基于自适应融合的多模态虚假新闻检测方法
本发明涉及自然语言处理和计算机视觉的交叉领域,尤其涉及一种基于自适应融合的多模态虚假新闻检测方法。
背景技术:
1、多模态内容可以增加虚假新闻的可信度和传播力,也给检测带来了更大的挑战,当前的多模态虚假新闻检测面临着以下挑战:
2、(1)多模态线索的多样性。不同类型的多模态虚假新闻检测中,图片和文本之间的关系可能有所不同,例如图文不一致、图文相互增强、图片中嵌入文本等,这些关系提供了不同的检测线索,需要设计合适的模型来捕捉和融合。
3、(2)多模态数据的异构性。图片和文本是两种不同的数据类型,它们在语义层次上有着很大的差异。例如,图像中的物体识别和文本中的物体识别是两种不同的任务,它们需要各自的模型来处理。如何有效地将图片和文本转换到一个公共的语义空间并进行有效地推理,这是一个难点。
4、(3)多模态数据的融合。不同模态的数据可能有不同的格式、分布、维度和密度,这给数据的表示、对齐和融合带来了挑战。例如文本是离散的符号序列,而图像是连续的像素矩阵,如何将它们转换到一个公共的语义空间并保持各自的特征和关系,这是一个挑战。
5、因此,针对上述问题,提出一种基于自适应融合的多模态虚假新闻检测方法来解决上述问题。
技术实现思路
1、本发明针对现有技术的不足,提出了一种基于自适应融合的多模态虚假新闻检测方法,该发明可以,同时。
2、本发明解决技术问题的技术方案为:
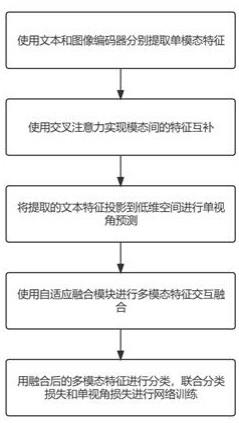
3、一种基于自适应融合的多模态虚假新闻检测方法,包括以下步骤:
4、s1.使用文本和图像编码器分别提取单模态特征,将文本、图像分别输入编码器;
5、对于文本,采用预训练模型bert作为文本编码器,英文和中文语言分别使用英文预训练模型bert-base-uncased和中文预训练模型bert-base-chinese,提取了bert的12个隐藏层特征并相加起来获得文本的特征表示;
6、对于图像,使用预训练模型resnet50来提取图像的语义特征,使用第四个block块获得图像的特征表示,将其特征调整为3维,与文本特征维度保持一致;
7、s2.使用交叉注意力实现模态间的特征互补,通过多模态预训练模型vilbert实现模态间的特征互补,将新闻的文本和视觉特征进行有效融合,解决多模态特征之间的异构性;
8、s3.将提取的文本特征投影到低维空间进行单视角预测,将经过文本编码器得到的文本表示投影到低维空间,并与真实标签做损失得到文本分类损失和单视角分类决策的影响;
9、s4.使用自适应融合模块进行多模态特征交互融合;
10、将提取到的文本和图像特征表示作为输入,在空间维度上进行压缩,得到一个一维向量,使用激活函数来计算每个通道的权重,对于文本该权重表示每个单词对于整个文本的重要程度,对于图像该权重表示的是每块区域对于整个图像的重要程度,通过加权求和得到文本和图像的全局表示,即文本增强特征和图像增强特征;
11、将文本增强特征和图像增强特征特征相乘得到视觉融合特征,表示文本信息在视觉空间中的投影,然后对视觉融合特征进行归一化和自适应平均操作得到最终的视觉融合向量;
12、将图像增强特征和文本特征相乘得到文本融合特征,表示视觉信息在文本空间中的投影,然后对文本融合特征进行归一化和自适应平均池化操作,得到最终的文本融合向量;
13、将文本融合向量和视觉融合向量进行拼接,得到融合后的多模态特征,此时多模态通道变为单模态通道的两倍,将融合后的多模态特征送入两个门控单元来调节向量的信息流动;
14、利用通道信息来强调多模态信息特征并抑制多模态融合后的噪声影响,具体是将经过门控单元调节后的多模态向量分为视觉注意力向量和文本注意力向量分别与原始的编码向量相加,并使用将多模态特征投影到相同的维度后拼接,得到最终的多模态特征融合向量;
15、s5.利用融合后的多模态特征进行分类,联合分类损失和单视角损失进行网络训练;使用交叉熵函数计算分类损失,通过放大分类的损失缓解类别不平衡带来的影响,并联合文本单视角的分类损失,使分类器根据网络输出的特征向量,将其映射为一个概率分布,用于表示该新闻属于每个分类的可能性。
16、s1中使用的公式如下:
17、t={t1,...tm}=bert(w),
18、v={v1,...vn}=resnet50(i),
19、其中,w表示新闻对应的文本内容,t表示12层隐藏层特征拼接后每个单词的语义表示,m表示文本中单词的数量,i表示新闻对应的图像内容,v表示经过resnet50预训练模型提取的图像语义特征,n表示图像的嵌入维度,v表示图像,t表示文本。
20、s2具体如下:
