一种适合边缘设备部署的行人重识别方法与流程
本发明涉及边缘计算领域,特别涉及一种适合边缘设备部署的行人重识别方法。
背景技术:
1、行人重识别技术是计算机视觉领域的研究热点,通过行人重识别技术可以实现在不同监控摄像头下同一行人的跨境查找,可用于走失人员搜索、行人轨迹生成和活动区域定位,在商场、园区管理有广泛应用前景。
2、目前基于深度学习的行人重识别方法,主要利用人脸信息、行人属性信息、行人全局或局部抽象特征等多信息的融合来进行行人比对,相似度高的即为同一人。对于一个行人重识别系统,处理的监控视频路数较多,产生的数据非常庞大,如果直接将如此庞大的数据全部传送给中心服务器会占用大量的带宽和消耗大量计算负载。随着万物互联时代的到来,边缘计算设备被广泛应用,用于替代部分或全部中心服务器任务,来缓解服务器的带宽压力和计算能耗。
3、上述做法存在的技术问题是,实现传统的行人重识别的多信息融合,需要多个算法模型和更复杂的业务逻辑的配合,目前主流边缘设备算力有限,即使实现了但延迟较高,或者提出的方案难以在边缘设备上达到精度和效率的平衡。
4、例如,申请号为201910099228.3、发明名称为“一种基于边缘计算的自适应城市寻人方法”的技术方案,通过过滤冗余的视频帧降低计算量;对上传的视频帧行人进行行人检测,将检测到的一定比例的行人进行行人重识别,输出行人的特征;边缘服务器定时将识别到的和寻找目标相似度最高的k个行人上传至云服务器;利用云服务器上的行人重识别模块对剩余比例的行人进行重识别,云服务器和边缘服务器的识别结果结合,并定时将识别到的与寻找目标相似度最高的k个行人返回终端处理。该技术方案存在的问题为:(1)模型提取行人特征信息单一,实际应用时会存在较多干扰;(2)过滤冗余视频帧主要利用图像直方图的相似度,为全局特征,容易忽略局部特征的差异,导致有效信息的丢失;(3)把提取特征的任务按比例分配给服务器和边端设备,如果服务器和边端设备算力或者带宽差距较大,仍然会出现同步问题。
5、再例如,申请号为202211708842.3、发明名称为“分布式边缘协同推理的行人重识别方法、系统及装置”的技术方案,通过分布式边缘协同推理架构获取待处理的图像;通过resnet-50提取图像的身份特征和属性特征,得到所述图像中行人身份的第一分类结果;根据所述属性特征,得到所述图像中各个行人的属性分类结果;根据所述属性分类结果进行属性特征融合,得到融合属性特征,并根据所述融合属性特征得到所述图像中行人身份的第二分类结果;根据所述第一分类结果和所述第二分类结果,进行行人重识别。该技术方案存在的问题为:(1)采用resnet50提取图像的身份特征和属性特征,模型较大,边缘端部署推理耗时较长;(2)没有提出过滤机制,全视频序列处理计算量过大。
6、又例如,申请号为cn202211138091.6、发明名称为“一种基于边缘计算的行人重识别与跟踪方法”的技术方案,首先对行人进行多角度特征提取,进行单相机特征检测并构建行人多角度初始特征集;然后获取行人特征,实行目标行人跟踪;最后进行行人特征检索,并对行人进行重识别,获取目标行人数据;通过在场景出入口处采集多角度行人特征,并且融合行人重识别与行人跟踪算法,加速计算,在边缘侧部署,可提供实时性较好的重识别和跟踪结果。该技术方案存在的问题为:(1)方案具有局限性,作者对初始特征集和采集地点都做了限制,不适用于更广泛场景;(2)利用fairmot来同时进行行人跟踪和行人特征提取,fairmot本身是一个多目标检测和跟踪算法,其获取局部特征能力较弱,直接用它提取的行人特征做行人重识别可能存在误识别。
技术实现思路
1、本发明的目的在于克服现有技术的缺点与不足,提供一种适合边缘设备部署的行人重识别方法,该方法在保证精度情况下,从模型改进和业务逻辑处着手降低了计算量。
2、本发明的目的通过以下的技术方案实现:
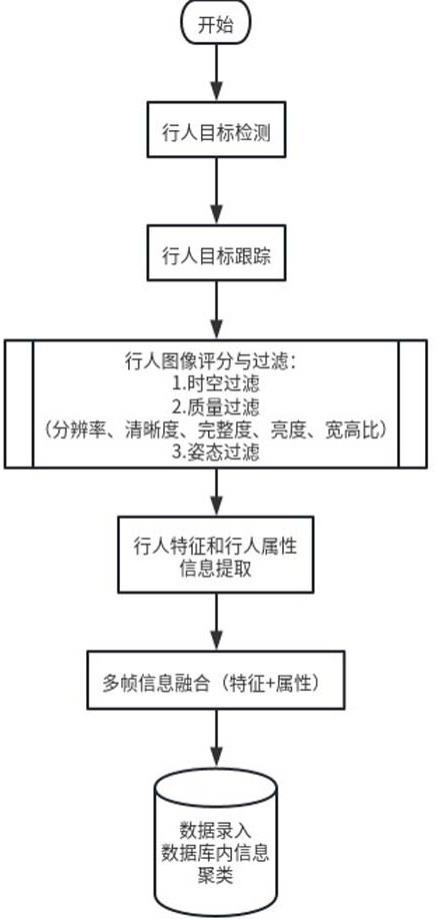
