一种融合中文词性信息和相互学习的短文本分类方法
本发明涉及中文短文本分类领域,尤其涉及一种融合中文词性信息和相互学习的短文本分类方法。
背景技术:
1、在互联网飞速发展的今天,如何快速的从网上海量的信息中获取所需要的信息,变得尤为重要。在浏览海量信息时,标题信息是判别该网页与用户需求相关度的重要依据。然而,标题分类作为短文本分类的一个重要分支,存在篇幅较短,信息量偏少等问题。因此,短文本分类模型仍需要进行更深入地研究与探索。
2、短文本分类是一个高度复杂的计算过程,因为计算机无法识别文字信息,因此需要将文字信息转化为向量模式才能进行计算。同时,因为短文本中信息少,利用相互学习的方式,使得单个模型能够获取其他更优模型的概率分布,以此来扩大模型的信息量。本发明选择使用bert神经网络作为相互学习中的两个学生网络,bert是google在2018年提出的一种预训练语言模型。该模型基于transformer模型的encoder部分,其不仅可以作为预训练模型,同时可以用于处理文本分类等自然语言处理任务。bert在提出之后便成功地在11项nlp任务中取得优异的成绩,由此可以看出bert在自然语言处理领域有着较高的性能,适合于工程应用。为弥补短文本信息量偏少的缺陷,本发明使用两个学生网络交互学习,其中一个网络仅使用常规的字向量信息,另一个网络融合使用字向量信息和词性信息,并集成kl和js两种散度构造模型的损失评价函数。
技术实现思路
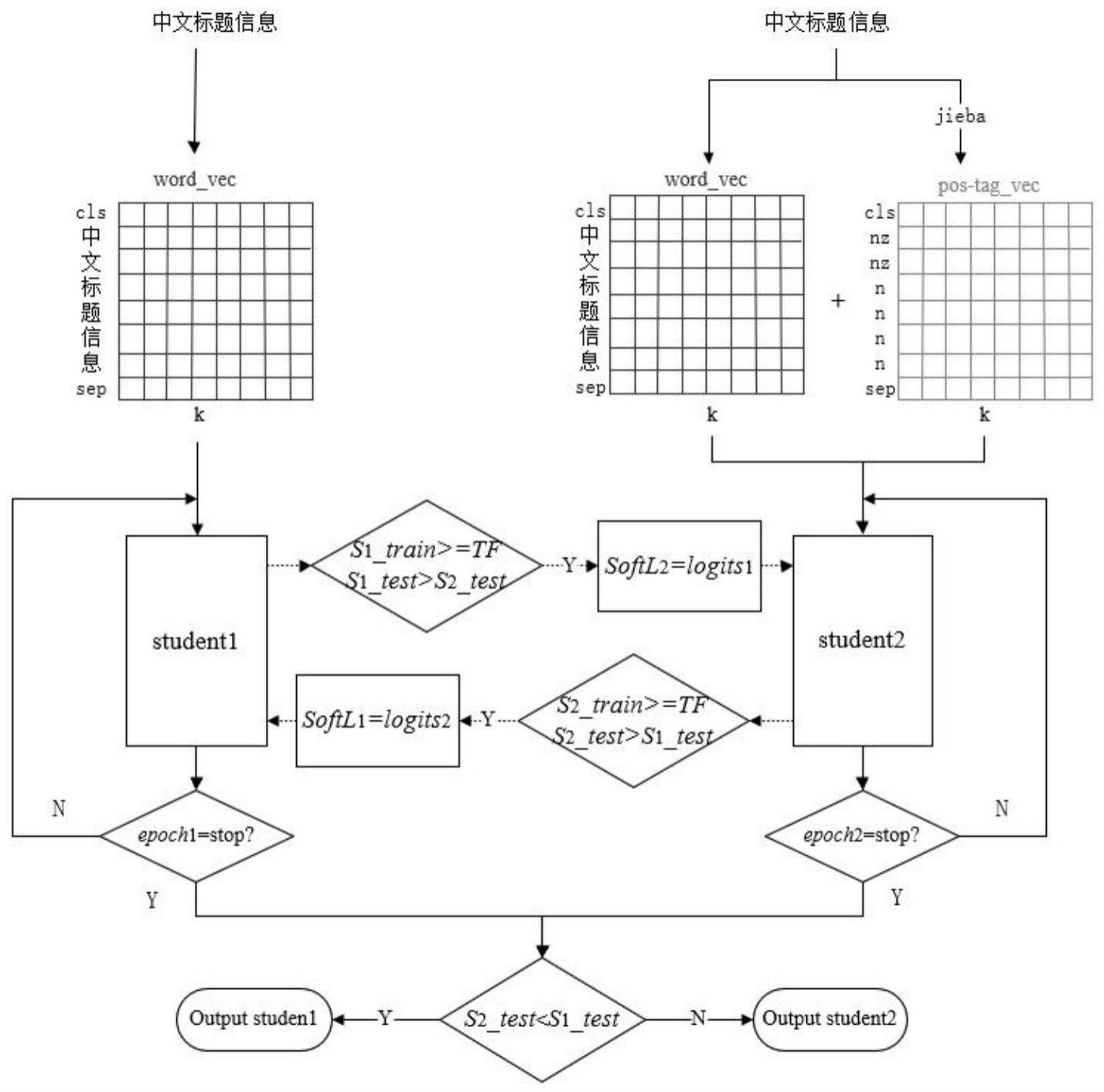
1、本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种融合中文词性信息和相互学习的短文本分类方法,算法包含一个仅使用字向量信息的bert和一个融合字向量信息和词性信息的bert,引入tf控制两个bert间的信息传递,并集成kl和js两种散度构造模型的损失评价函数。
2、本发明解决其技术问题所采用的技术方案是:
3、本发明提供一种融合中文词性信息和相互学习的短文本分类方法,该方法包括以下步骤:
4、s1、确定bert神经网络的参数,包括:transformer block个数,字/词性向量维度和批次数;
5、s2、初始化超参数,包括:学生网络θ1,t和θ2,t各层初始值,学习率lr,传输标志tf;初始化两个学生网络的训练集结果分别为x1=0和x2=0,测试结果为y1=0和y2=0;学生网络θ1,t和θ2,t软标签softl1和softl2为none;学生网络θ1,t和θ2,t预测的概率分布s1和s2为none;
6、s3、比较学生网络θ2,t的训练结果x2是否大于等于tf,同时学生网络θ2,t的测试结果y2是否大于学生网络θ1,t的测试结果y1,如果满足条件则更新softl1为s2;
7、s4、将输入的中文短文本转化为向量形式,并在句向量前后添加[cls]和[sep]标签对应的标签向量,得到学生网络θ1,t的输入向量;
8、s5、对输入向量添加位置信息;
9、s6、使用bert神经网络进行计算,得到输出向量output;
10、s7、对输出向量output进行平均池化,将output从高维度转化为1维行向量的形式,得到平均池化后的句向量p_output;
11、s8、对p_output进行线性变换,线性变换后得到lp向量;
12、s9、使用tanh函数对线性变换得到的lp向量中的神经元进行激活,得到最终的句向量表示sentence_vec;
13、s10、对最终得到的句向量进行线性变换,将句向量从k维向量转化为与标签类别个数相同维数的logits向量;
14、s11、使用softmax函数进行归一化,得到长度为l的概率分布s,以此作为分类依据;
