一种节省存储空间的数据持续聚类方法、系统及存储介质与流程
本发明涉及数据聚类,尤其是一种节省存储空间的数据持续聚类方法、系统及存储介质。
背景技术:
1、在物联网时代,大量的传感器采集的数据需要进行人工智能的处理,其中数据的聚类是机器学习的基本处理方法之一,而受限于物联网设备的处理能力和存储空间,这些数据往往无法得到及时的存储和处理。
2、1、如中国专利公开了一种数据处理方法、装置、设备及计算机可读存储介质(公开号:cn113434471a),该方法包括:获取待处理的目标数据,所述目标数据包括若干数据项;基于聚类算法模型,将所述若干数据项分类到至少一个数据组中;根据每个所述数据组中当前包含的数据项,确定每个所述数据组的当前中心值;获取每个所述数据组的历史中心值,根据每个所述数据组的所述当前中心值和所述历史中心值,确定目标数据组;将所述目标数据组内的数据项存储至目标存储地址。能够保留历史数据的同时减少数据变化时占用的存储空间。本申请还涉及区块链技术,目标数据组可以存储在区块链中。
3、2、一种数据的聚类方法、系统及存储介质(公开号:cn113806610a),包括如下步骤:确定数据聚类条件;根据数据聚类条件对数据进行聚类得到至少一个第一聚类结果,并计算每一个第一聚类结果的熵载;所述熵载表示其对应的第一聚类结果所承载的平均信息量的大小;取各熵载中的最大熵载,其对应的第一聚类结果为数据聚类结果。本发明从整体数据出发进行聚类,实现了数据聚类的整体性,得到的聚类结果更加完整、准确;且聚类过程中不存在对任何特殊数据的依赖与处理、不限制任何数据种类,因此普遍适用于任何数据的聚类;采用最大承载平均信息量作为确定聚类结果的依据,对于存储空间一定的计算机系统,其所能存储的信息量也越大,提高了信息的表达效率
4、现有技术的聚类算法,能够有效的处理维度低,数量少的数据集,但是随着数据量增大,很多聚类算法从计算能力,内存消耗上都超出了普通计算机的能力,无法再进行处理。
5、目前的相关技术存在一定的问题:
6、1.在存储的过程中存在数据丢失、性能下降等问题;
7、2.传统的存储策略通过压缩、重删等技术来降低数据对空间的占用,但是,这些技术会降低用户的访问效率。
8、因此,对于上述问题有必要提出一种节省存储空间的数据持续聚类方法、系统及存储介质。
技术实现思路
1、针对上述现有技术中存在的不足,本发明的目的在于提供一种节省存储空间的数据持续聚类方法、系统及存储介质,以解决上述问题。
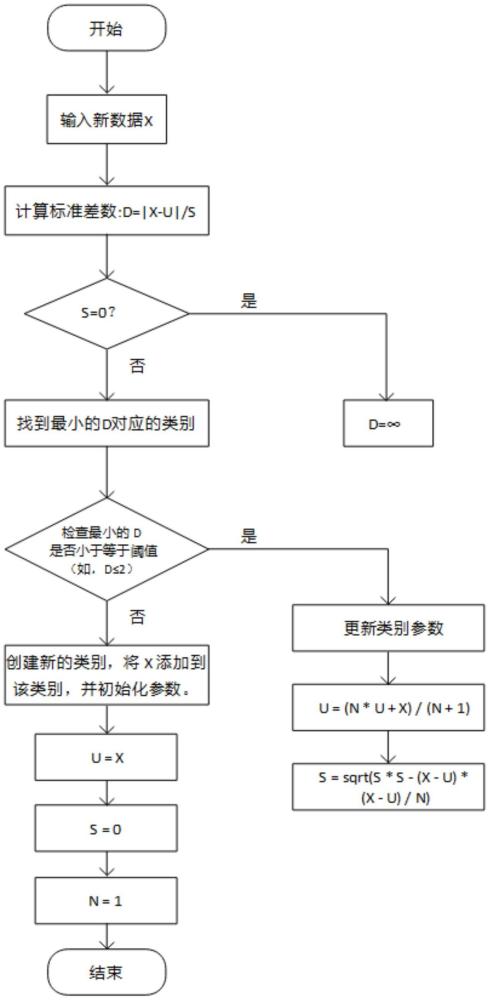
2、一种节省存储空间的数据持续聚类方法,其方法步骤为:
3、s1、对单个数据进行记录,新增并存储一个类别,记录类别参数;
4、s2、根据记录的若干个数据,进行循环与每个类别进行计算,计算标准差数并进行比较,找到最小的标准差数对应的类别;
5、s3、基于所得到的标准差数进行判断,若是如果标准差数≤2,则对当前的类别参数进行修改;
6、s4、新增一个类别,并对这个类别增加单个数据的记录。
7、其中步骤s1中的类别参数包括有平均值u、标准差s和数量n。
8、其中步骤s1类别参数的平均值=输入值,标准差s=0,数量n=1。
9、其中步骤1中的数据记录方法为:
10、s11、通过数据更新层将应用系统的记录数据封装为符合统一规范的数据包结构;
11、s12、通过消息处理层将所述数据包结构封装为统一格式的消息;
12、s13、通过接口处理层发送所述消息到指定的存储设备;
13、s14、取每一个数据包结构结果对应的熵载中的最大熵载,最大熵载对应的数据包结构结果为数据记录结果。
14、其中步骤s2的计算方法为:s21、计算标准差数d=|(x-u)/s|,如果s=0,则直接将结果记为d=∞;s22、比较各个类别的d,找到最小的d对应的类别;其中d为标准差数,x为数据,u为平均值;s为标准差。
