一种面向新闻报导的多场景AI辅助写稿方法
本发明涉及自然语言处理与跨模态内容生成,具体指一种面向新闻报导的多场景ai辅助写稿方法。
背景技术:
1、随着互联网基础设施的不断完善以及计算机技术的飞速发展,信息的获取与传递日益便捷,人们对新闻信息的丰富程度与时效性的要求也随之增长,以人力为主的传统新闻产线已难以满足读者需求。
2、当前新闻稿件的出产流程仍停留劳动密集型的“手工业”时代,其新闻稿件的出产流程大致可分为以下几个步骤:(1)新闻源获取。信息源一般来自前线记者或相关单位机构的发布信息。(2)新闻稿件编写。由相关文字工作者对信息进行整合与组织,形成新闻初稿。(3)新闻稿件审核。由相关专业审核人员对稿件语句及内容(如错别字、不当用词、敏感内容等)进行核查后发布。以上流程的主要缺陷如下:(1)缺乏时效性。传统新闻媒体通常需要一定的时间来采集、编辑和发布新闻。在信息时代,这种时间滞后性可能导致新闻内容过时,尤其是对于那些需要实时更新的事件。(2)信息片面性。由于有限的人力和时间,传统媒体可能只能提供事件的部分信息,而无法全面、深入地报道。这可能导致读者对事件的理解出现偏差。(3)效率低下。整个流程需要大量专业从业者,受限于人力成本,新闻生产效率难以提高。
3、近年来,得益于深度学习技术的飞速发展,一些预训练语言模型诸如bert(bidirectional encoder representations from transformers)以及gpt(generativepre-trained transformer)系列等相关语言模型被认为在处理文字工作上有着良好的表现。同时,多模态技术的飞速发展也打破了不同类型数据(如文本、图片、视频)之间的隔阂,例如clip(contrastive language-image pretraining)等能够将文本描述和图像内容联系起来,从而实现多模态任务。这些人工智能模型被认为在处理文字工作方面相较人类有以下优势:(1)在处理一些简单文字任务(如分类、翻译、摘要等)时其效率大大高于人类。(2)能够有效地处理大规模的数据,从海量资讯中快速提取有价值的信息。(3)在执行任务时非常一致,不会受到疲劳、情感或其他因素的影响,因此能够提供高质量和一致的结果。(4)ai系统可以轻松扩展到处理大规模任务,而扩充人力资源的时间与经济成本在当前较ai系统都更高。因此将人工智能技术与新闻报导场景进行深度结合是克服传统媒体上述弊端的有效方案。
4、相关技术中,写作素材的推荐基于文本关键字提取,未能考虑到新闻事件的连续性与不同新闻主体之间的关联性,所推荐的素材与新闻主体关系弱,只能作为文稿关键词的补充诠释,难以给予作者有效启示,无法拓展新闻稿的广度与深度。
5、现有相关辅助写作技术如cn106650943a等,多注重于文学创作方面(如词汇联想、语句润色、写作素材推荐等)的辅助,而针对新闻报导场景(包括多模态新闻素材推荐,新闻事件脉络查询,新闻主体事件图谱查询,短视频稿件自动成稿,针对新闻稿件的自动审核等)的ai写作辅助,目前尚未发现有效解决方案。
技术实现思路
1、本发明针对新闻写稿实际需求复杂和示范应用类型多的问题,提出一种面向新闻报导的多场景ai辅助写稿方法,实现高可扩展、多样化的写稿服务。
2、本发明的技术方案为:
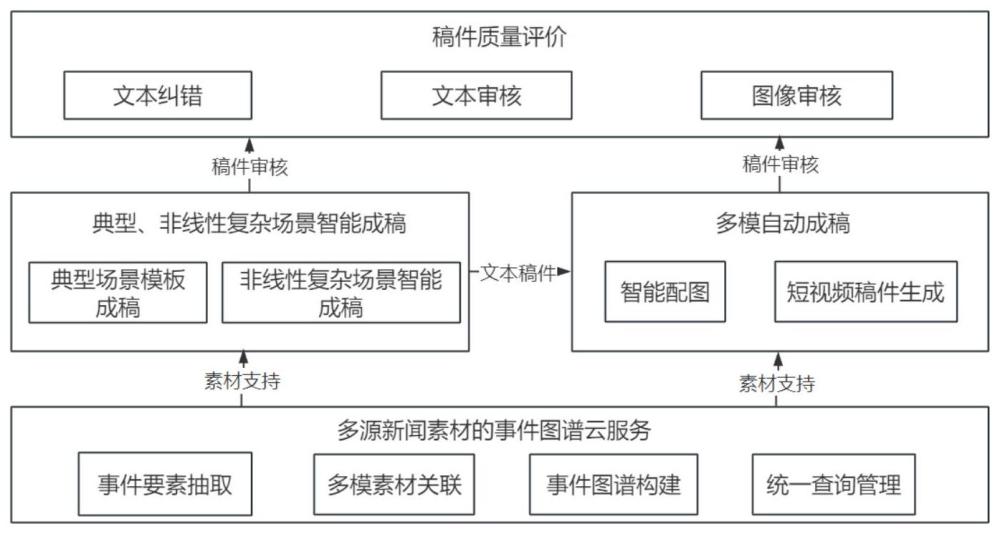
3、一种面向新闻报导的多场景ai辅助写稿方法,包括如下步骤:
4、s1、收集多源新闻素材,建立素材数据库,对新闻素材进行预处理。所述多源新闻素材包括文本素材、图片素材与视频素材。
5、s1-1、通过clip的文本编码器将每个图片素材转换为一个固定长度的图像嵌入向量;