3、一种适合边缘设备部署的行人重识别方法,包括以下步骤:
4、s1、通过目标检测模型获得每一帧图像上的行人包络框,利用sort多目标跟踪模型为每个行人包络框赋予一个id, 并对所有行人包络框进行跟踪;对于同一id的行人包络框进行过滤;
5、s2、通过fastreid模型对行人图像同时提取行人特征和行人属性,对同一id进行多帧行人特征和行人属性融合,融合后的行人特征导入数据库,在数据库内采用均值漂移聚类,对不同id间的行人特征做进一步的融合,去除冗余id,最后得到不同id的行人特征和属性信息;
6、s3、先对不同id的行人特征进行余弦距离计算,获取k个相似行人,然后利用k个相似行人的行人属性信息进行二次过滤,过滤k个相似行人中属性不匹配结果,得到最相似行人重识别结果。
7、步骤s1中,所述目标检测模型为轻量化后的yolox_s模型。
8、所述yolox_s模型的轻量化处理包括:
9、(1)对yolox_s模型进行batchnorm权重稀疏训练,然后裁剪yolox_s模型的bn层权重小于预设值的通道;
10、(2)对裁剪后的yolox_s模型进行finetune微调训练;
11、(3) yolox_s模型移植边缘端设备时进行int8量化。
12、所述yolox_s模型的bn层为yolox_s模型的特征归一化算子,特征归一化算子为batchnorm 2d算子,公式如下所示:
13、;
14、其中,为需要归一化的输入数据,和为批量数据的均值和方差,为防止分母出现零所增加的变量,和是对输入值进行仿射操作,即线性变换;从公式可知,bn层的权重为和,输出中的每个通道都有对应的和,使用来判断不同通道的重要程度;当小于预设值,认为该通道的数据对模型后续影响较小,则对该通道的权重进行裁剪;batchnorm权重稀疏训练过程目的就是为了获得部分较小的值,整体通道裁剪比例为40%就是将40%较小的那部分值对应的通道进行裁剪。
15、步骤s1中,所述目标检测模型的工作过程如下:
16、首先从摄像头终端采集得到图像数据,针对图像数据进行前处理,经过前处理后的图像数据会输入给目标检测模型yolox_s进行推理:图像数据在目标检测模型yolox_s的主干网络经过卷积运算得到输出特征图;接着特征图输入到目标检测模型yolox_s的输出头进行目标框的回归和分类;
17、目标检测模型yolox_s的输出头总共有三个分支:cls_output,用于预测目标框的类别和分数,输出大小为w*h*c,其中w为输出特征图宽度,h为输出特征图高度,c为检测类别个数;obj_output,用于判断目标框是前景还是背景,输出大小为w*h*1;reg_output,用于对目标框的坐标信息(x,y,w,h)进行预测,输出大小为w*h*4;
18、目标检测模型yolox_s的输出头的三个分支,经过合并得到最后的候选预测框信息,大小为pred_num*dim,其中pred_num=w*h,表征预测框个数,dim=c+1+4,表征每个预测框特征向量维度;这时每个预测框含有一个维度为dim的特征向量:[cls_1 cls_2 ...cls_c obj x y w h],其中,x为目标框中心点x坐标信息,y为目标框中心点y坐标信息,w为目标框宽度信息,h为目标框高度信息,obj为目标框得分信息,cls_1为目标框类别1得分,cls_c为目标框类别c得分;
19、对候选预测框结果进行后处理:首先将预测框的归一化坐标还原到实际像素大小,然后利用非极大值抑制对冗余预测框进行过滤,输出得到最后的行人包络框。
20、所述前处理包括图像尺寸的标准化缩放和数据的归一化处理。
21、步骤s1中,所述sort多目标跟踪模型的工作过程如下:
22、(1) 为目标检测模型获得的每个行人包络框赋予一个id;
23、(2)初始化目标追踪器:对于每个检测到的行人目标,为其创建一个卡尔曼滤波目标追踪器,用于跟踪行人目标在后续图像帧中的运动;
24、(3)多帧跟踪:对于每一帧,执行以下操作:
