一种表盘生成方法、装置、智能穿戴设备及存储介质与流程
本发明主要涉及智能穿戴,尤其涉及一种表盘生成方法、装置、智能穿戴设备及存储介质。
背景技术:
1、随着移动技术的发展,许多传统的电子设备产品也开始增加移动方面的功能,比如过去只能用来看时间的手表,现今也可以通过智能手机或家庭网络与互联网相连,显示来电信息、推特和新闻信息流、天气信息等内容。这种新手表可被称作智能手表。
2、目前,用户可以为智能手表设置已有的固定样式的表盘。通常,用户可以在对应的应用商店里浏览已有的固定样式的表盘,并从中选择自己喜欢的表盘,下载并应用到智能手表上,这种方式选择的表盘种类有限,且样式是固定的并不能根据用户的需求进行定制,并且需要从特定的表盘库中进行选择,并需要用户进行操作繁琐,达不到用户的对于表盘多样化和智能化的使用需求。
3、因此,如何设计一种可根据用户需要智能生成表盘的方法,是待解决的技术问题。
技术实现思路
1、基于此,有必要针对现有的问题,提供一种表盘生成方法、装置、智能穿戴设备及存储介质。
2、第一方面,本技术实施例提供了一种表盘生成方法,包括:
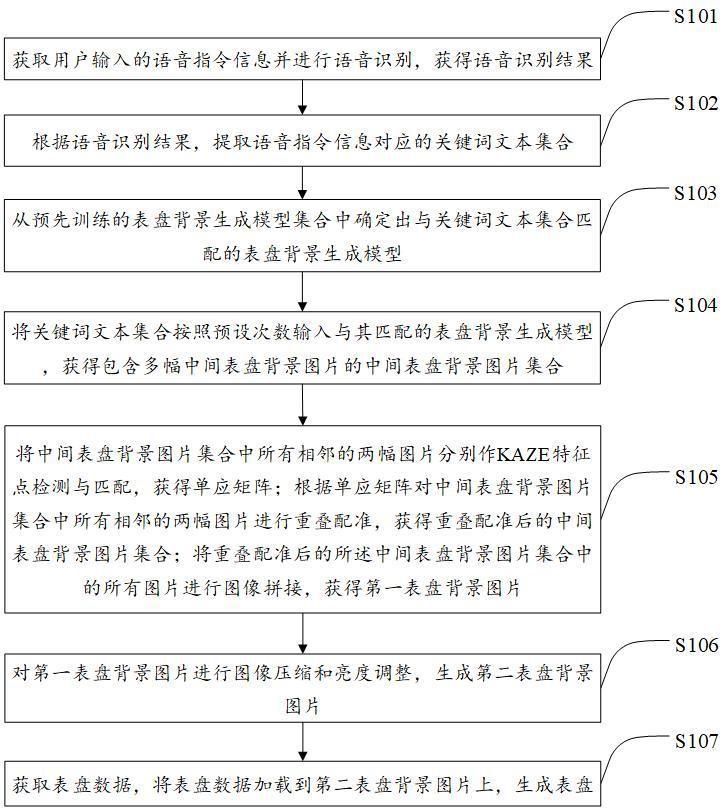
3、获取用户输入的语音指令信息并进行语音识别,获得语音识别结果;
4、根据所述语音识别结果,提取所述语音指令信息对应的关键词文本集合;
5、从预先训练的表盘背景生成模型集合中确定出与所述关键词文本集合匹配的表盘背景生成模型;
6、将所述关键词文本集合按照预设次数输入与其匹配的所述表盘背景生成模型,获得包含多幅中间表盘背景图片的中间表盘背景图片集合;
7、将所述中间表盘背景图片集合中所有相邻的两幅图片分别作kaze特征点检测与匹配,获得单应矩阵;根据所述单应矩阵对所述中间表盘背景图片集合中所有相邻的两幅图片进行重叠配准,获得重叠配准后的所述中间表盘背景图片集合;将重叠配准后的所述中间表盘背景图片集合中的所有图片进行图像拼接,获得第一表盘背景图片;
8、对所述第一表盘背景图片进行图像压缩和亮度调整,生成第二表盘背景图片;
9、获取表盘数据,将所述表盘数据加载到所述第二表盘背景图片上,生成表盘。
10、优选地,所述获取用户输入的语音指令并进行语音识别,获得语音识别结果,包括:
11、解析所述语音指令信息,获得所述用户的口音所属地域;
12、根据口音所属地域对所述语音指令信息进行校正;
13、将校正后的所述语音指令信息转换为所述语音识别结果并输出,所述语音识别结果通过文字信息来表征。
14、优选地,所述解析所述语音指令信息,获得所述用户的口音所属地域,包括:
15、提取所述语音指令信息中的语音特征;
16、根据所述语音特征在预设地域语音库中查找与所述语音特征匹配的语音所属地域信息。
17、优选地,所述根据口音所属地域对所述语音指令信息进行校正,具体包括:
18、根据所述用户的口音所属地域确定第一语音编码格式;
19、根据所述第一语音编码格式编码所述语音指令信息,生成第一数据帧;
20、对所述第一数据帧进行解码,产生线性语音采样序列;
21、获取与普通话对应的第二语音编码格式;
22、根据所述第二语音编码格式,将所述线性语音采样序列转换成普通话语音。
23、优选地,所述语音特征具体包括:语调、语速、声调中一个或多个。
24、优选地,按照下述方式预先训练获得所述表盘背景生成模型集合:
25、获取所述表盘背景生成模型集合中所有表盘背景生成模型对应的训练样本集合,训练样本包括样本参数和样本表盘背景图片;
26、利用深度学习方法,基于每个所述训练样本集合分别对与其对应的初始表盘背景生成模型进行训练,得到对应的所述表盘生成背景模型,所有的所述表盘生成背景模型构成所述表盘背景生成模型集合。
