全局和局部多尺度动态虚拟视点空洞填充方法
本发明属于立体图像处理领域,具体是虚拟视点绘制中的空洞填补领域,特别涉及一种全局和局部多尺度动态虚拟视点空洞填充方法,是基于深度学习的虚拟视点空洞填补方法。
背景技术:
1、随着3d视频服务的兴起,如自由视点视频和虚拟现实,消费者对身临其境的互动体验的追求日益增加。然而,这些新形式的多媒体制作面临着挑战和高昂的成本,因为它们需要多个视角来创造真实感。为了实现这些沉浸式体验的成功,需要高效的捕获、存储和传输设备。然而,由于现有技术的局限性,这些应用受到一定的限制。基于深度图像的视角合成技术被认为是有效的虚拟视点合成方法,然而不正确的合成、遮挡以及深度数据误差可能导致合成图像中的失真或孔洞,从而严重影响观众的感官体验。正因为3d视频具有巨大的潜力,能够创造高质量的视觉效果并推动多种应用领域的需求,因此解决空洞问题变得至关重要。
2、目前,减少遮挡导致的空洞和伪影的方法主要包括两个步骤:基于深度图的预处理和3d扭曲后的空洞填充。预处理能够减少小面积空洞,但使用低通滤波器会导致图像质量下降。为解决这个问题,一些解决方案涉及基于边缘的平滑、中值滤波、不对称滤波和自适应平滑滤波等方法。然而这些传统深度图预处理可能引起过度校正,损害前景边缘。此外,传统的方法没有充分考虑复杂的多尺度语义信息,往往由于不合适的匹配图像块导致严重伪影,从而难以获得视觉上一致和语义上合理的结果。另一方面,基于深度学习的空洞填充技术在保持视觉一致性等方面已展现了优越性。但是,基于深度学习的方法仍然存在计算和数据需求的问题,特别是在复杂移动相机场景下。这些问题源于相机运动、照明变化和对象移动所引起的像素变化。为了克服这些问题,需要进一步增强基于深度学习技术的空洞处理性能。
技术实现思路
1、本发明的目的在于提供一种全局和局部多尺度动态虚拟视点空洞填充方法,旨在解决现有技术的局限性,通过使用深度卷积神经网络提取多视点图像的高级语义特征,来解决虚拟视点合成中空洞填充问题。这种方法能够实现语义一致性和结构完整性,从而有效地处理现有技术中存在的问题。通过借助深度学习技术,本发明能够更好地处理复杂的移动相机场景,重建图像能产生视觉上更加逼真、语义上更加连贯的结果。
2、本发明首先使用自适应动态模块生成最匹配的卷积核权重,不仅进一步提高了图像重建性能,而且加速了网络训练的收敛;然后引入全局和局部多尺度增强模块学习丰富的多尺度特征,将多尺度上下文信息注入到缺失区域并通过浅层特征与深层特征自适应加权融合,增强了局部特征到整体一致性的连接。
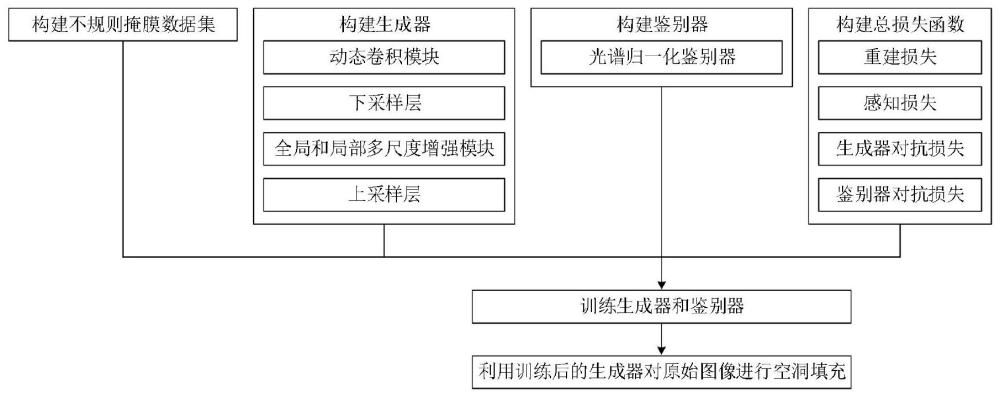
3、本发明方法具体如下:
4、(1)构建不规则掩膜数据集;
5、(1-1)采用canny边缘检测方法,从原始图像中提取每一帧原始图像的虚拟空洞,并将每帧原始图像的虚拟空洞转化为二值化图像。
6、(1-2)对每个二值化图像进行裁剪,使每个图像具有相同的尺寸n×n,64≤n≤512。
7、(1-3)对每个裁剪后的二值化图像进行镜像操作或翻转操作,得到多个掩膜图,构成掩膜数据集m。
8、(2)构建生成器,生成器包括动态卷积模块、下采样层、全局和局部多尺度增强模块以及上采样层。
9、(2-1)所述的动态卷积模块位于网络架构的编码端,通过权重生成操作和线性融合操作执行实现卷积层的动态调整,生成适应当前任务的卷积核权重,利用该卷积核权重对每一帧原始图像进行卷积,得到动态卷积特征图。
