具体涉及一种知识库检索方法和装置。
背景技术:
1、知识库匹配的效果与用户实际使用效果直接挂钩,是否能准确的匹配用户提问是核心评价指标。目前,知识库匹配算法大体分为两种类型,分别为基于语义的匹配与基于词频的匹配。其中,基于词频的匹配方法主要关注文本中词语的出现频率和分布。常见的词袋模型和tf-idf方法就属于基于词频的匹配。在这种方法中,文本被表示为词语的计数或权重向量,通过比较向量之间的相似性来判断文本之间的关系,在简单的文本匹配任务中可以有效,但通常无法捕捉到词语之间的语义关系。
2、基于语义的匹配方法关注文本之间的语义相似性,而不仅仅是词语的频率。基于词义的特征表示方法,如词向量(word embeddings)和预训练的语言模型(如bert、gpt等),可以捕捉词语之间的语义关系。在这种方法中,文本被表示为在语义空间中的向量,从而可以更好地理解词语的含义和上下文。这种方法能够处理复杂的语义关系和上下文信息,在许多任务中表现出色。
3、在大多数通用场景下,基于语义的匹配方法表显优于基于词频的匹配方法,但是其在长短文匹配上或特定行业的情况下也存在表显不足的问题。尤其是在行业领域中,往往有的特定词语的出现代表着某种产品或者与其他词语不同的意义。以用户咨询问题场景举例,用户问了产品a的使用问题,其中问题的描述与其他产品的问题描述非常相似的情况,可能会导致最终的结果并不是用户想要的结果。
4、申请内容
5、本申请实施例的目的是提供一种知识库检索方法和装置,以解决现有技术无法准确匹配用户提问的缺陷。
6、为了解决上述技术问题,本申请是这样实现的:
7、第一方面,提供了一种知识库检索方法,包括以下步骤:
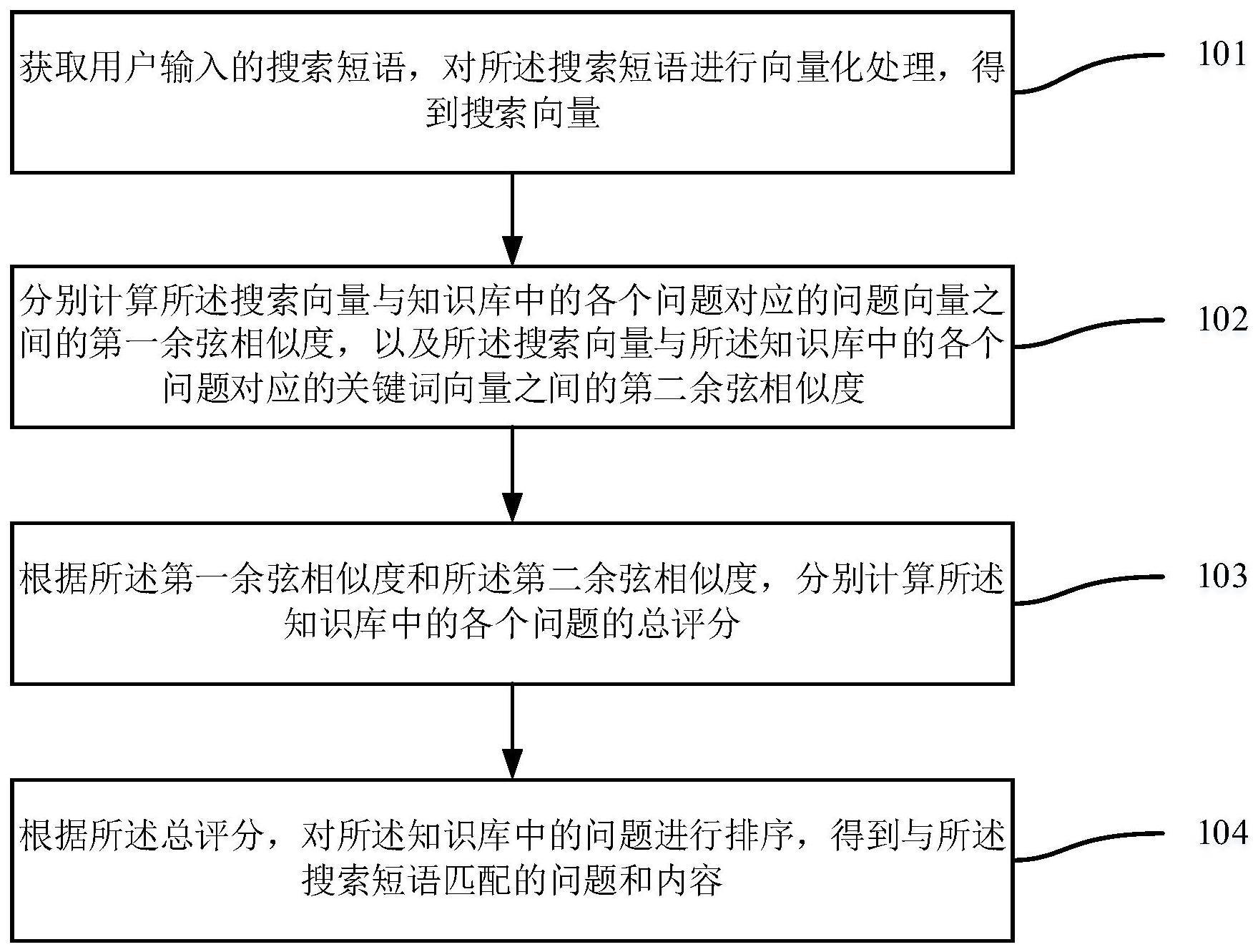
8、获取用户输入的搜索短语,对所述搜索短语进行向量化处理,得到搜索向量;
9、分别计算所述搜索向量与知识库中的各个问题对应的问题向量之间的第一余弦相似度,以及所述搜索向量与所述知识库中的各个问题对应的关键词向量之间的第二余弦相似度;
10、根据所述第一余弦相似度和所述第二余弦相似度,分别计算所述知识库中的各个问题的总评分;
11、根据所述总评分,对所述知识库中的问题进行排序,得到与所述搜索短语匹配的问题和内容。
12、第二方面,提供了一种一种知识库检索装置,包括:
13、获取模块,用于获取用户输入的搜索短语,对所述搜索短语进行向量化处理,得到搜索向量;
14、第一计算模块,用于分别计算所述搜索向量与知识库中的各个问题对应的问题向量之间的第一余弦相似度,以及所述搜索向量与所述知识库中的各个问题对应的关键词向量之间的第二余弦相似度;
