基于知识蒸馏与图模型的小样本增量辐射源个体识别方法
本发明涉及辐射源个体识别,具体涉及基于知识蒸馏与图模型的小样本增量辐射源个体识别方法。
背景技术:
1、物联网(iot)的快速发展和移动设备的广泛应用,导致大量无线设备的集成,同时也带来了物联网和5g网络等新技术的出现。然而,在这些设备上部署多种无线技术带来了巨大的安全和隐私挑战,因为物联网设备固有的广播特性造成了可能被恶意用户利用的漏洞。因此,为这些物联网设备管理和分发加密密钥变得异常具有挑战性。因此,迫切需要一种新颖、防篡改和安全的设备验证方法。
2、辐射源个体识别(rffi)是指通过从接收信号中提取包含发射设备个人信息的微妙特征来识别不同辐射源的过程。这些细微特征被称为射频指纹(rff),归因于射频设备中存在的容差效应。这些效应导致设备响应中的非线性特征,而这些非线性特征的变化又能区分不同的辐射源设备。与人类指纹类似,rff是区分射频设备的基础,可用作设备身份验证的安全方法[1]。
3、最近,深度学习已成为解决rffi问题的主流解决方案。然而,基于深度学习的数据驱动方法在rffi中的性能受到了限制,因为在非合作场景中无法获得大量标记的信号样本。小样本学习(fsl)作为一种小实例深度学习范式,已被经验证明在有限数据的图像识别任务中非常有效。它旨在解决典型分类方法泛化不足和对稀有类别适应性差的问题。它能缓解因缺乏标记样本而导致的严重性能下降。现有的基于fsl的rffi方法可以有效地解决训练样本较少的封闭集的rffi问题。zhang等人[2]提出了一种数据增强(da)辅助的少量学习方法,提高了识别准确率和模型的鲁棒性。wang等人[3]提出了一种基于混合数据增强和深度度量学习(hda-dml)的新方法,摆脱了对辅助数据集的依赖。
4、rffi可以持续捕获新类别目标的射频信号,这些信号在训练阶段是未知的,自然会被误判为已知类别。为了确保识别的可靠性,传统的rffi模型需要针对新旧类别进行再训练。虽然在非开放场景中添加训练数据进行再训练对rffi模型的性能影响不大,但重复训练之前的训练样本会导致大量时间消耗和存储资源浪费,这对于实时rffi任务来说并不合理。此外,直接丢弃旧目标的训练样本,用新目标对训练好的模型进行微调,会造成灾难性遗忘,导致旧目标识别能力下降。因此,有必要开发新的rffi范式,并在开放场景中设计模型,使其能够快速适应更新的数据,并在保持原有分类能力的同时学习新类别的有效知识。
5、类增量学习是一种先进的开放场景目标识别技术。首先使用基础类对模型进行训练,然后通过提供相应的训练数据来添加新的类。然后,只使用新类别对模型进行增量训练,从而实现对基础类别和新类别的统一识别。最近的研究表明,基于类增量学习的rffi方法可以节省计算资源,避免灾难性遗忘,同时避免重复训练和存储旧类。liu等人[3]总结了一种通用的rffi框架,并提出了一种有效减少基于增量学习的rffi所需旧数据量的方法,从而节省了训练时间和存储空间。liu等人[4]提出了一种利用增量学习解决射频指纹识别问题的分布式传感器系统,该系统可以显著减少训练时间并适应流式数据。大量实验表明,该方法计算效率高,识别准确率令人满意,尤其是在信噪比较低的情况下。zhou等人[5]提出了一种基于知识提炼的增量学习的rffi方法,该方法利用连续数据流不断更新识别模型。liu等人[6]提出了一种新的不使用历史数据的通道分离方案,这是一种在不同学习阶段自动分离设备指纹并避免潜在冲突的策略。
6、在上述挑战的激励下,本发明提出了一种基于类增量学习的新rffi方法,该方法能够以高效、及时的计算方式在少量训练样本的情况下适应新的类别。rffi在小样本类增量学习[7],[8]中面临的主要挑战是,少量的标记样本会导致对新目标的严重过拟合和对旧样本的灾难性遗忘。
7、[1]zhang j,woods r,sandell m,et al.radio frequency fingerprintidentification for narrowband systems,modelling and classification[j].ieeetransactions on information forensics and security,2021,16:3974–3987.