21、给定图像v和文本t表示,在标准transformer模型中计算q、k、v,每个模态的k、v作为输入传递给另一个transformer的多头注意力块,该多头注意力块为每个模态生成注意力池化特征,即在视觉流中执行图像对文本的注意力,在文本流中执行文本对图像的注意力,transformer块的其余部分像以前一样继续进行,包括带有初始表示的残差层产生多模态特征;
22、s2中使用的公式如下:
23、
24、
25、input1和input2表示两种输入的模态,q、k、v分别表示某个模态的query查询、key键、value值,hi表示经过特征互补后的特征表示,wiq、wik、wiv表示权重矩阵,dh表示嵌入维度,softmax表示归一化函数,qinput1表示文本的query值,qinput2表示图像的query值,kinput1表示文本的key值,kinput2表示图像的key值,vinput1表示文本的value值,vinput2表示图像的value值。
26、s3具体如下:使用卷积层进行降维,使用bn归一化层用于归一化特征分布,使用relu激活函数增强网络的表达能力,接着将第二维和第三维进行展平操作,再加一层bn层,用dropout丢弃法来防止过拟合,最终得到两维的文本特征表示,将其使用分类器提前进行分类与标签做损失。
27、s4中使用的公式如下:
28、
29、vf=average(normlize(txt_pool⊙v))
30、
31、tf=average(normlize(vis_pool⊙t))
32、⊙表示逐元素乘法,.表示点积相乘运算,t表示文本的编码特征,v表示图像的编码特征,i表示第i个文本编码向量,j表示第j个图像编码向量,l表示新闻文本的总数,txt_pool表示加权求和后的文本全局特征,vf表示文本信息在视觉空间的投影向量,average表示自适应平均池化,normlize表示归一化,linear表示线性操作,conv表示卷积网络,vis_pool表示加权求和后的视觉全局特征;
33、c=concat(vf,tf)
34、d=σ{conv1d(γ(β(conv1d(c))))}
35、c表示图像和文本特征拼接后的融合特征,σ表示softmax激活函数,γ表示线性激活函数relu,β表示归一化,d表示自适应融合后的多模态向量,conv1d表示1d卷积网络,tf表示视觉信息在文本空间上的投影向量;
36、at=tk⊙dk
37、av=vk⊙dk-2k
38、k表示嵌入维度,k取值256,保持文本和图像的嵌入维度一致;at表示文本信息的概率分布,av表示视觉信息的概率分布,tk表示维度为k的文本特征编码,vk表示维度为k的图像特征编码,dk表示自适应融合的文本向量,dk-2k表示自适应融合的视觉向量;
39、ft=tk.(1+at)
40、fv=vk.(1+av)
41、ft表示文本模态,fv表示图像模态。
42、s5中使用的公式如下:
43、
44、
45、表示交叉熵函数,y表示真实标签,表示预测得到的值,表示特征融合之后的分类损失,表示根据文本单模态分类的损失,表示总的损失函数。
46、本发明还提供了一种基于自适应融合的多模态虚假新闻检测系统,包括以下模块:
47、单模态特征提取模块,用于构建对新闻中文本和图像的特征提取;
48、多模态特征互补模块,使用transformer多头注意力块,融合文本和图像的特征;
49、单视角预测模块,将提取的文本特征投影到低维空间进行特征表示,将其使用分类器提前进行分类与标签做损失,以研究文本特征对决策的影响;
50、多模态特征交互融合模块,将文本增强特征和初始视觉特征进行点积运算并进行归一化,对视觉融合特征进行自适应平均池化操作得到最终的视觉融合向量;将图像增强特征和文本特征相乘并进行归一化对文本融合特征进行自适应平均操作,得到最终的文本融合向量;文本融合向量和视觉融合向量进行拼接,得到融合后的多模态特征;
51、训练模块,将经过自适应融合模块的多模态特征作为最后的分类特征,并使用交叉熵函数计算分类损失。
52、本发明还涉及一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现基于自适应融合的多模态虚假新闻检测方法。
53、本发明还涉及一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现基于自适应融合的多模态虚假新闻检测方法。
54、上述技术方案具有如下优点或有益效果:
55、1)针对文本特征提取问题,本发明融合bert12层隐藏层特征,利用不同层次的语言信息来丰富最终的表征,使模型获得更全面的文本表征信息;
56、2)引用自适应融合模块解决了多模态特征融合的问题;
57、3)针对多模态融合带来的噪声影响,本发明采用文本单模态预测的方式缓解噪声对分类结果的影响;
58、4)针对数据集类别不平衡的问题,增大分类损失来增加少样本的权重。
- 还没有人留言评论。精彩留言会获得点赞!