一种深度神经网络策略网络模型可解释性转换算法的制作方法
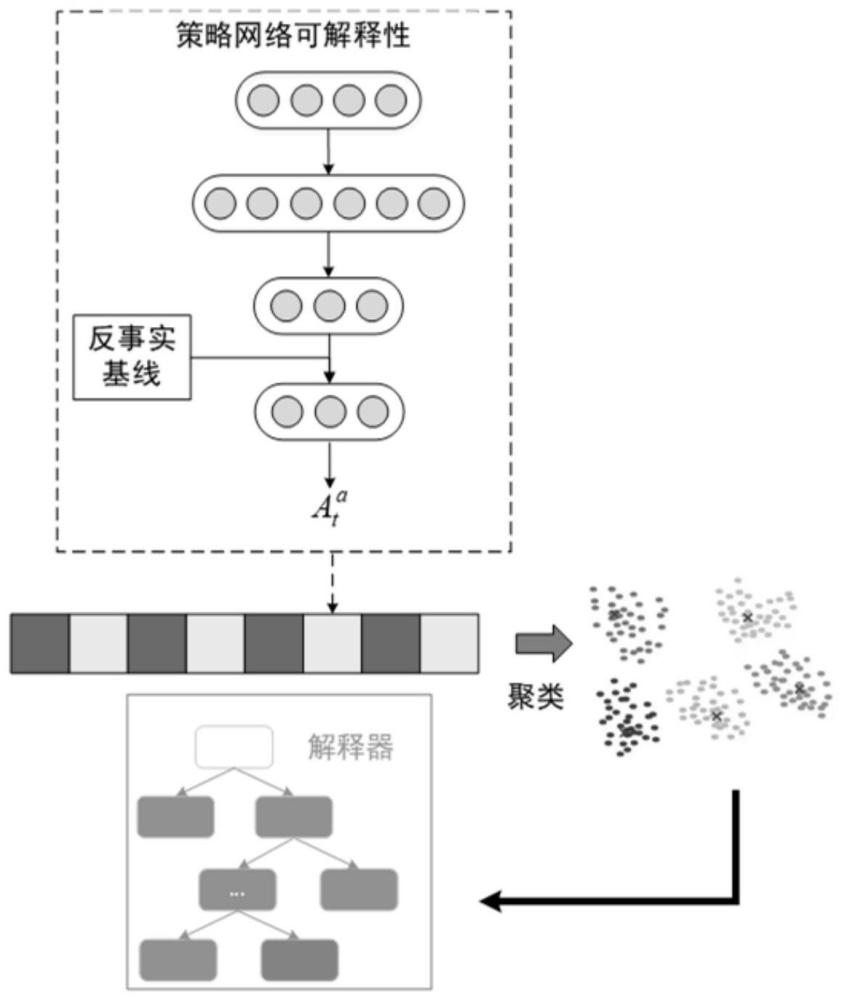
本申请属于强化学习,特别涉及一种深度神经网络策略网络模型可解释性转换算法。
背景技术:
1、人工智能是新一轮产业变革的核心驱动力,其技术与产业的发展已上升为我国的国家战略。人工智能技术的飞速发展,特别是深度学习和强化学习技术的飞跃,使无人系统从感知到决策能力都有了大幅提升。深度学习(如图像识别和自然语言处理)解决的是感知问题,强化学习解决的是决策问题,而人工智能的终极目的是通过感知进行智能决策。
2、强化学习是研究如何让智能体自主与环境交互、并从中学习最优决策的机器学习分支领域。近年来,强化学习已在许多场景中表现出超越人类专家的决策能力,比如谷歌deepmind研制的alphago计算机围棋系统、谷歌deepmind研制alphafold在蛋白质结构预测关键评估。人与人、人与机器之间的协作是人类社会关系的主要表现形式。相比围棋等单智能体问题,人类社会中的现实问题往往涉及到多智能体系统,如能源调度、交通系统、金融市场和军事指挥等。近两年,多智能体强化学习(marl)蓬勃发展,2017年,谷歌deepmind团队在即时战略游戏星际争霸(starcraft ⅱ)中开发的alphastar系统达到了职业大师级水平,胜率超过了99.8%的人类选手。2018年,openai团队开发的openai five,在著名的游戏dota2(两个队伍零和博弈对抗,5v5)的世界电子竞技比赛中战胜了人类世界冠军团队。
3、虽然强化学习具有诸多优势,但其决策性能的好坏与环境状态特征表示的优劣有很大关系,因此如何实现环境状态特征表示就变得十分重要。如果环境中的连续状态表示可以有效地预测未来数个状态的特征表示,决策模型可以有效地进行相应的决策,上述预测结果也可以辅助解释决策模型的输出,给出决策的理由。
4、因此,希望有一种技术方案来克服或至少减轻现有技术的至少一个上述缺陷。
技术实现思路
1、本申请的目的是提供了一种深度神经网络策略网络模型可解释性转换算法,以解决现有技术存在的至少一个问题。
2、本申请的技术方案是:
3、一种深度神经网络策略网络模型可解释性转换算法,包括:
4、步骤一、在多智能体强化学习环境下,选取分散式部分可观马尔科夫决策过程网络模型;
5、步骤二、对所述分散式部分可观马尔科夫决策过程网络模型进行coma可解释算法设计,包括:
6、采用集中式训练方式对所述分散式部分可观马尔科夫决策过程网络模型进行训练;
7、采用反事实基线实现所述分散式部分可观马尔科夫决策过程网络模型的置信分配。
8、在本申请的至少一个实施例中,所述分散式部分可观马尔科夫决策模型采用元组描述,其中,
9、为n个智能体的集合,为状态集合,为联合动作集合,t为转移概率函数,为联合观测集合,o为观测概率函数,r为立即回报函数,h为问题的时间范围,b0为初始的状态分布。
10、在本申请的至少一个实施例中,所述采用集中式训练方式对所述分散式部分可观马尔科夫决策过程网络模型进行训练,包括:
11、获取集中式值函数:
12、
13、其中,g为所求集中式值函数的梯度,π为参数化的神经网络策略,θ为该策略的参数,指对策略π的参数θ求偏导数,a为智能体的编号,u为该智能体在时刻t所采取的动作,为该智能体在时刻t之前自己的动作和观测状态所构成的历史轨迹,r为智能体在时刻t从环境中得到的真实奖励,st为当前多智能体系统的联合状态,st+1为下一时刻多智能体系统的联合状态,v(st)为当前的集中式值函数,v(st+1)为下一时刻的集中式值函数,γ为折扣因子;
