一种文档图像背景噪声的去噪方法与流程
本发明涉及文档图像识别,尤其涉及一种文档图像背景噪声的去噪方法。
背景技术:
1、数字化复杂文档图像易产生噪点、斑点、黑边、背景噪声等典型文档噪声问题(如图1所示);其中,背景噪声指的是数字化文档图像中与正文内容无关的杂乱阴影,如底纹、水印、伪影等,它们会影响图像的清晰度和可读性,也会增加后续的文字识别难度。
2、目前,国内外没有非常成熟的文档背景噪声清理类软件产品,大部分业务人员仍使用图像处理类软件(如abbyy finereader、锐尔文档扫描影像优化系统等家厂商的软件产品或平台)来处理资料扫描件中存在的底纹、水印、伪影等问题。这些图像处理软件通常需要手动调参、易用性差,处理效率低,且未针对背景噪声做特定优化。
技术实现思路
1、要解决的技术问题是:为了克服背景噪声清理类图像处理软件通常需要手动调参、易用性差,处理效率低的缺点,提供一种文档图像背景噪声的去噪方法。
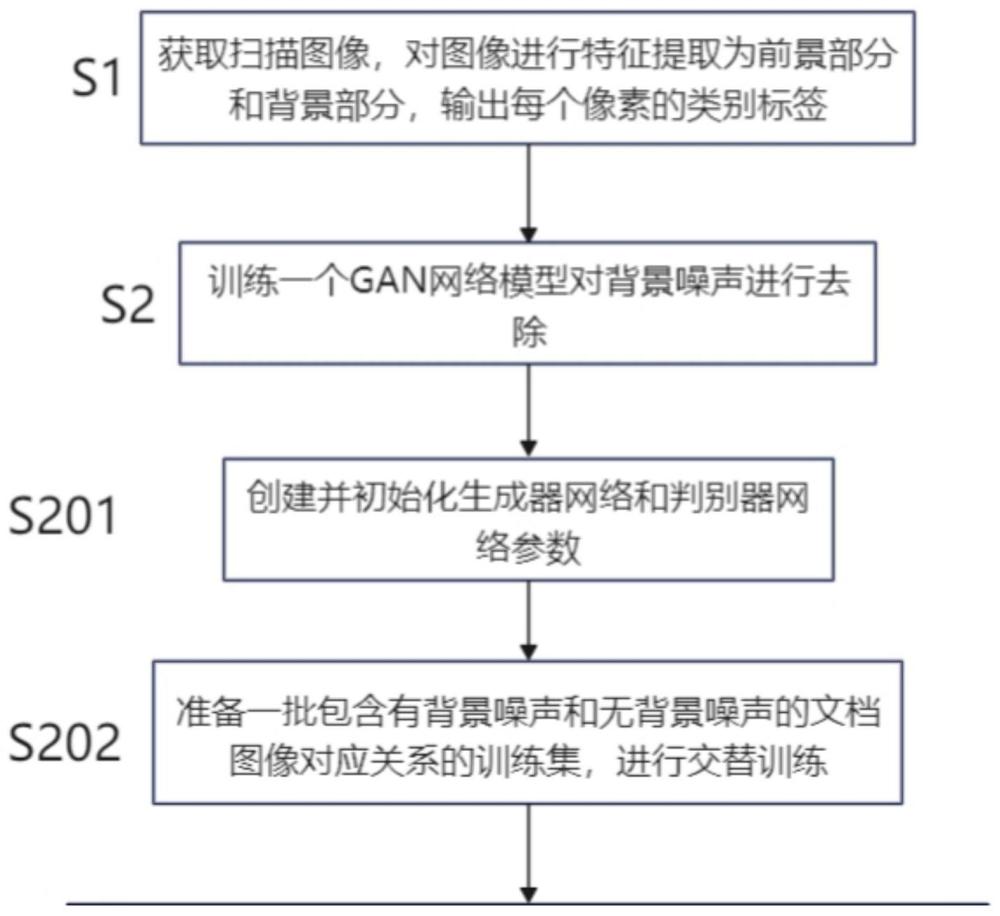
2、本发明的技术方案为:一种文档图像背景噪声的去噪方法,包括有以下步骤
3、s1)获取扫描图像,对图像进行特征提取为前景部分和背景部分,输出每个像素的类别标签,用不同的颜色分别表示前景部分和背景部分;
4、s2)训练一个gan网络模型对背景噪声进行去除;具体步骤包括:
5、s201)创建并初始化生成器网络和判别器网络参数,其中,生成器网络的损失函数可以定义为生成图像与无背景噪声图像之间的均方误差(mse),判别器网络的损失函数可以定义为二元交叉熵(bce);优化器可以选择随机梯度下降(sgd)或adam;
6、s202)准备一批包含有背景噪声和无背景噪声的文档图像对应关系的训练集,进行交替训练;即每次训练一个批次的数据时,先训练一次判别器网络,再训练一次生成器网络;具体流程如下:
7、从训练集中随机抽取一个批次的有背景噪声图像和无背景噪声图像,记为x和y,并从噪声分布中随机抽取一个批次的噪声,记为z;
8、将有背景噪声图像x和噪声z拼接在一起,作为生成器网络的输入,得到生成图像,记为g(x,z);
9、将无背景噪声图像y和生成图像g(x,z)分别输入判别器网络,得到判别结果,记为d(y)和d(g(x,z));
10、根据判别结果和真实标签(1表示真实,0表示生成),计算判别器网络的损失函数,并根据梯度更新判别器网络的参数;
11、再次将有背景噪声图像x和噪声z拼接在一起,作为生成器网络的输入,得到生成图像,记为g(x,z);
12、将生成图像g(x,z)输入判别器网络,得到判别结果,记为d(g(x,z));
13、根据判别结果和真实标签(1表示真实,0表示生成),计算生成器网络的损失函数,并根据梯度更新生成器网络的参数;
14、s203)模型评估:使用一些常用的图像质量评价指标,如峰值信噪比(psnr)或结构相似性(ssim),来比较生成图像与无背景噪声图像之间的差异;从而检测生成图像中的信息是否完整且准确。
15、作为本发明的一种优选技术方案,还包括有步骤s3)所述前景部分提取后,采用深度学习网络mobilenet来实现前景部分中正文区域和边缘区域的识别以确定前景部分的像素值,为后续加权融合步骤作预处理;具体过程如下:
16、对前景部分的正文区域和边缘区域进行识别;采用基于深度学习的ssd(singleshot multibox detector)目标检测算法来识别正文区域,对于边缘区域的确定,将识别到的正文区域之外的区域确定为边缘区域;并生成对应区域的像素级别的掩码;
17、对前景部分进行二值化处理,再对二值化处理后的图像进行形态学膨胀处理,得到若干个连通区块及其包围框坐标;获得了针对每个区域的二值化掩码。
18、作为本发明的一种优选技术方案,还包括有步骤s4)将生成图像和前景部分进行像素级的加权融合;具体步骤如下:
19、遍历生成图像和前景部分的每个像素;
20、对于每个像素位置,计算一个融合权重;根据前景部分中的像素值来确定权重;例如:将前景部分的像素值归一化为[0,1]范围内的值,然后使用以下公式计算融合权重:融合权重=1-前景像素值;
21、使用计算得到的融合权重,将生成图像的像素值和前景部分的像素值进行线性融合;融合后的像素值使用以下公式计算:融合后的像素值=(1-融合权重)*生成图像的像素值+融合权重*前景部分的像素值;
22、重复上述过程,遍历整个图像,将生成图像的每个像素与前景部分相应位置的像素进行加权融合;最终生成完整的去噪图像。
23、有益效果:1、本发明采用卷积神经网络(cnn)对扫描图像进行特征提取,将图像分为前景和背景部分,使用不同颜色标记每个像素的类别,从而区分文本内容和背景噪声。
24、2、背景部分采用生成对抗网络模型来去除背景噪声;前景部分中正文区域和边缘区域的识别,采用了基于深度学习的目标检测算法和二值化处理,能够有效地提取文本内容和边缘细节,增强融合图像的可读性和对比度。
25、3、利用像素级加权融合方法,能够有效地保留前景部分的文本内容和背景部分的清晰度,避免信息丢失和伪影产生;为文档智能化归档提供有效支持。
技术特征:
1.一种文档图像背景噪声的去噪方法,其特征在于:包括有以下步骤:
2.如权利要求1所述的一种文档图像背景噪声的去噪方法,其特征在于:还包括有步骤s203)模型评估:使用一些常用的图像质量评价指标,如峰值信噪比或结构相似性,来比较生成图像与无背景噪声图像之间的差异;从而检测生成图像中的信息是否完整且准确。
3.如权利要求1所述的一种文档图像背景噪声的去噪方法,其特征在于:还包括有步骤s3):所述前景部分提取后,采用深度学习网络mobilenet来实现前景部分中正文区域和边缘区域的识别以确定前景部分的像素值,为后续加权融合步骤作预处理;具体过程如下:
4.如权利要求3所述的一种文档图像背景噪声的去噪方法,其特征在于:还包括有步骤s4):将生成图像和前景部分进行像素级的加权融合;具体步骤如下:
技术总结
本发明涉及文档图像识别技术领域,尤其涉及一种文档图像背景噪声的去噪方法。一种文档图像背景噪声的去噪方法,包括有以下步骤:S1)获取扫描图像,对图像进行特征提取为前景部分和背景部分,输出每个像素的类别标签,用不同的颜色分别表示前景部分和背景部分;S2)训练一个GAN网络模型对背景噪声进行去除。本发明采用卷积神经网络(CNN)对扫描图像进行特征提取,将图像分为前景和背景部分,使用不同颜色标记每个像素的类别,从而区分文本内容和背景噪声。
技术研发人员:廖成慧,郝海风,曾江佑,王亚瑛,刘岳,彭中辉,周凯,李冰清
受保护的技术使用者:江西博微新技术有限公司
技术研发日:
技术公布日:2024/2/25
- 还没有人留言评论。精彩留言会获得点赞!