8、[2]zhang x,wang y,zhang y,et al.data augmentation aided few-shotlearning for specific emitter identification[c].in 2022ieee 96th vehiculartechnology conference(vtc2022-fall),
9、2022:1–5.
10、[3]wang c,fu x,wang y,et al.few-shot specific emitter identificationvia hybrid data augmentation and deep metric learning[j].arxiv preprintarxiv:2212.00252,2022.
11、[4]liu d,liu c,yuan m.incremental learning for radio frequencyfingerprint identification[c].in 2021 18th international computer conferenceon wavelet active media technology and information processing(iccwamtip),2021:326–329.
12、[5]liu m,wang j,zhao n,et al.radio frequency fingerprintcollaborative intelligent identification using incremental learning[j].ieeetransactions on network science and engineering,2022,9(5):3222–3233.
13、[6]zhou j,peng y,gui g,et al.a novel radio frequency fingerprintidentification method using incremental learning[c].in 2022ieee 96thvehicular technology conference(vtc2022-fall),2022:1–5.
14、[7]tao x,hong x,chang x,et al.few-shot class-incremental learning[c].in 2020ieee/cvf conference on computer vision and pattern recognition(cvpr),2020:12180–12189.
15、[8]zhang c,song n,lin g,et al.few-shot incremental learning withcontinually evolved classifiers[c].in 2021ieee/cvf conference on computervision and pattern recognition(cvpr),2021:12450–12459.
技术实现思路
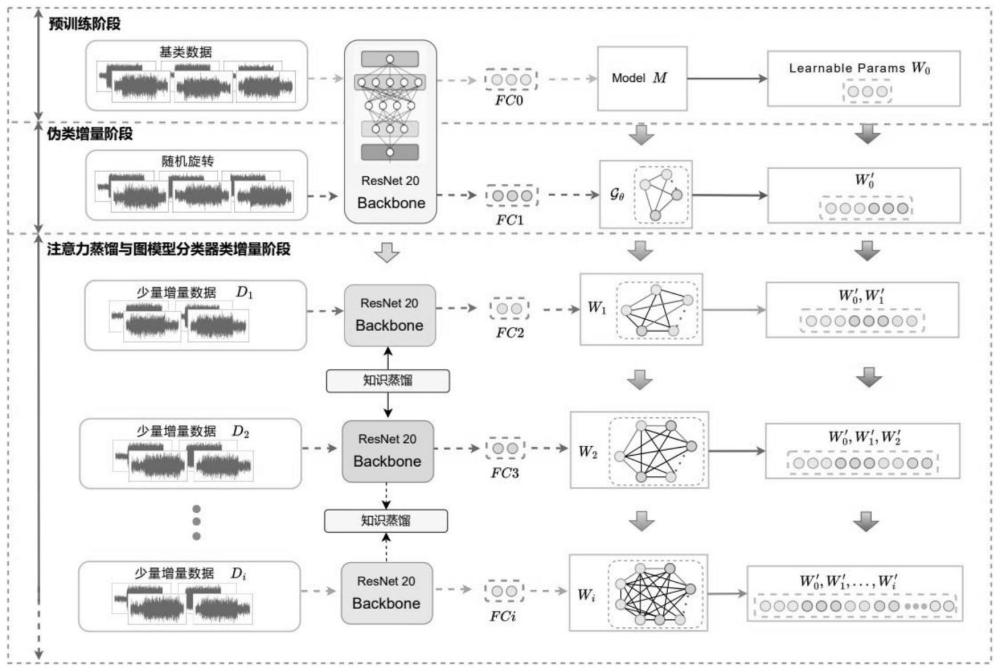
