基于中文考古报告的信息提取管理分析综合数据库系统
本发明涉及数据管理系统,更具体地说,它涉及基于中文考古报告的信息提取管理分析综合数据库系统。
背景技术:
1、在考古工作中,资料的整理、统计、分析以及各类文物的管理是一项烦杂的工作,需要耗费大量的人力、物力,即便这样仍然不能迅速、全面掌握资料的情况。如果将数据库技术引入到考古工作中,不仅能大大简便资料整理工作,而且能够把整个考古工作的规划、管理、进度纳入到一个系统事务中,将工作的准备、实行、整理、研究变成一个紧密衔接的流程。
2、近年来随着信息技术的发展,考古学相关的大型数据库的建立的需求与日俱增。大型考古数据库的建设能够大大提高考古学研究的效率,拓展考古学研究的视角。在传统的考古学研究中,研究者往往需要基于经验认识对不同遗址的遗物进行对比与分析。而基于大型量化考古数据库的研究则可以将在更大的时空尺度上进行遗址间、遗物间的横向、纵向对比,以揭露那些仅凭经验无法把握的关于古代社会的规律。
3、目前,这类方法也已经逐渐成为近年来全球范围内考古学研究的新潮流,2021年martine robbeets等数十位语言学家、遗传学家、考古学家联合在《自然》杂志上发表了triangulation supports agricultural spread of the transeurasian languages(三重证据共同揭示泛欧亚语随农业的传播)一文。在文中基于252个来自中日韩俄四国的考古遗址的172个离散考古特征基于蒙特卡洛马尔科夫链方法首次构建了考古学文化的贝叶斯系统发育树。这一将生物学方法与考古学的结合的成功为后续考古学数据库的建设提供了一个良好的范例:即考古量化数据库的建设更应该基于后续的研究目的与研究方法设计,而非仅仅是发掘过程所有记录材料的无意识堆砌。
4、这类新的数据库系统可以被称为“量化考古数据库系统”,相比与传统的考古数据库其特点可以概况为以下两点:1)数据量大,包括大时空范围的大量考古遗址信息,而非某一特定地区或某一特定时段的考古遗址;2)数据的录入与导出的格式便于后续的数据分析,往往以表格而非图片、文本的形式存储。
5、但是现有的数据库系统还存在以下技术问题:
6、1、目前的数据库系统缺少自动化的考古信息提取流程
7、目前在未出现以中文为基础的量化考古数据库系统供研究者使用,传统的数据库建设往往仍然依靠人力从考古报告中收集信息。
8、2、目前的数据库系统还缺少统一格式与数据类型的数据库框架
9、目前在国际上的考古数据库系统往往以自下而上的方式组织,主要的数据来源是研究者共享的田野资料。因此存在数据类型、格式不统一,数据质量参差不齐的问题,难以对不同遗址的考古数据进行合并分析。
10、3、目前的数据库系统缺少问题导向的信息提取与数据分析模块的嵌入
11、目前的考古数据库系统主要目的是共享田野发掘的一手资料,并不存在实际的科学问题,量化的研究方法也往往与数据库系统本身脱节。
技术实现思路
1、本发明的目的是提供基于中文考古报告的信息提取管理分析综合数据库系统,该系统以中文考古报告为基础,同时包括信息提取、信息存储与数据分析全流程的综合考古信息数据库系统。
