一种基于条件扩散模型的仅标签模型逆向攻击方法
本发明属于数据隐私安全领域,特别涉及一种基于条件扩散模型的仅标签模型逆向攻击方法。
背景技术:
1、深度学习在政务、金融、人脸、指纹识别及生物医学诊断等领域已有广泛地落地探索和应用,构建这样的深度学习模型需要大量的训练数据,而这些数据会包含敏感信息,例如人脸图像等。研究表明模型往往会记住训练数据,因此深度学习存在的安全问题日益凸显。
2、模型逆向攻击(model inversion attack)是一种针对人工智能算法数据隐私的重要攻击方法,攻击者利用机器学习系统提供的一些api(如模型输出、参数更新等)来获取模型的一些初步信息,并通过这些初步信息对模型进行逆向分析,获取模型内部的一些隐私数据。例如,可以通过面部识别模型恢复训练集中目标个体的面部图像,类似地,可以通过面部识别模型生成的预测向量来重建输入的面部图像;或者可以通过医学预测模型推断个体基因组的敏感属性。
3、近几年来,一些学者基于生成对抗网络(generative adversarial networks,gan)和自编码器(auto-encoder,ae)等深度学习技术提出了一些模型逆向攻击方法。然而,现有的模型逆向攻击方法仍然存在一些不足,例如si.chen等人发表的knowledge-enriched distributional model inversion attacks文章提出一种白盒访问权限下通过软标签指导训练gan的模型逆向攻击方法,该方法训练攻击模型耗时长,难以实现迁移,且假设太过强烈,不符合实际情况;yang ziqi等人发表的neural network inversion inadversarial setting via background knowledge alignment文章提出基于ae框架的反向模型,在黑盒访问权限下从预测向量中成功恢复出了隐私的训练集,该方法需要对目标模型多次访问,生成图像分类准确率较低,真实性较差且面部轮廓不清晰;tianqing zhu等人发表的label-only model inversion attacks:attack with the least information文章提出利用最少信息来实现模型逆向攻击的方法,作者在仅标签访问权限下通过训练影子模型恢复置信度向量,进而训练反向模型进行攻击,该方法与本发明攻击者访问权限相同,但是需要多次优化且生成图片可识别性较差,此外,以上三种攻击方法仅能针对特定目标生成唯一的代表性图像,不利于后续的研究分析。
技术实现思路
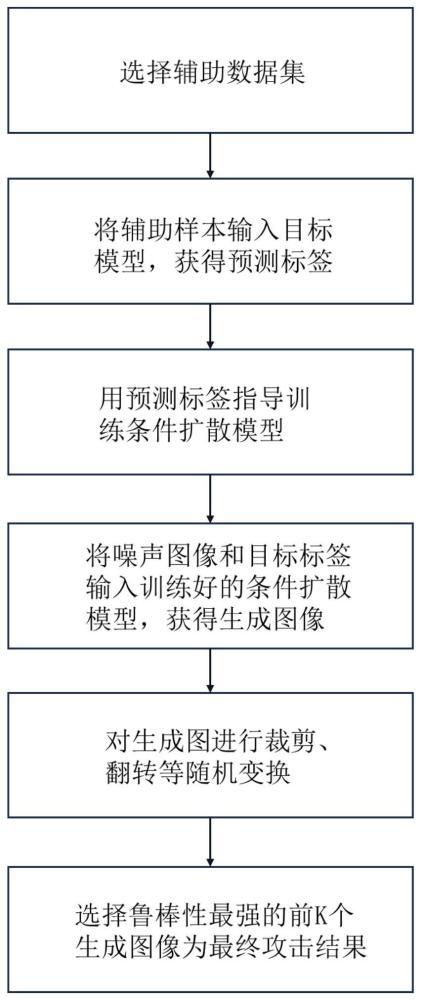
1、针对现有方法存在的不足,本发明提供一种基于条件扩散模型的仅标签模型逆向攻击方法,考虑了实际深度学习模型应用场景下,攻击者采用模型逆向攻击方法窃取用户隐私数据的安全问题,解决了以往方法受限于生成模型能力、优化算法而造成的生成图像单一、相似度低等问题,提高了生成图像准确率、真实性、相似度且增加了生成图像数量。具体来说是:首先获取待攻击目标模型的仅标签访问权限;选择辅助数据集;获取目标标签;获取辅助样本的预测标签;将目标模型的预测标签用作引导扩散模型训练过程的条件,指导扩散模型在向前扩散和向后预测的过程中学习到添加在预测目标上的噪声分布;将目标标签、随机标准正态分布的噪声以及预定义的指导强度输入训练好的条件扩散模型,获得多个跟目标标签对应的生成图像,并对生成图像进行伽马校正;通过随机变换筛选出鲁棒性较强的生成图像,本发明解决了先前模型逆向攻击生成图像相似度差且数量单一的问题,在面对仅目标模型预测标签的条件下也能对其训练图像进行窃取。
2、为了解决上述技术问题,本发明的技术方案为:一种基于条件扩散模型的仅标签模型逆向攻击方法,包括如下步骤:
3、s1、获取待攻击目标模型的仅标签访问权限:所述待攻击目标模型已使用隐私图像训练完成,具备图像分类功能,隐私图像保密,所述仅标签访问权限仅限于查询目标模型对输入图像的分类结果;
4、s2、选择辅助数据集:所述辅助数据集指与目标模型任务相关的辅助数据集,例如目标模型为人脸识别模型,辅助数据集则选择人脸数据集;
5、s3、获取目标标签:所述目标标签为目标模型对隐私图像的分类结果;
6、s4、获取辅助样本的预测标签:所述辅助样本的预测标签为目标模型对辅助数据集样本的分类结果;