6、s1-2、对视频素材进行关键帧提取,并通过clip的图像编码器将关键帧图像转换为一个固定长度的图像嵌入向量;
7、s1-3、使用开源知识图谱构建工具deepke,以deepke所提供的预训练bert模型为基础模型,训练实体抽取模型。
8、具体的,首先对文本稿件素材进行数据标注,构成足量的数据集。将标注完成的数据集划分为训练集、验证集与测试集;使用上述数据集迭代训练抽取模型。
9、s1-4、使用s1-3的实体抽取模型对新闻稿件素材进行实体关系抽取,得到“主体,关系,客体”三元组。以主、客体为结点,关系为边,构建实体关系图,并以“实体名-图结点”的形式在哈希表中存储进行存储,以实现通过实体名快速定位图结点。素材库将定期更新文稿素材并进行实体抽取与关系图更新,以维护事件图谱的时效性。
10、s1-5、以基于词频的方式,使用jieba分词提取文本素材关键词并进行记录,建立“关键字-文本素材”的对应关系。
11、s2、新闻报道场景选取,所述新闻报道场景包括典型场景和非线性复杂场景,其中典型场景包括天气预报、上市公司财报、房价趋势、每日基金播报、蔬菜价格趋势、汽车行情、体育新闻;非线性复杂场景指除典型场景外的,无法预设新闻报导稿件格式的场景,如重大事故、地区冲突等突发热点事件。
12、s3、新闻稿件ai辅助创作。
13、作为优选,当步骤s2中选取的是典型场景时,所述步骤s3的具体方法为:
14、s3-1-1.用户选取具体场景;所述典型场景包括天气预报、上市公司财报、房价趋势、每日基金播报、蔬菜价格趋势、汽车行情、体育新闻。
15、s3-1-2.根据s3-1-1用户所选场景,获取最新相关场景数据。具体的,使用基于beautifulsoup的网络爬虫工具定期对数据源进行数据抓取,并采用redis缓存技术提升多用户请求时的数据响应速度。将取得的数据依照类型填入预设模板空位,形成模板稿件,所述预设模板为文本形式;
16、s3-1-3.用户手动修改模板稿件,得到成稿;
17、s3-1-4.将成稿送交ai审核。具体的,利用百度ai开放平台所提供的文本、图像审核api对成稿进行审核,获取修改建议。用户若接受修改建议则返回s3-1-3。
18、作为优选,当步骤s2中选取的是非线性复杂场景,所述步骤s3的具体方法为:
19、s3-2-1.用户根据推送的热点、突发新闻事件,选择新闻创作主题。具体的,通过百度api实时热点接口获取热点新闻事件列表推送给用户。
20、s3-2-2.用户根据所选新闻主题,提交相应的提示语句,利用提示语句引导基于开源chatglm2-6b的预训练语言模型进行文本生成。
21、s3-2-3.利用事件图谱搜索新闻主体关联素材,查询与新闻主体关联度较高的相关主体辅助用户扩充稿件内容。
22、s3-2-4.利用预训练chatglm2-6b语言模型对文本稿件进行自动摘要、标题生成、标签生成,生成新闻初稿。
23、s3-2-5.得到新闻初稿后,用户选择最终成稿类型,进行多模稿件生成。可选择生成图文稿件或短视频稿件。
24、s3-2-6.用户手动修改图文稿件。
25、s3-2-7.若用户在s3-2-5中选择生成图文稿件,可将图文稿件送交ai审核。具体的,调用百度ai开放平台相关所提供的文本、图像审核api对成稿进行审核,获取审核建议。用户若接受修改建议则返回s3-2-6。
26、当步骤s2中选取的是非线性复杂场景,所述步骤s3还包括:s3-2-2通过语言模型自动生成稿件。
27、作为优选,自动稿件生成的方法为:用户根据所选新闻主题,提交相应的提示语句,所述提示词包括具体时间、地点、人物、事件等关键信息;使用jieba分词对提示句进行关键字提取;利用s1-5建立的对应关系,搜索关键字相关的稿件素材,并结合相关稿件素材与用户输入重新构建提示语句,引导基于开源chatglm2-6b的预训练语言模型进行文本生成。具体提示句构建模板为:“根据以下文章素材,以```用户输入提示句```为中心,写一篇不少于xxx字的新闻稿,并以关键字为[content]的json数据格式输出。[```文章素材1```,文章素材2```,……]”。