25、1)数据关联:对于卡尔曼滤波预测的行人包络框bboxprediction和目标检测模型得到的行人包络框bboxmeasurement,用匈牙利算法进行匹配;
26、2)状态更新:用卡尔曼滤波预测的行人包络框bboxprediction和目标检测模型得到的行人包络框bboxmeasurement更新当前状态,得到行人跟踪包络框bboxoptimal,作为追踪的结果。
27、步骤s1中,所述过滤包括按顺序进行的时空过滤、质量过滤、姿态评估;其中,时空过滤是指对于已存在id的某一行人跟踪结果,只保留与上一帧图像的帧间隔大于时间阈值且空间间隔大于空间阈值的行人跟踪结果,然后保留的行人跟踪结果进入到质量过滤;质量过滤是指将不满足质量指标的行人跟踪结果过滤掉,同时对行人跟踪结果的每个质量指标进行评分,全部质量指标评分的加权求和就是行人跟踪结果的质量分数s1,然后保留的行人跟踪结果进入到姿态评估;姿态评估是将行人姿态分为若干个属性,并通过属性分类模型输出若干个行人姿态的概率值,若干个行人姿态的概率值与质量分数s1加权求和,得到最终的行人质量评分sfinal;
28、录入通过时空过滤、质量过滤、姿态评估的行人跟踪结果result:若行人跟踪结果result内对应id的已经保存有n个行人跟踪结果,如果n小于该id对应的帧号,则直接录入;如果n大于或等于该id对应的帧号,则比较行人质量评分sfinal,如果行人跟踪结果result的行人质量评分sfinal大于n个行人跟踪结果评分的最小值,则进行替换。
29、步骤s2中,所述通过fastreid模型对行人图像同时提取行人特征和行人属性,具体如下:首先通过保留下来的行人包络框对图像中的行人进行截取,然后先进行前处理获得标准数据;然后将标准数据导入fastreid模型,经过卷积运算后,得到行人特征,行人特征经过一个线性分类器后,输出行人属性分类结果。
30、步骤s2中,所述多帧行人特征融合是通过加权求和方式得到;所述多帧行人属性采用高低双阈值方式进行属性判断,对每个属性进行结果统计,累计值最高的状态即为行人属性融合结果;通过融合,一个id就只对应一个行人特征结果和行人属性结果。
31、同时,本发明提供:
32、一种服务器,所述服务器包括处理器和存储器,所述存储器中存储有至少一段程序,所述程序由所述处理器加载并执行以实现上述适合边缘设备部署的行人重识别方法。
33、一种计算机可读存储介质,所述存储介质中存储有至少一段程序,所述程序由处理器加载并执行以实现上述适合边缘设备部署的行人重识别方法。
34、本发明与现有技术相比,具有如下优点和有益效果:
35、1、对于行人图片质量评估与过滤,本发明采用多重过滤(时空、质量、姿态)和多个质量评估指标(分辨率、清晰度、完整度、亮度、宽高比)对行人图片进行评估和过滤,一方面去除了影响精度的失真图片,一方面也过滤了影响计算效率的冗余图片,包括空间冗余、时间冗余和姿态冗余,提出了利用姿态作为评分基准,避免了侧面姿态信息丢失带来的识别影响。与现有技术相比,并不是直接全局判断整帧图像的冗余度,避免了局部信息的丢失。
36、2、为了适应边缘端部署,本发明采用多任务模型既提取行人特征,又提取行人属性,一模多用,在保证较丰富的信息提取能力的同时,有效减少计算量。此外对模型进行了轻量化处理,进一步提高模型推理速度。与现有技术相比,目前现有技术的模型设计不合理,或者无轻量化改进,不适合边缘端部署,或者特征提取结果单一或者提取能力不强。
37、3、本发明对于同一id内的信息进行了融合,包括特征和属性的融合,一方面获取到了时空信息特征,一方面也减少了计算数据量;对于不同id,也同样进行了聚类融合,减少了id间因为行人跟踪出错导致的冗余情况。目前技术主要对特征进行融合,并未见到对属性进行融合的情况。
38、4、本发明的查询过程进行了二次判断,其行人查询过程包含两个流程:特征比对和属性比对,从全局特征和局部特征的角度分别对相似行人进行查找和过滤,提高了查询结果的准确性。
- 还没有人留言评论。精彩留言会获得点赞!