15、其中步骤步骤s3的的标准差数的界限可以进行调整,可以根据实际需要进行调整。
16、其中步骤s3中的类别参数修改公式为:
17、
18、其中u为平均值,x为数据个数,s为标准差,n为数量。
19、其中标准差数的范围为0.1-3。
20、一种节省存储空间的数据持续聚类系统,所述系统包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的程序,所述程序被所述处理器执行时实现上述所述的聚类方法的步骤。
21、一种计算机可读存储介质,所述的存储介质存储有至少一个程序,所述至少一个程序可被至少一个处理器执行,所述至少一个程序被所述至少一个处理器执行时实现上述所述的数据持续聚类方法的步骤。
22、与现有技术相比,本发明有益效果:本发明适用于各种低性能、低存储环境下的持续的数据采集;实现了在低性能、低存储空间环境下,对持续输入的连续数据进行聚类并存储结果。
技术特征:
1.一种节省存储空间的数据持续聚类方法,其特征在于:其方法步骤为:
2.如权利要求1所述的一种节省存储空间的数据持续聚类方法,其特征在于:其中步骤s1中的类别参数包括有平均值u、标准差s和数量n。
3.如权利要求1所述的一种节省存储空间的数据持续聚类方法,其特征在于:其中步骤s1类别参数的平均值=输入值,标准差s=0,数量n=1。
4.如权利要求1所述的一种节省存储空间的数据持续聚类方法,其特征在于:其中步骤1中的数据记录方法为:
5.如权利要求1所述的一种节省存储空间的数据持续聚类方法,其特征在于:其中步骤s2的计算方法为:s21、计算标准差数d=|(x-u)/s|,如果s=0,则直接将结果记为d=∞;s22、比较各个类别的d,找到最小的d对应的类别;其中d为标准差数,x为数据,u为平均值;s为标准差。
6.如权利要求1所述的一种节省存储空间的数据持续聚类方法,其特征在于:其中步骤步骤s3的的标准差数的界限可以进行调整,可以根据实际需要进行调整。
7.如权利要求1所述的一种节省存储空间的数据持续聚类方法,其特征在于:其中步骤s3中的类别参数修改公式为:
8.如权利要求1所述的一种节省存储空间的数据持续聚类方法,其特征在于:其中标准差数的范围为0.1-3。
9.一种节省存储空间的数据持续聚类系统,其特征在于,所述系统包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的程序,所述程序被所述处理器执行时实现权利要求1-8任一项所述的聚类方法的步骤。
10.一种计算机可读存储介质,其特征在于:所述的存储介质存储有至少一个程序,所述至少一个程序可被至少一个处理器执行,所述至少一个程序被所述至少一个处理器执行时实现权利要求1-8任一项所述的数据持续聚类方法的步骤。
技术总结
本发明公开了一种节省存储空间的数据持续聚类方法、系统及存储介质,其方法步骤为;对单个数据进行记录,新增并存储一个类别,记录类别参数:根据记录的若干个数据X,进行循环与每个类别进行计算,计算标准差数并进行比较,找到最小的标准差数对应的类别;基于所得到的标准差数进行判断,若是如果标准差数≤2,则对当前的类别参数进行修改;新增一个类别,并对这个类别增加单个数据的记录。本发明有益效果:本发明适用于各种低性能、低存储环境下的持续的数据采集;实现了在低性能、低存储空间环境下,对持续输入的连续数据进行聚类并存储结果。
技术研发人员:武超,刘丹,欧阳新民,张浩,徐辉,霍磊,段增科,段超龙,胡涛,朱超,杨峰
受保护的技术使用者:中建三局总承包建设有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!