一种领域知识图谱的自适应机器翻译方法、介质及终端
本发明属于计算机科学,尤其涉及一种领域知识图谱的自适应机器翻译方法、介质及终端。
背景技术:
1、随着深度学习的发展和成熟,神经网络机器翻译的质量也越来越高。尽管通用机器翻译技术发展成熟,但面对大数据下多元化网络语言的爆发增长,领域自适应机器翻译的理论体系和实证研究尚不完整,因此,复杂语义翻译自适应问题的研究极具理论意义和实用价值。神经机器翻译中的领域自适应方法分为基于数据的方法和基于模型的方法,基于数据的方法主要通过对领域外语料做筛选来扩充领域内的数据规模,基于模型的方法则通过改进模型的结构、训练方法、解码方法等来提升领域内的翻译性能,这两类方法都使用单语或平行语料,对复杂领域知识的翻译难以进行自适应调整。
2、知识图谱兴起于大数据时代,其初衷是为了提高搜索引擎的能力,提升用户的搜索质量以及搜索体验。目前,随着智能信息服务应用的不断发展,知识图谱已被广泛应用于智能搜索、智能问答、个性化推荐等领域。领域知识图谱是知识图谱中的一种,又称为行业知识图谱或垂直知识图谱,是面向某一特定领域的、由该领域的专业数据构成的行业知识库,领域知识图谱的数据来源具有较强的领域特性,同时能实现复杂语义的精准化,目前广泛应用的领域知识图谱包括经贸领域的商品知识图谱、文化领域的文学作品知识图谱以及科技领域的科技资源知识图谱等。现有技术中存在较多基于知识图谱的的机器翻译的研究,然而,由于机器翻译自身对领域知识图谱自适应调整能力有限,现有技术中基于领域知识图谱的机器翻译目前仍然存在一定空白,导致现有机器翻译的质量与效率不高。公开号为cn114118104a的专利申请提供了一种基于知识图谱的神经机器翻译方法、装置、设备及介质,该方法包括:获取原始双语平行语句对,根据原始双语平行语句对提取单词和短语翻译对,得到对应的种子实体翻译对;获取源语言知识图谱和目标语言知识图谱,根据种子实体翻译对、源语言知识图谱和目标语言知识图谱,构建对应的向量空间;获取到待翻译实体集合时,根据向量空间对待翻译实体集合进行推断,得到对应的待翻译实体翻译对;计算种子实体翻译对和待翻译实体翻译对的距离,根据距离得到包含待翻译实体翻译对的伪双语平行句对。此专利虽然将知识图谱融合到了神经机器翻译中,但是对于领域知识图谱的自适应机器翻译并未给出相关技术方案,仍存在与现有技术相同的弊端。
3、因此,如何提供一种基于领域知识图谱的自适应机器翻译方法,以提高翻译质量和效率,是本技术领域人员亟待解决的问题。
技术实现思路
1、针对现有技术的不足,本发明的目的是提供一种领域知识图谱的自适应机器翻译方法,以解决现有技术中基于领域知识图谱的机器翻译能力有限,导致翻译质量和效率低的问题;另外本发明还提供了一种领域知识图谱的自适应机器翻译介质及终端。
2、为了解决上述技术问题,本发明采用了如下的技术方案:
3、第一方面,本发明提供了一种领域知识图谱的自适应机器翻译方法,包括以下步骤:
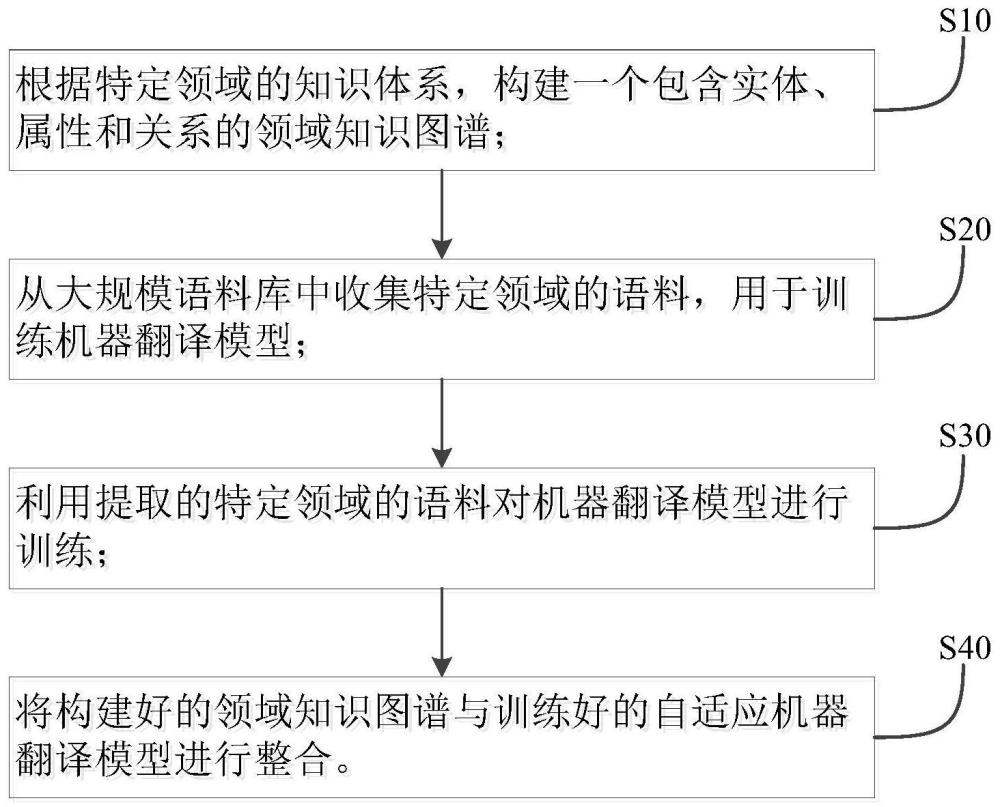
4、s10、根据特定领域的知识体系,构建一个包含实体、属性和关系的领域知识图谱;
5、s20、从大规模语料库中收集特定领域的语料,用于训练机器翻译模型;