27、优选地,所述初始表盘背景生成模型为生成式对抗网络,所述生成式对抗网络包括生成模型网络和判别模型网络;以及所述利用深度学习方法,基于每个所述训练样本集合分别对与其对应的初始表盘背景生成模型进行训练,得到对应的所述表盘生成背景模型,包括:
28、对于所述训练样本集合中的训练样本,将该训练样本中的样本参数输入所述生成模型网络,得到生成表盘背景图片;
29、将所述生成表盘背景图片和该训练样本中的样本表盘背景图片输入所述判别模型网络,得到判别结果,其中,所述判别结果用于表征所述生成表盘背景图片和该训练样本中的样本表盘背景图片是真实表盘背景图片的概率;
30、基于所述判别结果调整所述生成模型网络和所述判别模型网络的参数。
31、优选地,所述训练样本集合通过如下步骤获得:
32、获取属于该表盘背景生成模型对应的原始图片集合;
33、针对所述原始图片集合中的每个原始图片进行表盘背景区域截取,获得该原始图片对应的表盘背景区域;
34、去除截取出的表盘背景区域的毛边,得到该原始图片对应的样本表盘背景图片;
35、提取该原始图片对应的样本表盘背景图片的参数,得到该原始图片对应的样本参数。
36、优选地,所述对所述第一表盘背景图片进行图像压缩和亮度调整,生成第二表盘背景图片,包括:
37、依次读取所述第一表盘背景图片的像素点,统计相邻且相同像素值的像素点的个数值,并保存所述相同的像素点的像素值及个数值,以及同时还统计并保存不同像素值的像素点的像素值及个数值,以实现所述第一表盘背景图片的压缩;
38、将压缩后的所述第一表盘背景图片按照预设表盘背景图片尺寸进行剪裁,获得剪裁后的所述第一表盘背景图片;
39、将剪裁后的所述第一表盘背景图片按照预设图片参数进行亮度调整,获得所述第二表盘背景图片。
40、第二方面,本技术实施例提供了一种表盘生成装置,包括:
41、语音识别单元,用于获取用户输入的语音指令信息并进行语音识别,获得语音识别结果;
42、提取单元,用于根据所述语音识别结果,提取所述语音指令信息对应的关键词文本集合;
43、确定单元,用于从预先训练的表盘背景生成模型集合中确定出与所述关键词文本集合匹配的表盘背景生成模型;
44、第一生成单元,将所述关键词文本集合按照预设次数输入与其匹配的所述表盘背景生成模型,获得包含多幅中间表盘背景图片的中间表盘背景图片集合;
45、第二生成单元,将所述中间表盘背景图片集合中所有相邻的两幅图片分别作kaze特征点检测与匹配,获得单应矩阵;根据所述单应矩阵对所述中间表盘背景图片集合中所有相邻的两幅图片进行重叠配准,获得重叠配准后的所述中间表盘背景图片集合;将重叠配准后的所述中间表盘背景图片集合中的所有图片进行图像拼接,获得第一表盘背景图片;
46、图像处理单元,用于对所述第一表盘背景图片进行图像压缩和亮度调整,生成第二表盘背景图片;
47、表盘生成单元,用于获取表盘数据,将所述表盘数据加载到所述第二表盘背景图片上,生成表盘。
48、优选地,所述获取用户输入的语音指令并进行语音识别,获得语音识别结果,包括:
49、解析所述语音指令信息,获得所述用户的口音所属地域;
50、根据口音所属地域对所述语音指令信息进行校正;
51、将校正后的所述语音指令信息转换为所述语音识别结果并输出,所述语音识别结果通过文字信息来表征。
52、优选地,所述解析所述语音指令信息,获得所述用户的口音所属地域,包括:
53、提取所述语音指令信息中的语音特征;
54、根据所述语音特征在预设地域语音库中查找与所述语音特征匹配的语音所属地域信息。
55、优选地,所述根据口音所属地域对所述语音指令信息进行校正,具体包括:
56、根据所述用户的口音所属地域确定第一语音编码格式;
57、根据所述第一语音编码格式编码所述语音指令信息,生成第一数据帧;
58、对所述第一数据帧进行解码,产生线性语音采样序列;
59、获取与普通话对应的第二语音编码格式;
