基于课程学习和深度学习的图像标注方法及装置
本发明涉及图像标注的,特别涉及一种基于课程学习和深度学习的图像标注方法及装置。
背景技术:
1、随着信息技术的快速发展,信息产生渠道日益多元化,数据的爆炸式增长为各行业领域高质量发展带来了丰富的数据支撑。如何从繁杂的数据中分析出高价值模式信息是各行业高质量发展的前提。图像数据是各行业产生最多,最常见的数据类型之一。然而,各行业产生的原始图像往往缺少标签信息。此外,由于人工标注带来的成本限制和主观操作因素,以无监督为特点的数据聚类成为图像数据标注的重要方法之一。
2、作为人工智能、机器学习、数据挖掘、模式识别领域中的关键技术之一,聚类算法旨在将目标数据(如图像、文本等)划分为不同的群组,使同一群组的数据之间具有高度的同质性,而不同群组的数据具有最大的差异性。这样可以快速约减原始数据间的冗余和无用信息,揭示出数据潜在的模式或结构,进而实现无监督的数据分类。
3、面对高维度、大规模的复杂数据时,传统聚类方法通常难以实现较高的聚类精度。这主要归因于在处理图像等复杂数据时,算法受限于诸如维度诅咒、人工设计的特征以及低质量相似性度量等固有问题。此外,传统算法所依赖的基于cpu的计算平台,对于图片数据的处理效率并不理想。最近,结合深度学习的聚类范式(称为深度聚类:dc)获得了很多关注,因为它弥补了传统聚类方法和高维数据之间的差距。深度聚类算法是一种结合了深度学习与聚类技术的无监督学习方法。它旨在学习数据的底层特征表示,并将其映射到一个低维空间,以便在该空间中执行聚类操作。相较于传统聚类方法,如k-means、dbscan等,深度聚类算法能更有效地处理复杂的非线性数据结构,具有更强的泛化能力。
4、课程学习是一种有前景的机器学习方法,它集中于当前数据的固有属性,避免了对外部数据或监督信息的依赖,同时最大限度地减少了计算资源的消耗。由于课程学习具有加快模型收敛和提高算法鲁棒性的潜力。
技术实现思路
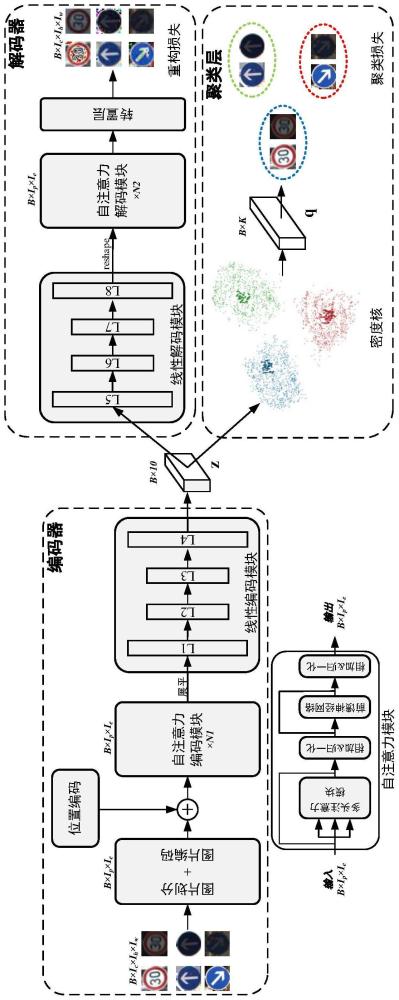
1、本发明的主要目的在于克服现有技术的缺点与不足,提供一种基于课程学习和深度学习的图像标注方法及装置。本发明设计了一种自编码器,通过包括计算难度分数、课程生成和基于密度核的聚类划分的微调训练,提出了一种新的图像标注方法,最大限度地减少了计算资源的消耗,同时加快模型收敛和提高算法鲁棒性。
2、为了达到上述目的,本发明采用以下技术方案:
3、第一方面,本发明提供了一种基于课程学习和深度学习的图像标注方法,包括以下步骤:
4、获取并预处理无标签图片,形成数据集;
5、构建自编码器,利用数据集转换成嵌入空间的嵌入特征并对自编码器进行预训练;所述自编码器包括编码器的图片划分与编码模块、自注意力编码模块和线性编码模块,解码器的线性解码模块、自注意力模块和转置层。所述的转置层将特征恢复为原始数据的形状;
6、利用聚类层,对自编码器进行微调训练,得到训练好的自编码器并聚类嵌入特征;具体为:计算嵌入特征的密度和难度分数;初始使用kmeans对嵌入特征进行预划分,计算选取样本的比例,并根据难度分数迭代计算簇内嵌入特征的降序排列和簇内每个样本的指示变量,获取训练集;根据设定的密度核选取比例迭代计算嵌入特征的簇密度核,并预测簇分配概率,形成软标签分布,聚类嵌入特征,聚类结果的变化小于阈值时迭代终止;迭代计算训练集的损失并反向传播训练自编码器,得到训练好的自编码器;
7、根据嵌入特征的聚类结果,利用训练好的自编码器找到每个簇对应的密度核,并根据密度核确认标签类别,获取图像标注结果。
8、作为优选的技术方案,所述利用数据集转换成嵌入空间的嵌入特征并对自编码器进行预训练,具体为,
9、利用补丁编码层将维度为ic*ih*iw数据集转换成维度为ip*ie的补丁编码,其中ic表示图片的通道数,ih表示图片的高度,iw表示图片的宽度,ip表示补丁编码的个数,ie表示补丁编码的尺寸;
10、通过自注意力模块和绝对位置编码对补丁编码进行编译,而后通过线性块将补丁编码转换为嵌入空间中的嵌入特征z={z1,z2,…,zn},其中且i=1,…,n,d表示嵌入空间的维度,i表示第i个样本,n表示嵌入特征个数,x表示数据集中的图像块,fw(·)表示编码器;
11、经过解码器的转置层得到输出结果;
12、计算输出结果的损失,并对自编码器进行训练。
13、作为优选的技术方案,所述计算嵌入特征的密度和难度分数,具体为,
14、利用数据集x继续换嵌入特征密度ρi,
15、
16、其中dc是密度计算的抽样半径,j表示第j个样本;
17、根据嵌入特征密度ρi计算难度分数δi
18、
19、
20、其中j′表示第j′个样本,λ1表示密度采样半径dc对应的比例。