15、第二计算模块,用于根据所述第一余弦相似度和所述第二余弦相似度,分别计算所述知识库中的各个问题的总评分;
16、排序模块,用于根据所述总评分,对所述知识库中的问题进行排序,得到与所述搜索短语匹配的问题和内容。
17、本申请实施例通过维护问题向量和关键词向量,结合语义匹配和词频匹配,能够解决由于单种匹配造成的识别较低、识别不准,以及语义和语序匹配错误的问题,从而优化检索效果。
技术实现思路
技术特征:
1.一种知识库检索方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,所述分别计算所述搜索向量与知识库中的各个问题对应的问题向量之间的第一余弦相似度,以及所述搜索向量与所述知识库中的各个问题对应的关键词向量之间的第二余弦相似度,具体包括:
3.根据权利要求2所述的方法,其特征在于,所述获取用户输入的搜索短语,对所述搜索短语进行向量化处理,得到搜索向量之前,还包括:
4.根据权利要求2所述的方法,其特征在于,所述获取用户输入的搜索短语,对所述搜索短语进行向量化处理,得到搜索向量之前,还包括:
5.根据权利要求1所述的方法,其特征在于,所述根据所述第一余弦相似度和所述第二余弦相似度,分别计算所述知识库中的各个问题的总评分,具体包括:
6.一种知识库检索装置,其特征在于,包括:
7.根据权利要求6所述的装置,其特征在于,
8.根据权利要求7所述的装置,其特征在于,还包括:
9.根据权利要求7所述的装置,其特征在于,还包括:
10.根据权利要求6所述的装置,其特征在于,
技术总结
本申请实施例公开了一种知识库检索方法和装置,该方法包括以下步骤:获取用户输入的搜索短语,对搜索短语进行向量化处理,得到搜索向量;分别计算搜索向量与知识库中的各个问题对应的问题向量之间的第一余弦相似度,以及搜索向量与知识库中的各个问题对应的关键词向量之间的第二余弦相似度;根据第一余弦相似度和第二余弦相似度,分别计算知识库中的各个问题的总评分;根据总评分,对知识库中的问题进行排序,得到与所述搜索短语匹配的问题和内容。本申请实施例通过维护问题向量和关键词向量,结合语义匹配和词频匹配,能够解决由于单种匹配造成的识别较低、识别不准,以及语义和语序匹配错误的问题,从而优化检索效果。
技术研发人员:李戈
受保护的技术使用者:北京百望慧眼数据科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!