异常检测模型训练、数据检测方法、装置、设备及介质与流程
本发明实施例涉及人工智能,尤其涉及一种异常检测模型训练、数据检测方法、装置、电子设备及存储介质。
背景技术:
1、随着互联网技术的快速发展,大规模数据中心的运维管理变得越来越复杂。在这种背景下,如何有效地检测和处理运维过程中的异常数据变得至关重要。
2、目前,大规模数据的异常检测算法主要分为三类:统计方法、机器学习方法和深度学习方法。其中,统计方法主要包括z分数法、箱线图法和自回归模型(autoregressiveintegrated moving average model,arima)三种类型。z分数法的检测思路为:基于数据集的均值和标准差计算z分数,通过比较z分数与设定的阈值来判断数据是否异常,该方法适用于正态分布的数据集。箱线图法的检测思路为:通过计算数据的最小值、第一四分位数(q1)、中位数(q2)、第三四分位数(q3)和最大值,构建箱线图。根据设定的iqr(interquartile range,四分位距)和异常倍数来判断数据是否异常,该方法适用于大多数数据分布。自回归模型的检测思路为:利用自回归模型对时间序列数据进行建模,通过比较预测值与实际值之间的差异来检测异常,该方法适用于具有一定趋势和季节性的时间序列数据。机器学习方法主要包括支持向量机(support vector machines,svm)、k-近邻(k-nearestneighbor,knn)、决策树以及聚类算法(如k-means)等。其中,支持向量机方法通过构建分类模型,将数据映射到高维空间,找到数据间的最大间隔。利用这个间隔,可以检测到距离中心较远的异常数据。k-近邻方法则需要计算数据点之间的距离,找到距离最近的k个邻居。通过计算新数据点与邻居的距离,判断其是否异常。决策树方法通过将数据集分成多个子集,根据特征值进行决策,构建一棵树形结构。可以利用决策树对数据进行分类,并检测出异常数据。聚类算法主要是将数据集划分为若干个类别,计算各类别的均值和标准差。通过比较新数据点与各类别的均值和标准差,判断其是否异常。深度学习方法主要包括自编码器(autoencoder,ae)、变分自编码器(variational autoencoder,vae)、循环神经网络(recurrent neural network,rnn)以及卷积神经网络(convolutional neuralnetworks,cnn)。其中,自编码器利用自编码器对正常数据进行建模,将数据映射为低维表示。当新数据出现时,通过比较其与正常数据的低维表示,判断其是否异常。变分自编码器与自编码器类似,但在生成过程中引入了随机变量。通过计算新数据点与正常数据的差异,判断其是否异常。循环神经网络利用循环神经网络对时间序列数据进行建模,通过比较新数据点与历史数据的相似性,判断其是否异常。卷积神经网络对图像数据进行建模,通过提取局部特征和空间关系,判断图像中的异常区域。
3、发明人在实现本发明的过程中,发现现有技术存在如下缺陷:随着业务的发展对于大型互联网公司或者aiops(artificial intelligence for it operations,即智能运维)技术提供商来说,需要监控的数据越来越多,监控大量的数据和检测异常情况以确保服务质量和可靠性是非常重要的。随着技术的发展常规的异常检测算法由于其天然的缺陷,逐渐被机器学习(深度学习)算法所替代。然而,由于模型选择、参数调优以及模型训练的资源的巨大开销,对数百万个以及越来越多的数据进行大规模异常检测模型训练具有非常大的挑战性。
技术实现思路
