基于语义标签表征和文本表征协同优化的文本分类方法与流程
本发明涉及计算机,具体涉及基于语义标签表征和文本表征协同优化的文本分类方法。
背景技术:
1、文本分类是自然语言理解的重要组成部分,并且当下业界的主流文本分类模型都是基于深度学习构建和训练的。但是在真实的应用场景中,我们一般很难获得大量的已标注文本,不利用构建文本分类模型;因此提升文本分类在小数据集上的准确率,是实现文本分类模型落地的重要手段。而在深度学习模型中,为了提升文本分类效果,目前主要采用基于标签嵌入的方式、优化训练损失函数的方法、对比学习的方法等。
2、基于标签嵌入的方式需要对分类标签进行词嵌入,然后和文本的编码表征做交互,其核心需要标签的词嵌入结果能有效表征分类语义,但是目前尚的方法普遍采用一些标签描述文本、随机初始化学习等策略来获得标签嵌入,很难准确且完备地获得标签的语义表征,因而对于分类准确率提升不明显。
3、优化训练损失函数的方法都是通过对模型预测结果或者标签信息做一定地正则处理,这从本质上来说,依旧是基于交叉熵损失函数地分类优化,所以依旧存在交叉熵存在的一些问题,例如训练不稳定,容易导致模型塌缩等。这类方法尤其在小数据集上,容易导致最终的分类准确率过低。
4、基于对比学习的方法利用in-batch表征来构造正、负例对,进行表征优化。虽然有部分方法利用了标签的信息来构造对学习损失的监督信号,但是目前的对比学习损失方法没有对标签本身的表征进行优化。这导致文本分类中标签本身的语义信息没有被显示的建模和利用,无法充分挖掘标签数据所蕴含的丰富信息,从而难以有效地提升文本分类准确率。
5、因此,本发明提供了基于语义标签表征和文本表征协同优化的文本分类方法,以解决文本标签语义的表征优化不足的问题,从而显著地提升小数据集上的文本分类准确率。
技术实现思路
1、本发明要解决的技术问题是:提供基于语义标签表征和文本表征协同优化的文本分类方法,以解决文本标签语义的表征优化不足的问题,从而显著地提升小数据集上的文本分类准确率。
2、为实现上述目的,本发明采用的技术方案如下:
3、基于语义标签表征和文本表征协同优化的文本分类方法,包括以下步骤:
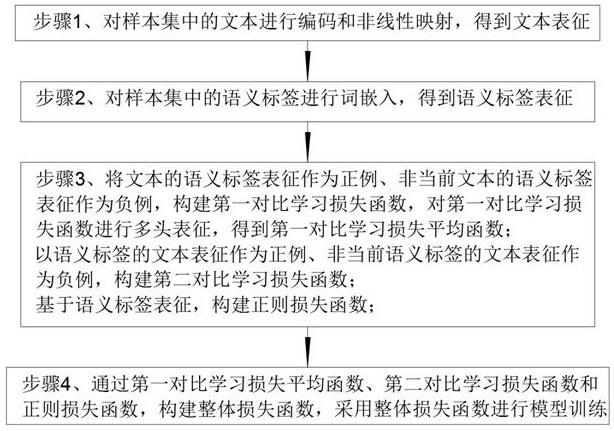
4、步骤1、对样本集中的文本进行编码和非线性映射,得到文本表征;
5、步骤2、对样本集中的语义标签进行词嵌入,得到语义标签表征;
6、步骤3、将文本的语义标签表征作为正例、非当前文本的语义标签表征作为负例,构建第一对比学习损失函数,对第一对比学习损失函数进行多头表征,得到第一对比学习损失平均函数;
7、以语义标签的文本表征作为正例、非当前语义标签的文本表征作为负例,构建第二对比学习损失函数;
8、基于语义标签表征,构建正则损失函数;
9、步骤4、通过第一对比学习损失平均函数、第二对比学习损失函数和正则损失函数,构建整体损失函数,采用整体损失函数进行模型训练。
10、进一步地,所述步骤1包括:步骤11、采用预训练语言模型对包含n个token的文本 x进行编码, x=x1, x2,..., xi,......, xn , xi表示第i个token的编码表征, n为正整数,i ∈n;步骤12、使用一个非线性映射网络 g对步骤11的编码结果进行处理,得到文本表征 h,, f表示编码器。
11、进一步地,所述步骤2中,语义标签表征 l∈r c×d, c表示样本集的语义标签个数,d表示语义标签稠密向量的向量长度,r代表集合实数集。
12、进一步地,所述第一对比学习损失函数的计算公式为:,其中,是温度参数,cos为余弦相似度, n表示文本的数目, c表示样本集的语义标签个数, p表示 c个语义标签中的某一个语义标签, l p表示语义标签 p的语义标签表征, l yi表示第 i个文本的语义标签表征, h xi表示第 i个文本的文本表征。
13、进一步地,所述第一对比学习损失平均函数的计算公式为:,其中,,,k表示某个表征头,m表示表征头的个数。
14、进一步地,所述第二对比学习损失函数的计算公式为:,其中, p表示 c个语义标签中的某一个语义标签, h a表示语义标签 p的文本表征, h b表示非语义标签 p的文本表征, l p表示语义标签 p的语义标签表征, a(p)表示语义标签 p的样本集合, b(p)表示非语义标签 p的样本集合。
15、进一步地,所述正则损失函数的计算公式为:,其中, l i和 l j分别表示c个语义标签中某个语义标签的语义标签表征。
16、进一步地,所述整体损失函数的计算公式为:,其中λ为调节正则损失函数的系数,λ取0.1~0.5。
17、进一步地,在所述步骤4的模型训练中,基于文本表征和语义标签表征之间的相似度匹配得分预测文本分类结果。
18、进一步地,在所述步骤4的模型训练中,将文本表征和语义标签表征融合得到融合表征,基于融合表征和语义标签表征之间的相似度匹配得分预测文本分类结果,融合表征的计算公式为:
19、;
20、其中, h j表示候选语义标签的文本表征, β表示权重向量。
21、与现有技术相比,本发明具有以下有益效果:
22、本发明基于对比学习算法同时优化文本表征和语义标签表征,解决文本标签语义的表征优化不足的问题,从而显著地提升小数据集上的文本分类准确率。
- 还没有人留言评论。精彩留言会获得点赞!