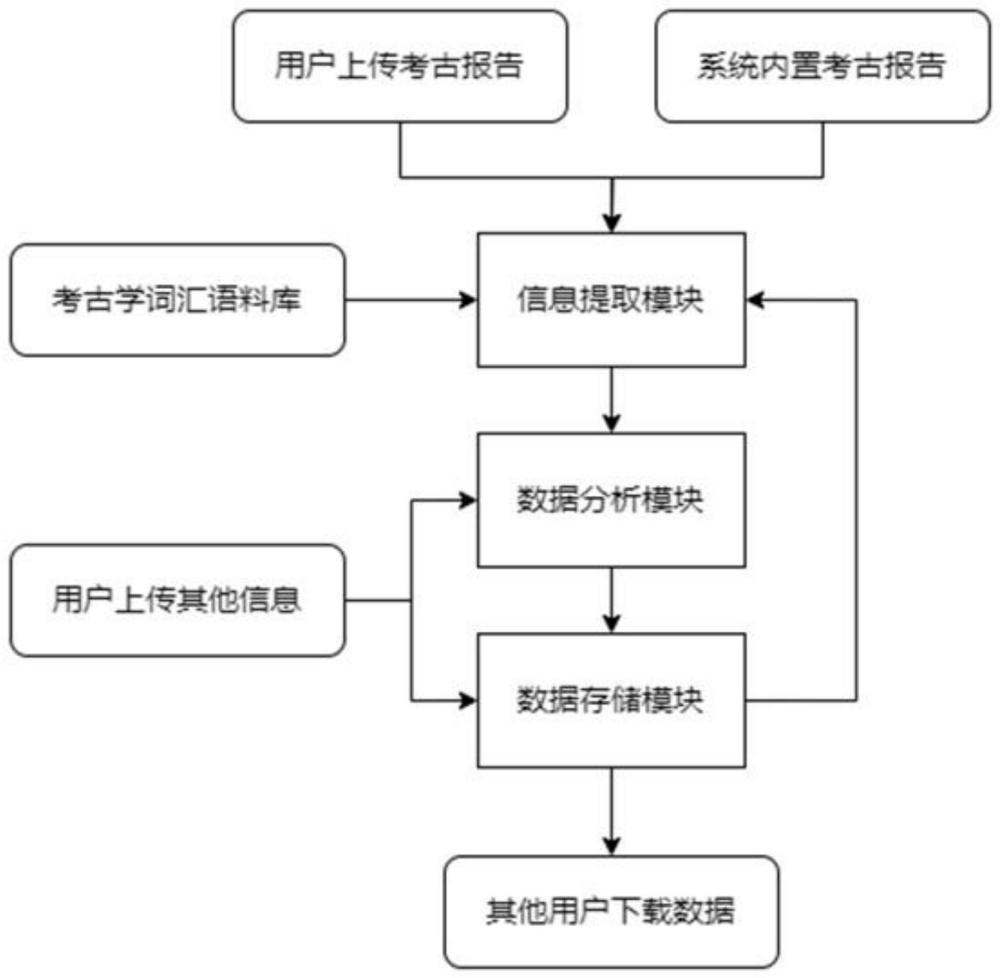
2、本发明的上述技术目的是通过以下技术方案得以实现的:基于中文考古报告的信息提取管理分析综合数据库系统,包括信息提取模块、数据分析模块和数据存储模块;
3、所述信息提取模块用于对图片分割、文本处理和特征提取;
4、所述数据分析模块用于对信息进行预处理并对信息分析;
5、所述数据存储模块用于将数据分析模块中分析的信息以及信息提取模块中提取的信息进行分类存储并且能够进行数据搜索;所述分类存储采用三级目录索引的形式存储;
6、所述数据分析模块中对信息预处理包括图片信息预处理和文本信息预处理;
7、所述信息分析包括椭圆傅里叶分析、单遗址层面分析和多遗址层面分析;
8、所述单遗址层面分析包括遗物与遗物间关系分析、特征与特征间关系分析和遗物与特征间关系分析;
9、所述遗物与遗物间关系分析方式是:利用k-means聚类算法来对遗址内出土遗物整体进行分类;
10、所述特征与特征间关系分析方式是:采用fisher精确检验功能检验二者之间的相关性的选项、point-biserial相关系数计算与统计检验的选项和pearson相关系数计算与统计检验的选项来得出离散特征和连续特征之间的相关性;
11、所述遗物与特征间的关系分析方式是:利用主成分分析对图片与离散特征进行降维,并根据主成分方差解释度计算特征权重来评估不同考古特征分类效率;
12、所述多遗址层面分析包括文化因素分析和br系数计算;
13、所述文化因素分析的分析方式是:首先选择一个遗址中具有典型文化意义且保存情况好的器物群用于检验,同时剔除缺失器物;随后从数据库系统中选择用以对比的考古学文化,最后将设置的遗址器物群中的每一件器物进行文化归属的判别。
14、所述br系数计算用于帮助用户快速获得该遗址与周边遗址之间的文化相似度,并以热图的形式直观展示该遗址的文化地缘关系;
15、进一步的,所述图片信息预处理的具体方法是:
16、s1:将信息提取模块输出的png格式的二值化遗物线图转化为jpg格式后,利用孔隙填充算法将线图内部填充以提高轮廓识别准确率,最后将处理过的图片批量读入基于r语言的图片处理板块;
17、s2:由用户设定阈值后利用图片解析器自动识别图片外轮廓,识别后的外轮廓为每个像素点的x、y坐标;
18、s3:在获得坐标后计算轮廓面积,再将所有轮廓按面积大小进行标准化处理;
19、进一步的,所述文本信息预处理的具体方法是:
20、s1:将信息提取模块输出的相似的量化考古特征基于用户分析的需要进行合并;
21、s2:对合并过的数据进行数据清洗。
22、进一步的,所述s2中数据清洗的具体方式是:滤除信息量少无法用于分析的特征。
23、进一步的,所述s2中所述数据清洗的具体方式是:通过设置过滤阈值,将出现频率低于设定阈值的特征进行剔除;剔除后使用原始数据直接用于分析,然后采用k近邻数据插补方法对缺失值进行补齐。
24、进一步的,所述文化归属的判别具体方式是:首先依次计算器物图片经椭圆傅里叶变换后系数与所有考古学文化遗址出土器物之间的距离;然后将所有距离排序,并基于设置的比例阈值进行文化属性判别。
