基于生成对抗网络的代码生成与搜索方法、系统及存储介质
本发明主要涉及到代码生成和搜索,特指一种基于生成对抗网络的代码生成与搜索方法、系统及存储介质。
背景技术:
1、代码生成和代码搜索是将开发者的需求转换为源代码的两种有效方式,代码生成旨在生成新代码,代码搜索侧重于重用已有代码。
2、其中,代码生成主要是通过自动学习从自然语言到编程语言的转换,从零开始生成代码片段,一般是通过神经机器翻译模型实现的。因此,代码生成方式的关键能力是生成与人类开发人员编写的代码片段相似的代码片段。
3、代码搜索是通过映射代码和查询之间的语义相关性,从预先收集的代码库中检索代码片段。因此,代码搜索的关键在于准确理解不同代码片段的语义,从中选择最相关的代码片段。
4、近年来,基于深度学习领域的进展推动了这一领域的研究。例如,神经机器翻译技术的出现,使得代码生成可被看作是序列到序列的翻译任务;自然语言查询和代码段可被嵌入到高维向量空间中,从而进行相似度的匹配。
5、预训练技术同样引发了广泛关注。预训练是对大量未标记的数据进行自监督学习,从而使其可使用大数据领域的力量。
6、在一些与代码相关的任务上,预训练技术取得了比非预训练技术更好的表现。如,采用文本到文本转换器架构的codet5在代码生成上达到了最先进的状态,采用纯编码器架构的codebert在代码搜索任务上同样表现出优于非预训练技术的能力。
7、通常,代码生成和代码搜索是将自然语言描述转换成源代码的两种有效方式。以前的工作进行了一项用户研究,参与者被要求在代码生成或代码搜索技术的帮助下实现特定的功能,并展示了这两种类型的技术之间的互补性:在一些任务中,开发人员更喜欢代码生成而不是代码搜索,而在其他任务中则相反。这一发现促使探索一种结合这两种技术的方法。然而,这两个领域内的先前研究主要是分开研究的,并且将这两种类型的技术相结合的唯一现有方式是首先检索给定自然语言查询的代码片段,然后基于检索结果生成最终代码.这种方法主要有两个限制其应用场景的局限性。首先,他们通常假设方法的输入和输出是已知的,并且方法是部分编写的,而一般的代码生成技术旨在从头开始生成代码。其次,它们的有效性在很大程度上依赖于在检索语料库中是否存在类似于标准答案的代码,因此它们通常在简单的代码片段上进行评估。
8、有从业者提出一种co3模型方法(code search, code summarization, and codegeneration),co3模型方法是将代码生成和代码摘要两个任务结合起来,以提高它们性能。该方法是通过对偶学习显式地利用代码摘要和代码生成之间的概率相关性,用于代码摘要和代码生成的两个编码器通过多任务学习及代码检索打分器共享,最终得到简单有效的端到端模型co3。
9、co3模型提出了两个对偶任务,一个以源代码序列x为输入,并将其归纳为文本序列y’的原始代码摘要任务;以及以文本序列y为输入,并利用其生成代码序列x’的双代码生成任务。co3模型重用x和y分别监督x’和y’,通过对偶学习机制提高两个任务的性能,进而利用这两个任务的隐藏状态来促进和提高代码检索任务的性能。
10、其中,co3模型一般分为三个部分:
11、(1)代码摘要模块对代码序列进行编码,将其摘要成文本序列y’;
12、(2)代码生成模块对文本序列y进行编码,并利用其生成代码生成序列x’;
13、(3)代码检索模块计算代码摘要模块和代码生成模块的隐藏状态之间的相似度得分,然后根据得分检索匹配的源代码。
14、由上可知,co3模型的主要特点为:
15、(1)在代码摘要模块和代码生成模块之间添加限制,使用对偶学习的方法把它们连接起来,帮助捕获文本和代码更精确的表示;
16、(2)由于代码摘要模块和代码生成模块都对源代码进行处理,co3在代码摘要模块的编码器和代码生成模块的解码器之间、编码器之间分别共享参数,减少了模型参数的个数,构建了一个简单的模型co3。