28、当步骤s2中选取的是非线性复杂场景,所述步骤s3还包括:s3-2-3使用基于事件图谱的新闻主体关联素材搜索。
29、作为优选,事件图谱的搜索方法为:使用s1-3训练的抽取模型对用户文稿进行实体抽取,获得相关实体;使用s1-4生成的结点哈希表查询相关实体所对应的关系图结点;在s1-4生成的实体关系图中,以欲查询实体对应的关系图结点为中心,r为半径,获取邻接实体结点,生成事件图谱;事件图谱经echarts组件渲染后,以可视化的形式呈现在用户界面,用户点击图中实体结点可直接跳转至相应百度百科界面;用户亦可根据新闻主体与相关实体的关系重新组织提示语句,以s3-2-2的方式重新生成文稿。
30、当步骤s2中选取的是非线性复杂场景,所述步骤s3还包括:s3-2-4通过语言模型对文本稿件进行自动摘要、标题生成、标签生成。
31、作为优选,自动摘要的方法为:构建提示语句引导预训练chatglm2-6b语言模型输出摘要。具体的,提示语句格式为:“对以下文章内容进行总结,并以关键字为[summary]的json数据格式输出。```具体文章内容```”。
32、作为优选,标题生成的方法为:构建提示语句引导预训练chatglm2-6b语言模型输出标题。具体的,提示语句格式为:“分析以下文章内容,给文章取x到x个标题,标题字数在x到x之间,并以关键字为[title]的json数据格式输出。```具体文章内容```”。
33、作为优选,标签生成的方法为:构建提示语句引导预训练chatglm2-6b语言模型输出标签。具体的,提示语句格式为:“分析以下文章内容,总结出x到x个关键词,并以关键字为[tag]的json数据格式输出。```具体文章内容```”。
34、当步骤s2中选取的是非线性复杂场景,所述步骤s3还包括:s3-2-5通过ai辅助创作生成图文稿件和短视频稿件。
35、作为优选,所述图文稿件的生成方法为:将初稿拆分为长度固定的段落,通过clip的文本编码器将每个段落转换为一个固定长度的文本嵌入向量;使用预训练clip模型对文本嵌入向量与s1-1所述的图像嵌入向量进行比对,找出匹配度最高的图像嵌入向量所对应的图像并将其置于相应文本段落后。
36、作为优选,所述短视频稿件的生成方法为:将初稿拆分为长度固定的段落,通过clip的文本编码器将每个段落转换为一个固定长度的文本嵌入向量;使用预训练clip模型对文本嵌入向量与s1-2所述的关键帧图像嵌入向量进行比对,找出匹配度最高的关键帧图像,在该帧附近剪辑截取视频片段并将对应分段文本通过tts(text-to-speech)模型转为音频嵌入到视频片段内,将所有文本分段对应生成的视频片段按顺序进行拼接后,得到最终短视频稿件。
37、本发明具有以下的特点和有益效果:
38、采用上述技术方案,本发明将人工智能技术与新闻成稿流程深度结合,在自然语言处理多模态技术的加持下,相较于传统新闻稿件人工编辑方式,使用本方法可较大幅度提升成稿效率,同时大大降低自媒体等非专业媒体的成稿门槛。其中典型场景的模板成稿功能令场景相对固定的日常新闻成稿快速化,自动化。新闻事件图谱与脉络的应用使得写作素材查询更加便捷,素材本身也更贴近新闻主体。自动文本摘要与标签生成功能免去了编辑繁杂的重复劳动。智能图文成稿缩减了冗长的新闻图片素材寻找过程,短视频成稿功能可使得不具备视频剪辑技能的用户一键生成短视频稿件。
- 还没有人留言评论。精彩留言会获得点赞!