21、作为优选的技术方案,所述计算选取样本的比例,并根据难度分数迭代计算簇内嵌入特征的降序排列和簇内每个样本的指示变量,获取训练集,具体为,
22、计算选取样本的比例ζiter,如下式:
23、
24、t=iter
25、其中t表示迭代轮次,iter表示实际迭代轮次,ζ0表示选取样本的初始比例,tgrow表示编码器第一次达到100%的数值所需的迭代次数,ζmax表示控制选取样本的最大比例;
26、根据难度分数迭代计算嵌入特征的簇降序排列,并计算嵌入特征的簇内每个样本的指示变量如下式:
27、
28、t=iter
29、其中ck代表从第(t-1)次迭代的结果中产生的第k个簇,表示xi在第t次迭代中的难度分数,是一个有序序列,是簇ck中对应于ζt位置处的值;
30、获取训练集如下式:
31、
32、作为优选的技术方案,所述根据设定的密度核选取比例迭代计算嵌入特征的簇密度核,并预测簇分配概率,形成软标签分布,聚类嵌入特征,聚类结果的变化小于阈值时迭代终止,具体为,
33、根据设定的密度核选取比例λ2,计算嵌入特征的簇密度核如下式:
34、
35、其中i表示第i个样本,ρi表示第i个样本在嵌入特征空间中的局部密度,表示簇ck内所有样本的密度值降序序列中λ2位置的值,k表示嵌入特征的簇的数量;
36、利用学生t分布来预测簇分配概率qik,如下式:
37、
38、其中j表示第j个样本;
39、形成软标签分布,并将嵌入特征进行聚类,得到聚类结果y,如下式:
40、
41、其中n表示嵌入特征个数;
42、迭代上述步骤,当连续两次聚类结果y的变化小于阈值μ,迭代终止。
43、作为优选的技术方案,还包括一个辅助目标变量pik来反复完善模型的预测,,如下式:
44、
45、作为优选的技术方案,所述迭代计算训练集的损失并反向传播训练自编码器,具体为,
46、利用训练集计算聚类损失重构损失和总体损失lt,如下式:
47、
48、
49、
50、其中t表示迭代次数,kl(·)表示聚类分配矩阵和辅助分布矩阵之间的散度,p表示辅助分布矩阵,q表示聚类分配矩阵,fw(·)表示编码器映射函数,gu(·)表示解码器映射函数,α表示重构损失的权重;
51、更新训练集并反向传播训练自编码器。第二方面,本发明提供了一种基于课程学习和深度学习的图像标注系统,应用于所述的基于课程学习和深度学习的图像标注方法,包括图像采集模块,模型构建模块,微调训练模块和图像标注模块;
52、所述图像采集模块获取并预处理无标签图片,形成数据集;
53、所述模型构建模块构建自编码器,利用数据集转换成嵌入空间的嵌入特征并对自编码器进行预训练;所述自编码器包括编码器的图片划分与编码模块、自注意力编码模块和线性编码模块,解码器的线性解码模块、自注意力模块和转置层;所述的转置层将特征恢复为原始数据的形状;
54、所述微调训练模块利用聚类层,对自编码器进行微调训练,得到训练好的自编码器并聚类嵌入特征;具体为:计算嵌入特征的密度和难度分数;初始使用kmeans对嵌入特征进行预划分,计算选取样本的比例,并根据难度分数迭代计算簇内嵌入特征的降序排列和簇内每个样本的指示变量,获取训练集;根据设定的密度核选取比例迭代计算嵌入特征的簇密度核,并预测簇分配概率,形成软标签分布,聚类嵌入特征,聚类结果的变化小于阈值时迭代终止;迭代计算训练集的损失并反向传播训练自编码器,得到训练好的自编码器;
55、所述图像标注模块根据嵌入特征的聚类结果,利用训练好的自编码器找到每个簇对应的密度核,并根据密度核确认标签类别,获取图像标注结果。
56、第三方面,本发明提供了一种电子设备,所述电子设备包括:
57、至少一个处理器;以及,
58、与所述至少一个处理器通信连接的存储器;其中,
59、所述存储器存储有可被所述至少一个处理器执行的计算机程序指令,所述计算机程序指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行所述的基于课程学习和深度学习的图像标注方法。
60、第四方面,本发明提供了一种计算机可读存储介质,存储有程序,所述程序被处理器执行时,实现所述的基于课程学习和深度学习的图像标注方法。
61、本发明与现有技术相比,具有如下优点和有益效果:
62、(1)本发明提出了一种基于密度核的聚类划分方法,根据设定的密度核选取比例迭代计算嵌入特征的簇密度核,并预测簇分配概率,形成软标签分布,聚类嵌入特征,从而取得了最好的聚类表现;
63、(2)本发明提出了基于自注意力模块的自编码器,通过包括计算难度分数、课程生成和基于密度核的聚类划分的微调训练,最大限度地减少了计算资源的消耗,同时加快模型收敛和提高算法鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!