17、但co3方法训练代码生成器与所有已有方法相同,没有明确的反馈信号。
18、为此,上述传统技术仍然存在一些不足之处:
19、1、代码生成的有效性有限;由于采用teaching forcing策略导致的曝光偏差问题,其生成的代码与开发者编写的代码并不相似。即:代码生成通常在训练阶段采用teaching forcing策略,其模型使用自身从前一时间步的预测输出作为输入,导致了曝光偏差问题,导致生成的代码与开发者编写的代码并不相似的问题。
20、2、代码搜索的有效性有限;由于用以训练的代码段数量有限,在实际应用中,开发者难以区分oracle代码和non-oracle代码,使得存在将生成的代码错误分类为非oracle代码的情况,进而影响其有效性。
21、3、现有技术难以高效地将开发者的自然语言转化为源代码。
技术实现思路
1、本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种原理简单、适用范围广、能够提高将自然语言转化为源代码效率的基于生成对抗网络的代码生成与搜索方法、系统及存储介质。
2、为解决上述技术问题,本发明采用以下技术方案:
3、一种基于生成对抗网络的代码生成与搜索方法,其包括:
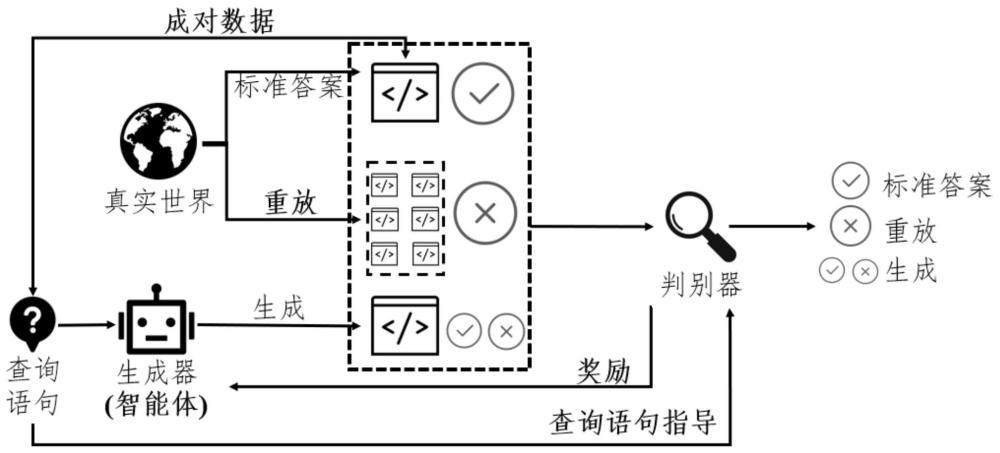
4、步骤s1:训练判别器:使用从真实世界中采样查询语句对模型进行训练,获取判别模型;所述判别器接收的是来自真实世界的代码片段,所述代码片段显式地实现了查询的预期功能;
5、步骤s2:训练生成器:对从步骤s1中获得的生成代码片段进行训练,获取生成模型;使用策略梯度并将生成器的训练建模为一个强化学习过程,生成器充当一个代理,并将判别器的反馈作为奖励信号来更新生成器的参数。
6、作为本发明方法的进一步改进:所述步骤s1中,在学习新任务的过程中从旧任务中抽取一些样本进行再训练,使得先前学习到的知识在模型中得以保持。
7、作为本发明方法的进一步改进:所述步骤s1中,根据代码片段与oracle代码在标记级的相似性,从训练集中选择代码片段作为重放样本。
8、作为本发明方法的进一步改进:所述查询被提供给判别器,用以指导识别真实世界的代码。
9、作为本发明方法的进一步改进:所述步骤s1的流程包括:
10、步骤s11:从(q)采样查询语句;其中,所述(q)为开发者使用的来自真实世界查询的分布;
11、步骤s12:获得开发者编写的相应代码片段,即oracle代码;
12、步骤s13:获取生成器生成的代码片段;
13、步骤s14:指定生成器生成代码片段的标签,即non-oracle或oracle;
14、步骤s15:对于每个获得的oracle代码片段,从代码语料库中随机抽取与预期功能不相关的混淆样本,这样的代码片段作为重放样本,使得判别器在代码搜索任务上的知识得以保留,同时最小化生成器和重放样本的分数。
15、作为本发明方法的进一步改进:还包括步骤s16:分别计算判别器赋予oracle代码、non-oracle代码与混淆样本的分数,并更新判别器参数。
16、作为本发明方法的进一步改进:所述步骤s2的流程包括:
17、步骤s21:从(q)采样查询语句;从给定的真实世界输入分布中采样m个查询{,, ... ,};
18、步骤s22:从生成器中获取生成的代码片段;对于给定从输入分布{,, ... ,}中的m个查询,生成器生成m个代码片段{,, ... ,};
19、步骤s23:计算每个生成代码片段从判别器获取的奖励值;
20、步骤s24:利用奖励值更新生成器的参数。
21、作为本发明方法的进一步改进:所述步骤s23的流程包括:
22、步骤s231:对于生成器生成m个代码片段{,, ... ,},根据以下公式计算其对应的奖励值:
23、
24、其中,表示生成器生成时获得的奖励,表示给定产生的概率;
25、步骤s232: 计算的梯度值:
26、
27、得到梯度值后,用梯度上升来更新生成器参数。
28、本发明进一步提供一种基于生成对抗网络的代码生成与搜索系统,其包括:
29、判别器,使用从真实世界中采样查询语句对模型进行训练,获取判别模型;所述判别器接收的是来自真实世界的代码片段,所述代码片段显式地实现了查询的预期功能;
30、生成器,对获得的生成代码片段进行训练,获取生成模型;使用策略梯度并将生成器的训练建模为一个强化学习过程,生成器充当一个代理,并将判别器的反馈作为奖励信号来更新生成器的参数。
31、本发明进一步提供一种存储介质,所述存储介质能够被计算机或处理器读取,所述存储介质中存储有用来执行上述任意一种方法的计算机程序。
32、与现有技术相比,本发明的优点就在于:
33、1、本发明的基于生成对抗网络的代码生成与搜索方法、系统及存储介质,原理简单、适用范围广、能够提高将自然语言转化为源代码效率、能够缓解代码生成得到的代码与开发者编写的代码并不相似的问题,使得代码搜索器能够准确理解代码片段的语义,从而避免潜在的错误标记。
34、2、本发明的基于生成对抗网络的代码生成与搜索方法、系统及存储介质,利用生成性对抗网络(gan),将代码生成与代码搜索结合起来,实现两种有效方法的优势互补。其中,代码生成器扮演生成器,其生成的代码可使得代码搜索者更精确地理解代码语义,代码搜索器作为判别器,其对代码质量的反馈可使得代码生成器生成的代码与人类编写的代码类似。此外,在生成性对抗网络中,生成器和判别器可同时得到增强。
35、3、本发明的基于生成对抗网络的代码生成与搜索方法、系统及存储介质,从生成器的角度来看,来自判别器的反馈迫使它更擅长于生成类似人类编写的代码。具体来说,生成器旨在欺骗判别器,使判别器给生成的样本分配更高的分数。在本发明中,代码生成器旨在让判别器相信它生成的代码是由人类开发人员编写的。然而,这是具有挑战性的,因为判别器已经接受了由人类开发人员编写的代码的训练,并且具有关于编程语言的常识。例如,判别器知道递归函数应该定义终止情况。因此,判别器可以很容易地识别任何违反人类开发人员编码实践的代码。因此,为了实现其目标,代码生成器应该学会生成不包含致命缺陷的代码,这些缺陷与人类开发人员的常见编码实践相矛盾。本发明就是以接收判别器的正反馈为目的,强化生成器在对抗过程中产生类似人类的代码,增强其关键能力。
36、4、本发明的基于生成对抗网络的代码生成与搜索方法、系统及存储介质,从判别器的角度来看,生成器生成的代码引导它更准确地捕获代码语义。具体来说,判别器的目的是区分真实样本和发生器产生的样本。在本发明中,当被生成的代码干扰时,代码搜索器需要准确地识别满足所请求功能的代码。这并非无关紧要,因为所生成的代码可能在代码标记方面类似于oracle,在对抗过程中,生成器将变得有能力生成类似于人类编写的代码,这意味着生成的代码不会违反常见的编码实践。因此,通过仅仅关注象征性的相似或矛盾来进行这种区分是不够的,代码搜索器还需要能够捕获代码语义之间的细微差别。通常来说,生成器在对抗过程中的进步会促使代码搜索器更好地捕获代码语义,最终增强代码搜索器的关键能力。
37、5、本发明的基于生成对抗网络的代码生成与搜索方法、系统及存储介质,将代码生成和代码搜索结合起来,以克服彼此的局限性:代码生成器需要对其生成的代码的质量进行反馈,这可以由代码搜索器提供,而代码搜索器需要更多的数据用于训练,这可以由代码生成器生成。本发明将编码生成器和编码搜索器分别视为gan框架中的生成器和鉴别器,并通过对抗训练过程来提高它们的性能,生成的代码生成器可以从头开始生成复杂的方法级代码。
- 还没有人留言评论。精彩留言会获得点赞!