14、采用所述集中式值函数对所述分散式部分可观马尔科夫决策过程网络模型的策略直接求梯度进行训练。
15、在本申请的至少一个实施例中,所述采用反事实基线实现所述分散式部分可观马尔科夫决策过程网络模型的置信分配,包括:
16、获取反事实基线计算优势函数:
17、
18、其中,aa(s,u)为所计算的反事实基线优势函数,a为智能体编号,s为当前多智能体系统的联合状态,u为当前所有智能体的联合动作,q(s,u)为当前联合动作u在当前联合状态s下的集中式动作值函数,u′a为智能体a在当前状态下的任一可行动作,πa(u′a|τa)为智能体a在给定当前策略πa和分布式历史轨迹τa下采取u′a的动作概率,(u-a,u′a)为仅将联合动作u中智能体a的动作替换为u′a之后的新联合动作,q(s,(u-a,u′a))为新联合动作在当前联合状态s下的集中式动作值函数;
19、得到反事实基线计算公式:
20、
21、根据所述反事实基线计算公式实现所述分散式部分可观马尔科夫决策过程网络模型的置信分配。
22、在本申请的至少一个实施例中,基于critic网络架构实现所述反事实基线的计算:
23、获取critic网络的输入,包括其他智能体的动作当前多智能体系统的联合状态st′,当前智能体的观测当前智能体的编号a,当前智能体的上一时刻的动作ut-1;
24、获取critic网络的输出,critic网络的输出为当前智能体的联合行为值函数:
25、
26、根据critic网络的输出和当前智能体的策略分布以及当前智能体的动作计算反事实基线。
27、发明至少存在以下有益技术效果:
28、本申请的深度神经网络策略网络模型可解释性转换算法,在多智能体强化学习环境下,采用coma可解释算法生成智能体的策略,利用训练好的多智能体强化学习算法模型的特征提取模块生成网络提取特征,为决策树的决策奠定基础。
技术特征:
1.一种深度神经网络策略网络模型可解释性转换算法,其特征在于,包括:
2.根据权利要求1所述的深度神经网络策略网络模型可解释性转换算法,其特征在于,所述分散式部分可观马尔科夫决策模型采用元组描述,其中,
3.根据权利要求2所述的深度神经网络策略网络模型可解释性转换算法,其特征在于,所述采用集中式训练方式对所述分散式部分可观马尔科夫决策过程网络模型进行训练,包括:
4.根据权利要求3所述的深度神经网络策略网络模型可解释性转换算法,其特征在于,所述采用反事实基线实现所述分散式部分可观马尔科夫决策过程网络模型的置信分配,包括:
5.根据权利要求4所述的深度神经网络策略网络模型可解释性转换算法,其特征在于,基于critic网络架构实现所述反事实基线的计算:
技术总结
本申请属于强化学习技术领域,特别涉及一种深度神经网络策略网络模型可解释性转换算法。包括:步骤一、在多智能体强化学习环境下,选取分散式部分可观马尔科夫决策过程网络模型;步骤二、对所述分散式部分可观马尔科夫决策过程网络模型进行COMA可解释算法设计,包括:采用集中式训练方式对所述分散式部分可观马尔科夫决策过程网络模型进行训练;采用反事实基线实现所述分散式部分可观马尔科夫决策过程网络模型的置信分配。本申请在多智能体强化学习环境下,采用COMA可解释算法生成智能体的策略,利用训练好的多智能体强化学习算法模型的特征提取模块生成网络提取特征,为决策树的决策奠定基础。
技术研发人员:徐芳芳,管聪,费思邈,闫传博,朴海音,罗庆,孙阳,孙智孝,王鹤
受保护的技术使用者:中国航空工业集团公司沈阳飞机设计研究所
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!