60、根据所述第二语音编码格式,将所述线性语音采样序列转换成普通话语音。
61、优选地,所述语音特征具体包括:语调、语速、声调中一个或多个。
62、优选地,按照下述方式预先训练获得所述表盘背景生成模型集合:
63、获取所述表盘背景生成模型集合中所有表盘背景生成模型对应的训练样本集合,训练样本包括样本参数和样本表盘背景图片;
64、利用深度学习方法,基于每个所述训练样本集合分别对与其对应的初始表盘背景生成模型进行训练,得到对应的所述表盘生成背景模型,所有的所述表盘生成背景模型构成所述表盘背景生成模型集合。
65、优选地,所述初始表盘背景生成模型为生成式对抗网络,所述生成式对抗网络包括生成模型网络和判别模型网络;以及所述利用深度学习方法,基于每个所述训练样本集合分别对与其对应的初始表盘背景生成模型进行训练,得到对应的所述表盘生成背景模型,包括:
66、对于所述训练样本集合中的训练样本,将该训练样本中的样本参数输入所述生成模型网络,得到生成表盘背景图片;
67、将所述生成表盘背景图片和该训练样本中的样本表盘背景图片输入所述判别模型网络,得到判别结果,其中,所述判别结果用于表征所述生成表盘背景图片和该训练样本中的样本表盘背景图片是真实表盘背景图片的概率;
68、基于所述判别结果调整所述生成模型网络和所述判别模型网络的参数。
69、优选地,所述训练样本集合通过如下步骤获得:
70、获取属于该表盘背景生成模型对应的原始图片集合;
71、针对所述原始图片集合中的每个原始图片进行表盘背景区域截取,获得该原始图片对应的表盘背景区域;
72、去除截取出的表盘背景区域的毛边,得到该原始图片对应的样本表盘背景图片;
73、提取该原始图片对应的样本表盘背景图片的参数,得到该原始图片对应的样本参数。
74、优选地,所述对所述第一表盘背景图片进行图像压缩和亮度调整,生成第二表盘背景图片,包括:
75、依次读取所述第一表盘背景图片的像素点,统计相邻且相同像素值的像素点的个数值,并保存所述相同的像素点的像素值及个数值,以及同时还统计并保存不同像素值的像素点的像素值及个数值,以实现所述第一表盘背景图片的压缩;
76、将压缩后的所述第一表盘背景图片按照预设表盘背景图片尺寸进行剪裁,获得剪裁后的所述第一表盘背景图片;
77、将剪裁后的所述第一表盘背景图片按照预设图片参数进行亮度调整,获得所述第二表盘背景图片。
78、第三方面,本技术实施例提供一种智能穿戴设备,所述设备包括:
79、处理器;
80、用于存储所述处理器可执行指令的存储器;
81、所述处理器,用于从所述存储器中读取所述可执行指令,并执行所述可执行指令以实现上述的方法步骤。
82、第四方面,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序用于执行上述的方法。
83、与现有技术相比,本发明具有以下优点:(1)通过获取并识别用户语音信息,根据语音识别结果匹配表盘背景生成模型,并分析用户需求利用选择的表盘背景生成模型生成表盘,本发明不需要复杂的页面操作及设置,就可以根据用户的需求智能生成表盘,用户的使用体验非常好,操作简单,生成的表盘完全贴合用户需要;(2)将语音识别后的关键词文本信息按照预设次数输入相匹配的表盘背景图片模型中,得到多个中间表盘背景图片构成的集合,将集合中的所有图片进行图像融合,生成第一表盘背景图片,上述操作采用多个图像融合的结果来生成表盘背景图片,避免了单次语音识别关键词出现小概率错误的问题,可以大大提高输出结果的可靠性及稳定性;(3)对生成的第一表盘背景图片进行了图像压缩和亮度调整,使得其尺寸和画质满足智能穿戴设备的要求,避免因图片太大占用设备内存而导致的画面卡顿,从而使得操作和界面更加流畅。
- 还没有人留言评论。精彩留言会获得点赞!