7、s5、训练攻击用的条件扩散模型:所述条件扩散模型采用u-net模型,其训练过程分为前向扩散和后向预测,前向扩散执行加噪,后向预测执行去噪。在前向扩散期间,对辅助样本添加高斯噪声,共重复t次,最终得到标准正态分布的噪声,因此添加t次噪声后获得的噪声数据可以直接从原始数据中派生。在后向预测期间,使用u-net模型对前向扩散添加的噪声进行预测,随机选择1到t之间的时间戳,计算真实高斯噪声与从原始数据到噪声数据添加噪声之间的损失,为了确保训练受到预测标签指导,对每个步骤的时间戳添加了编码标签,使得扩散模型能够学到添加到预测标签的噪声分布;
8、s6、获得多个特定目标的生成图像:将多个标准正态分布噪声的图像、目标标签以及指导强度输入到训练好的条件扩散模型,获得多个跟目标标签对应的生成图像,并对生成图像进行伽马校正;
9、s7、结果输出:对校正后的生成图像进行随机变换,并输入目标模型进行预测,重复m次,选择鲁棒性最强的前k个生成图像为最终结果输出。
10、进一步的,步骤s5中,训练条件扩散模型分为两个过程,前向扩散过程,执行t步加噪,将原始图像转变为标准正态分布的噪声;后向预测过程,利用预测标签对前向扩散添加的噪声进行预测,具体步骤如下:
11、s5.1、设定扩散步数t和高斯噪声参数β0,β1,…,βt;
12、s5.2、根据当前扩散步骤t计算扩散系数
13、s5.3、输入辅助样本x0∈daux,计算第t步扩散的加噪输出其中ε表示噪声,n(0,i)表示标准高斯分布;
14、s5.4、使用u-net模型进行预测,输入xt,预测x0到xt的噪声εθ(xt,t);
15、s5.5、计算预测噪声和随机高斯噪声之间的均方误差mse损失,如下所示:
16、
17、其中ε表示从0到t次添加的高斯噪声,εθ为预测噪声,θ表示目标模型的参数;
18、s5.6、计算在嵌入s2的预测标签fw(x0)的时间戳t下的预测噪声和随机高斯噪声之间的mse损失,如下所示:
19、
20、其中时间戳t使用transformer中的position_encoding()函数将时间编码到预设的维度,同时预测标签fw(x0)也使用embedding()函数将维度转换成预设的维度;
21、s5.7、迭代优化真实高斯噪声和从x0到xt的预测噪声之间的损失,最终得到训练好的条件扩散模型gθ,优化目标如下:
22、
23、其中预测标签以一定概率p不引导扩散模型训练。
24、进一步的,步骤s6中,获得多个特定目标的生成图像,具体步骤如下:
25、s6.1、将目标标签l和噪声图像z输入到训练好的扩散模型gθ中,得到预测噪声如下:
26、
27、其中ω表示目标标签l的指导强度,xt为第t轮的噪声图像;
28、s6.2、利用预测噪声对噪声图像逐步去噪,公式如下:
29、
30、s6.3、迭代t轮后,得到多个目标标签的代表性生成图像gθ(z),其中t轮与s5中加噪的次数一致;
31、s6.4、对生成的图像进行伽马校正,即gθ(z)→a·gθ(z)γ,以调整其匹配人眼的感知,其中参数a通常为1,γ=2.2。
32、进一步的,步骤s7中,对生成图像进行随机变换并输出鲁棒性最强的前k个生成图像作为最终结果,具体步骤如下:
33、s7.1、以一定概率随机剪裁和垂直或水平翻转gθ(z)γ,即gθ(z)γ→t(gθ(z)γ),t(·)为随机变换函数;
34、s7.2、将转换后的生成图像t(gθ(z)γ)输入目标模型fw进行预测,这个过程重复m次;
35、s7.3、计算每个生成图像的代表权重,如下所示:
36、
37、其中,δ函数在其输入相等时返回1,不同时返回0;
38、s7.4、选择前k个最大代表权重对应的生成图像gθ(z)γ,即最终输出。
39、与现有技术相比,本发明优点在于:
40、(1)本发明是第一个在仅标签访问权限下,针对模型逆向攻击开发实用且强大的攻击模型。本发明使用的攻击方法基于条件扩散模型,能够有效恢复标模型训练集中的隐私图像,同时与现有的模型逆向攻击方法相比,本发明生成的图像更准确、更逼真、更相似。
41、(2)本发明攻击者的能力假设更贴近实际,更具有现实意义。与以往的白盒访问权限和基于置信度向量的黑盒访问权限相比,本发明中在攻击者仅能获取目标模型的预测标签的情况下,攻击模型效果超越现有的黑盒攻击,比拟现有最先进的白盒攻击。
42、(3)本发明提出的攻击方法针对目标标签能够生成多张图像,且不需要对生成的图像进行再优化。现有的模型逆向攻击方法需要对生成图像进行再优化才能达到攻击效果,而本发明只需要对生成的多张图像进行随机变换再筛选,就可以达到较高的攻击效果。
- 还没有人留言评论。精彩留言会获得点赞!