1、为克服现有技术的不足,本发明旨在提出复杂场景下的辐射源个体识别方法。为此,本发明采取的技术方案是,基于知识蒸馏与图模型的小样本增量辐射源个体识别方法,首先使用已知的辐射源数据进行训练,通过不断优化交叉熵损失得到一个骨干网络;随后进行伪类增量训练:使用已知的辐射源数据为虚拟增量类和虚拟基础类分别划分支持集和查询集,支持集用于学习不同类别的分类器权重,而查询集用于计算优化损失,使用支持集为虚拟基础类和虚拟增量类分别建立两个分类器,随后,将这两个分类器分别连接同一自适应图模型分类器,通过训练对自适应图模型分类器进行参数更新,借助更新后的自适应图模型分类器,对虚拟基础类和虚拟增量类的查询集进行预测,进而计算损失以优化自适应图模型分类器,优化好的自适应图模型分类器与骨干网络进行连接;然后进入增量训练阶段,一方面,冻结所述的骨干网络作为教师网络,同时对其复制并通过新增的少量辐射源个体对复制的骨干网络进行训练,得到学生网络,利用教师网路对学生网络进行知识蒸馏,最终完成蒸馏的学生网络即作为训练好的骨干网络,该学生网络也复制冻结为教师网络,用于进行下一次增量训练,即每出现新增的少量辐射源个体即进行增量训练;另一方面,已经训练完成的自适应图模型分类器会根据新出现的少量辐射源个体自适应的联系上下文信息;最后,利用训练好的骨干网络及其连接的自适应图模型分类器实现小样本类增量的辐射源个体识别。
2、知识蒸馏具体步骤如下:
3、a)初始化阶段:在初始阶段,一个基础的骨干网络被训练来解决初始任务,该任务涉及所有类别,这个模型在后续的类增量学习中将作为教师网络;
4、b)新类别引入:使用新引入的类别对冻结的教师网络进行训练,形成学生网络,并使用现有的教师网络对新类别数据进行预测,生成软目标标签,这些软目标标签包含了教师网络对新类别数据的预测概率分布;
5、c)学生网络训练:学生网络使用软目标标签进行训练,以逼近教师网络的预测;
6、d)反复迭代:当引入新的类别时,多次迭代执行上述步骤,逐步更新学生网络,每次迭代都通过软目标标签从教师网络中传递知识到学生网络。
7、表示在任务tn中学习的cnn分类器的参数矩阵,其中,wn中的每一行向量是与特定类别c相对应的权重,cn是任务tn中的类别数,e是嵌入向量的维度。可视为类别c的原型向量,通过查看所有其他类别的来调整的值,首先要收集之前任务中所有其他类别的权重向量:
8、
9、其中n是迄今为止的任务总数,然后,将wn中的权重向量表示为图模型中的节点,并利用自适应图模型分类器来模拟这些原型向量之间的关系,并传播上下文信息,注意力机制被用来促进节点之间的信息传播,使每个节点都能从图中的其他节点接收上下文信息,
10、在辐射源个体识别任务中,全连接图由节点和边j≠k.其中是第j个节点,ejk是连接和的边,i是节点总数。对于任意两个节点和关系系数ejk的计算公式为
11、
12、其中λ和μ表示线性变换函数,用于将原始原型表示投影到一个新的度量空间,函数<·,·>计算两个向量之间的余弦相似度,为了清楚起见,和下标中的任务索引省略了。然后使用softmax函数对得到的系数进行归一化处理,得出与中心节点j相对应的最终注意力权重
13、
14、在归一化注意力系数ajk的基础上,根据ajk聚合图中所有节点的信息,并将其与原始节点表示融合,从而得到
15、
16、其中u是线性变换的权重矩阵,重复上述操作,更新图中所有节点的嵌入,最后得到更新后的分类器
17、
18、本发明的特点及有益效果是:
19、本发明提出了基于知识蒸馏与图模型的小样本增量辐射源个体识别的方法,该方法不仅有效的解决了实际场景的rffi系统必须随时处理新的类别的问题,而且解决了通常情况下很难同时收集足够的数据来训练理想的分类模型的问题。本发明在ads-b数据集上进行了一系列的实验来验证本发明的方法在小样本增量条件下的识别效果。如图4所示,为ads-b数据集上的混淆矩阵效果图。图中前60个类为基类,后40个类为新类,每段会话增加5个少量新类个体数据,可以看出本发明的方法可以在不遗忘旧类的情况下,学习少量新类个体数据。也就是说,同时解决了小样本的过拟合和增量的灾难性遗忘的问题。
- 还没有人留言评论。精彩留言会获得点赞!