25、进一步的,br系数计算的具体步骤是:首先计算两个遗址间每一特定陶器型式占遗址出土陶器总量;再对两个遗址该百分比之差的绝对值进行求和,校正后的br系数的区间为[0,1];然后用户对感兴趣的器物分类,并挑选需要比较的对比遗址;选择完成后数据分析模块计算目标遗址和所有对比遗址每类器物的相对丰度,并进行br系数计算,最终输出每个对比遗址与目标遗址的br系数向量。
26、进一步的,所述信息提取模块中图片分割的具体方式是:
27、s1:将考古报告pdf文件的每一页都转换为以array格式存储的图片进行分别处理;
28、s2:将图片转换为灰度图,并将其转换为黑色背景白色轮廓的二值图片;
29、s3:对于每一张二值图片,使用膨胀算法扩大其轮廓范围,以链接由于pdf清晰度或扫描精度问题造成的孔隙;
30、s4:基于二值图片像素点的连通性检测图片中的小区域,以剔除图片噪声和冗余信息;
31、s5:对提取后的图片进行一次闭运算封闭轮廓;
32、s6:对处理过的图片进行基于边缘的轮廓自动检测,并以轮廓的最外围x、y坐标作为矩形裁剪范围对图片进行自动切割并以压缩包的形式输出。
33、进一步的,所述信息提取模块中文本处理的具体方式是:
34、s1:将图片进行导入,使用正则表达式匹配其中的图例文本;
35、s2:将图例文本拆分为图片编号、器物名称与器物编号三类数据;
36、s3:在获得器物列表后,利用图号返回整个文本中提取该器物的描述信息。
37、进一步的,所述信息提取模块中特征提取的具体方式是:
38、s1:由用户指定器物编号列与描述列的位置,提取出包含每个器物原始描述信息的列;
39、s2:由用户充语料库中设置感兴趣的需要导出的特征,所述特征包括连续特征和离散特征;
40、s3:信息提取模块对对连续特征依据用户需要进行信息匹配,利用正则表达式抓取相关的数字字符信息与中文单位信息,然后对二者进行合并输出;同时利用正则表达式抓取离散特征,匹配成功赋值1,未匹配成功赋值0,并整理成表格输出最终csv格式的量化考古特征矩阵。
41、综上所述,本发明具有以下有益效果:
42、1、本系统信息提取的流程完全自动化,整个流程基于中国考古学界最普及、最权威的一种信息共享方式,大大提高了数据库建设的效率;
43、2、本系统采用自上而下的组织方式,基于自动化的提取流程大量从已发表考古报告中抓取信息作为数据库的基础,同时也同样支持用户上传新材料;
44、3、本系统作为问题导向的数据库平台,首次将数据分析模块整合进数据库框架当中,同时在分析方法上进行了一定的创新,将椭圆傅里叶轮廓分析、br系数计算、主成分分析、kmeans聚类等分析功能内嵌进系统中,可以帮助用户方便地分析考古数据,并将其数据置于考古大数据中进行研究;
45、4、采用椭圆傅里叶分析,能够最大程度减少运算量,同时相比于需要大量训练集的基于深度学习的图片分类算法而言大大提高了在小样本量情况下图片比较的准确性;因此,在数据存储模块的图片搜索系统也将基于傅里叶系数的距离计算进行,大大节省了服务器的空间,提高了检索效率与准确性。
- 还没有人留言评论。精彩留言会获得点赞!