15、s12、采用kl散度作为硬损失指标衡量硬标签和预测值之间的匹配度,采用js散度作为软损失指标衡量软标签和预测值之间的匹配度,并计算完整的损失函数,
16、s13、依照获得maf1分数作为评价指标;
17、s14、使用maf1分数的公式计算本轮次训练集train_score和测试集结果test_socre;
18、s15、使用adamw优化器对θ1,t的参数进行优化;
19、s16、更新学生网络θ1,t的预测概率分布s1、训练集结果x1和测试集结果y1;
20、s17、比较学生网络θ1,t+1的训练结果x1是否大于等于tf,同时学生网络θ1,t+1的测试集结果y1是否大于学生网络θ2,t的测试集结果y2;如果满足条件则更新softl1为s1;
21、s18、将输入的中文短文本将转化为向量形式,得到学生网络θ1,t的输入向量;
22、s19、将输入向量input作为输入,重复步骤s4到s14的工作;并使用adamw优化器对θ2,t的参数进行优化;
23、s20、更新学生网络θ2,t的预测概率分布s2、训练集结果x2和测试集结果y2;
24、s21、轮次t=t+1,若没到停止轮次,返回s3继续;若到停止轮次,则停止循环,输出分类结果。
25、进一步地,本发明的所述步骤s4的方法包括:
26、得到学生网络θ1,t的输入向量为:
27、
28、input=input_bert
29、其中,s_len表示句子长度,w1,w2,…,ws_len表示句子中每个字所对应的字向量,表示句子中第一个词的词向量,表示句子中最后一个词的词向量。
30、进一步地,本发明的所述步骤s5的方法包括:
31、首先根据位置公式初始化位置信息:
32、
33、其中,wp表示字向量所在的位置,k表示字向量的维度,n表示当前所在维度;将字向量所在的位置代入位置信息公式,得到位置变量为:
34、
35、t_input=input+positionals
36、其中,pos1,pos2,…,poss_len+2表示每个位置对应的位置向量。
37、进一步地,本发明的所述步骤s6的方法包括:
38、使用bert神经网络进行计算,得到输出向量output:
39、
40、o[cls],o[sep],on∈r1×k,n=1,...,s_len
41、其中,s_len表示句子长度,o1,o2,…,os_len表示句子中每个字经过模型运算后得到的字向量,和分别表示句子中第一个词和最后一个词经过模型运算后得到的词向量。
42、所述步骤s7的方法包括:
43、平均池化后的句向量p_output表示为:
44、p_output=meanpool(output),
45、p_output∈r1×k
46、所述步骤s8的方法包括:
47、对p_output进行线性变换,线性变换后得到的lp向量表示为:
48、lp=p_output·wlinear_vect+biaslinear_vec,
49、lp∈r1×k,wlinear_vec∈rk×k,biaslinear_vec∈r1×k
50、其中,wlinear_vec表示权重矩阵;biaslinear_vec表示偏置。
51、进一步地,本发明的所述步骤s9的方法包括:
52、tanh函数计算方法如下:
53、
54、sentence_vec表示为:
55、sentence_vec=[tanh(xi)],
56、sentence_vec∈r1×k,i=1,2,...,k
57、其中,xi表示lp向量中的所有神经元,sentence_vec即为最终得到的句向量;
58、所述步骤s10的方法包括:
59、将句向量从k维向量转化为与标签类别个数相同维数的logits向量,logits表示为:
60、logits=sentence_vec·wlogitst+biaslogits,
61、logits∈r1×l,w∈rl×k,biaslogits∈r1×k
62、其中l表示标签类别个数,k表示字向量维度;
63、所述步骤s11的方法包括:
64、某一类别概率的softmax激活函数计算方法为:
65、
66、则,经过模型运算得到的概率分布为:
67、s=[s1,s2,...,sl]
68、其中,s表示得到的概率分布,s1,s2…sl表示每一类的概率,在概率分布s中最大值所对应的类别即为模型预测的类别。
69、进一步地,本发明的所述步骤s12的方法包括:
70、采用kl散度作为硬损失指标衡量硬标签和预测值之间的匹配度,kl散度表示为
71、
72、其中,p代表标签实际概率分布,q为模型预测的概率分布;设hardl为标签实际概率分布,即hard label;s为经过模型计算得到概率分布,si表示该输入为第i个类别的概率;硬损失hardloss的计算表示为:
73、
74、采用js散度作为软损失指标衡量软标签和预测值之间的匹配度,js散度表示为:
75、
76、其中,p代表标签实际概率分布,q为模型预测的概率分布;设softl为软标签的概率分布;s为经过模型计算得到概率分布;软损失softloss的计算表示为:
77、
78、因此,完整的损失函数表示为:
79、
80、其中,n代表对应的学生网络θ1,t或θ2,t;两个学生网络使用同一数据集,因此两个网络的hardl一致。
81、进一步地,本发明的所述步骤s13的方法包括:
82、maf1分数的计算方法为:
83、
84、
85、
86、其中,tp表示把正例预测为正例的样本,tn表示把负例预测为负例的样本,fn表示把正例预测为负例的样本,fp表示把负例预测为正例的样本。
87、进一步地,本发明的所述步骤s15的方法包括:
88、使用adamw优化器对θ1,t的参数进行优化:
89、θ1,t+1=adamw(θ1,t)
90、所述步骤s16的方法包括:
91、更新学生网络θ1,t的预测概率分布s1、训练集结果x1和测试集结果y1,公式表示如为:
92、s1=s,
93、x1=train_socre,
94、y1=test_score。
95、进一步地,本发明的所述步骤s18的方法包括:
96、将输入的中文短文本将转化为向量形式,得到学生网络θ1,t的输入向量:
97、
98、
99、input=input_word+input_pos,
100、w[cls],w[sep],wn∈r1×k,p[cls],p[sep],pn∈r1×k,n=1,...,s_len。
101、进一步地,本发明的所述步骤s19的方法包括:
102、将input作为输入,重复步骤s4到s14的工作,并使用adamw优化器对θ2,t的参数进行优化:
103、θ2,t+1=adamw(θ2,t)
104、所述步骤s20的方法包括:
105、更新学生网络θ2,t的预测概率分布s2、训练集结果x2和测试集结果y2,公式表示如为:
106、s2=s,
107、x2=train_socre,
108、y2=test_score。
109、本发明产生的有益效果是:
110、本发明的方法包含一个使用字向量信息的bert,保证了bert模型的基础优势,增加了一个融合字向量信息和词性信息的bert,引入tf控制两个bert间的信息传递,增加了额外的信息,一定程度上弥补了短文本信息量偏少的不足,并集成kl和js两种散度构造模型的损失评价函数,既考虑了js散度的对称性特点,也考虑了kl散度的非对称性特点。本发明方法具有模型精度高、可拓展性强的特点,在短文本分类研究中将是一种切实可行的方法。
- 还没有人留言评论。精彩留言会获得点赞!