6、s30、利用提取的特定领域的语料对机器翻译模型进行训练;
7、s40、将构建好的领域知识图谱与训练好的自适应机器翻译模型进行整合。
8、进一步的,所述步骤s10的具体步骤如下:
9、s101、确定需要构建知识图谱的领域;
10、s102、从多个数据源中采集相关领域的数据;
11、s103、对采集到的数据进行实体识别,确定实体的类型和属性;
12、s104、对实体之间的关系进行抽取,确定关系的类型和属性;
13、s105、对实体和关系进行表示,建立相应的知识图谱模型;
14、s106、对知识图谱进行查询。
15、进一步的,所述步骤s40中整合的方法包括实体替换方法、实体标记方法和信息注入方法,所述实体替换方法是将领域知识图谱中的实体和属性信息替换为对应的目标语言词汇,并将替换后的语料用于机器翻译模型的训练;所述实体标记方法是在训练语料中,为领域知识图谱中的实体和属性信息添加特殊标记,然后将标记后的语料用于机器翻译模型的训练;所述信息注入方法是将领域知识图谱中的实体和属性信息直接注入到机器翻译模型中。
16、进一步的,所述步骤s20中特定领域的语料包括公开数据集和自行收集的数据集,所述公开数据集包括wmt和iwslt,所述自行收集的数据集包括医学文献、临床病历、医学专业网站、旅游网站、旅游评论、旅游书籍。
17、进一步的,机器学习方法包括hmm算法、crf算法、lstm算法、cnn算法、bert算法和bilstm算法。
18、进一步的,所述步骤s102中的数据包括文本、语音和图像;采集数据的工具包括python中的requests数据库、beautifulsoup4数据库以及openkg中的开放数据资源。
19、进一步的,所述步骤s103中实体的类型包括人物、机构和地点;实体识别的工具包括stanford ner、mallet、hanlp、nltk、spacy和crfsuite。
20、进一步的,所述步骤s104中关系的类型包括人物之间的关系和公司之间的合作关系;关系的抽取工具包括openie和reverb。
21、第二方面,本发明还提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上所述方法。
22、第三方面,本发明还提供了一种电子终端,包括:处理器及存储器;所述存储器用于存储计算机程序,所述处理器用于执行所述存储器存储的计算机程序,以使所述终端执行如上所述方法。
23、本发明提供的领域知识图谱的自适应机器翻译方法、介质及终端与现有技术相比,至少具有如下有益效果:
24、现有技术中存在的大多是基于知识图谱的机器翻译,基于领域知识图谱的机器翻译目前仍然存在一定空白,导致现有机器翻译的质量与效率不高。本发明流程简单、结果准确,利用领域知识图谱中的信息,将领域知识图谱中的实体、属性和关系等信息与机器翻译系统进行融合,即利用领域知识图谱对机器翻译进行了增强,提高了自适应机器翻译的精准性,根据不同领域的语料输入进行领域机器翻译模型动态切换,还可以随着不断增多的领域数据知识增量更新模型,提高领域模型的动态自适应性,与现有技术相比大大提高了翻译质量和效率。
技术特征:
1.一种领域知识图谱的自适应机器翻译方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种领域知识图谱的自适应机器翻译方法,其特征在于,所述步骤s10的具体步骤如下:
3.根据权利要求1所述的一种领域知识图谱的自适应机器翻译方法,其特征在于,所述步骤s40中整合的方法包括实体替换方法、实体标记方法和信息注入方法,所述实体替换方法是将领域知识图谱中的实体和属性信息替换为对应的目标语言词汇,并将替换后的语料用于机器翻译模型的训练;所述实体标记方法是在训练语料中,为领域知识图谱中的实体和属性信息添加特殊标记,然后将标记后的语料用于机器翻译模型的训练;所述信息注入方法是将领域知识图谱中的实体和属性信息直接注入到机器翻译模型中。
4.根据权利要求1所述的一种领域知识图谱的自适应机器翻译方法,其特征在于,所述步骤s20中特定领域的语料包括公开数据集和自行收集的数据集,所述公开数据集包括wmt和iwslt,所述自行收集的数据集包括医学文献、临床病历、医学专业网站、旅游网站、旅游评论、旅游书籍。
5.根据权利要求1所述的一种领域知识图谱的自适应机器翻译方法,其特征在于,机器学习方法包括hmm算法、crf算法、lstm算法、cnn算法、bert算法和bilstm算法。
6.根据权利要求1所述的一种领域知识图谱的自适应机器翻译方法,其特征在于,所述步骤s102中的数据包括文本、语音和图像;采集数据的工具包括python中的requests数据库、beautifulsoup4数据库以及openkg中的开放数据资源。
7.根据权利要求6所述的一种领域知识图谱的自适应机器翻译方法,其特征在于,所述步骤s103中实体的类型包括人物、机构和地点;实体识别的工具包括stanford ner、mallet、hanlp、nltk、spacy和crfsuite。
8.根据权利要求7所述的一种领域知识图谱的自适应机器翻译方法,其特征在于,所述步骤s104中关系的类型包括人物之间的关系和公司之间的合作关系;关系的抽取工具包括openie和reverb。
9.一种计算机可读存储介质,其特征在于,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至8任一项所述方法。
10.一种电子终端,其特征在于,包括:处理器及存储器;
技术总结
本发明适用于计算机科学技术领域,涉及一种领域知识图谱的自适应机器翻译方法、介质及终端,包括:S10、根据特定领域的知识体系,构建一个包含实体、属性和关系的领域知识图谱;S20、从大规模语料库中收集特定领域的语料,用于训练机器翻译模型;S30、利用提取的特定领域的语料对机器翻译模型进行训练;S40、将构建好的领域知识图谱与训练好的自适应机器翻译模型进行整合。本发明流程简单、结果准确,利用领域知识图谱对机器翻译进行了增强,提高了自适应机器翻译的精准性,与现有技术相比大大提高了翻译质量和效率。
技术研发人员:刘伍颖,王源
受保护的技术使用者:鲁东大学
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!