1、本发明实施例提供一种异常检测模型训练、数据检测方法、装置、设备及介质,能够降低异常检测模型训练所消耗的资源,提高异常检测模型的训练效率,进而提高数据检测的效率。
2、根据本发明的一方面,提供了一种异常检测模型训练方法,包括:
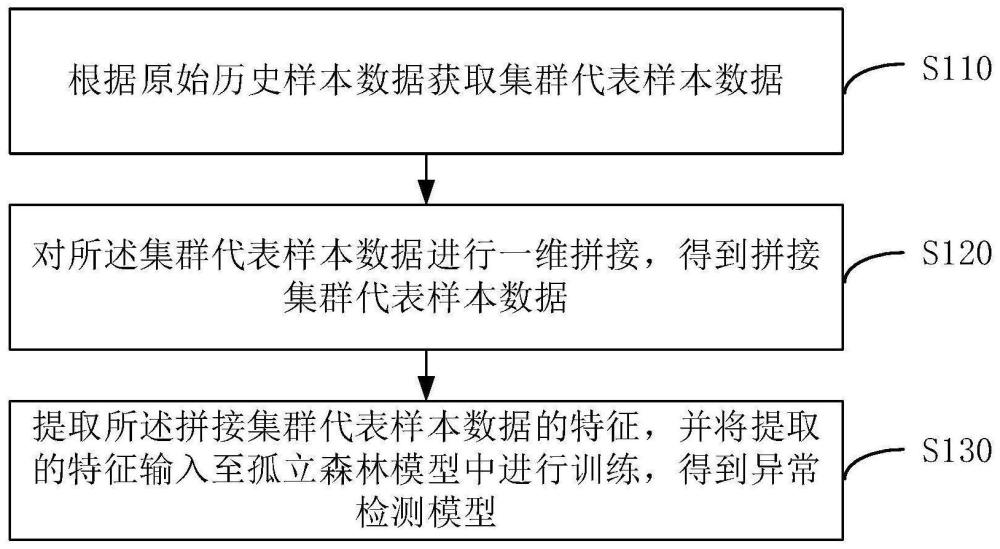
3、根据原始历史样本数据获取集群代表样本数据;
4、对所述集群代表样本数据进行一维拼接,得到拼接集群代表样本数据;
5、提取所述拼接集群代表样本数据的特征,并将提取的特征输入至孤立森林模型中进行训练,得到异常检测模型。
6、根据本发明的另一方面,提供了一种数据检测方法,包括:
7、获取目标待检测数据;
8、根据异常检测模型的模型唯一编码从各所述异常检测模型中确定目标异常检测模型;其中,所述异常检测模型通过第一方面所述的异常检测模型训练方法训练得到;
9、将所述目标待检测数据输入至所述目标异常检测模型中,以通过所述目标异常检测模型对所述目标待检测数据进行异常检测。
10、根据本发明的另一方面,提供了一种异常检测模型训练装置,包括:
11、集群代表样本数据获取模块,用于根据原始历史样本数据获取集群代表样本数据;
12、集群代表样本数据拼接模块,用于对所述集群代表样本数据进行一维拼接,得到拼接集群代表样本数据;
13、异常检测模型训练模块,用于提取所述拼接集群代表样本数据的特征,并将提取的特征输入至孤立森林模型中进行训练,得到异常检测模型。
14、根据本发明的另一方面,提供了一种数据检测装置,包括:
15、目标待检测数据获取模块,用于获取目标待检测数据;
16、目标异常检测模型确定模块,用于根据异常检测模型的模型唯一编码从各所述异常检测模型中确定目标异常检测模型;其中,所述异常检测模型通过第一方面所述的异常检测模型训练方法训练得到;
17、目标待检测数据检测模块,用于将所述目标待检测数据的提取特征输入至所述目标异常检测模型中,以通过所述目标异常检测模型对所述目标待检测数据进行异常检测。
18、根据本发明的另一方面,提供了一种电子设备,所述电子设备包括:
19、至少一个处理器;以及
20、与所述至少一个处理器通信连接的存储器;其中,
21、所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例所述的异常检测模型训练或数据检测方法。
22、根据本发明的另一方面,提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使处理器执行时实现本发明任一实施例所述的异常检测模型训练或数据检测方法。
23、本发明实施例通过根据原始历史样本数据获取集群代表样本数据,并对集群代表样本数据进行一维拼接,得到拼接集群代表样本数据,进而提取拼接集群代表样本数据的特征,并将提取的特征输入至孤立森林模型中进行训练,得到异常检测模型。得到多个异常检测模型之后,获取目标待检测数据,并根据异常检测模型的模型唯一编码从各异常检测模型中确定目标异常检测模型,以将目标待检测数据的提取特征输入至目标异常检测模型中,从而通过目标异常检测模型对目标待检测数据进行异常检测,解决现有异常检测模型训练所消耗的资源较多且训练效率较低等问题,能够降低异常检测模型训练所消耗的资源,提高异常检测模型的训练效率,进而提高数据检测的效率。
24、应当理解,本部分所描述的内容并非旨在标识本发明的实施例的关键或重要特征,也不用于限制本发明的范围。本发明的其它特征将通过以下的说明书而变得容易理解。
- 还没有人留言评论。精彩留言会获得点赞!