10、所述的权重生成操作通过比较每个图像块的注意力分数动态调整卷积权重;对每一帧原始图像经过裁剪,具有相同尺寸n×n的每一帧原始图像igt作为网络模型输入的图像块。
11、所述的线性融合操作是将动态调整后的卷积权重与并行的卷积核进行线性加权,将加权后卷积权重整合到动态卷积层中,对裁剪后的每帧原始图像进行卷积,得到动态卷积特征图。
12、(2-2)所述的下采样层为四个卷积层,对动态卷积特征图进行四次下采样卷积操作,得到下采样卷积特征图。
13、(2-3)所述的全局和局部多尺度增强模块包括多个叠加的多尺度增强模块以及一个全局残差结构。
14、所述的多尺度增强模块采用四种不同的膨胀率的扩张卷积,四种扩张卷积具有不同大小的感受野,将四种不同感受野获得的局部空间特征分别进行两两加权组合,得到两个局部空间特征,1×1卷积后再进行组合,得到一个局部空间特征,对该局部空间特征进行1×1卷积,得到一个跨尺度特征图;对每个跨尺度特征图与对应的下采样卷积特征图进行拼接,得到该多尺度增强模块的最终特征图,送入下一级多尺度增强模块,以此类推,重复操作,直到最后一个多尺度增强模块。
15、所述的全局残差结构是将最后的多尺度增强模块的最终特征图与门控卷积后的下采样卷积特征图进行拼接,得到最终的增强模块特征图。
16、(2-4)所述的上采样层为四个卷积层,对增强模块特征图进行四次上采样卷积操作,得到空洞修复后图像iout。
17、(3)构建鉴别器;鉴别器采用光谱归一化鉴别器,包括5个卷积层,每个卷积层的卷积核尺寸为5×5,步长为2,采用leaky relu激活函数,斜率k=0.1~0.3。
18、(4)构建总损失函数其中,为重建损失,为感知损失,和分别为生成器和鉴别器的对抗损失,上标g表示生成器,上标d表示鉴别器,λr、λp和λadv分别为重建损失系数、感知损失系数和对抗损失系数。
19、采用iout和igt之间的l1距离作为重建损失,以保证像素级的重建精度。
20、感知损失用来提高感知重建的准确性,将iout和igt送入vgg-19模型,得到五个激活图,得到φi(·),i=1,2,3,4,5表示来自vgg-19模型的五个激活图,||·||1表示l1距离。
21、生成器和鉴别器的对抗损失采用相对平均铰链损失函数;其中,生成器的对抗损失鉴别器的对抗损失xr表示真实数据,xf表示生成数据,p表示真实数据分布,q表示生成数据分布;和分别表示xr~p分布、xr~q分布、xf~p分布和xf~q分布的期望;中间参数其中c(·)为非变换鉴别器输出,表示输入数据与生成数据相比的真实程度。
22、(5)训练生成器和鉴别器;
23、将掩膜数据集m中图像和对应的受损图像iin=igt·min送入生成器进行迭代训练,min表示初始二值化mask,1表示缺失像素区域,0表示已知像素区域;每次迭代结果送入鉴别器,总损失函数进行反向梯度传播,直至总损失函数达到稳定,结束训练。
24、(6)利用训练后的生成器对原始图像进行空洞填充。
25、本发明方法在生成器中加入动态卷积模块,以提高神经网络在计算机视觉任务中的性能,同时降低计算成本。该方法通过注意力机制允许网络更好地适应不同输入特征,尤其在处理复杂场景时表现出鲁棒性。然后通过引入全局和局部多尺度增强模块,具体来说包括使用多膨胀率的扩张卷积来捕获不同尺度特征,跨尺度特征融合以及局部和全局残差结构的引入,以提高对虚拟视点合成中的空洞区域进行精确填充的能力。
- 还没有人留言评论。精彩留言会获得点赞!