一种结合知识蒸馏和动态词剪枝的语言模型轻量化方法
本发明属于自然语言处理领域,具体涉及语言模型的轻量化和计算加速方法。
背景技术:
1、预训练语言模型在广泛的自然语言处理任务中取得了卓越的性能,但它们通常面临参数量大、计算开销大等问题。为了推动预训练语言模型的实际应用,需要研究模型轻量化方法,即如何在最小化性能下降的前提下提高其计算速度。
2、为实现这一目标,现有的方法有模型压缩和动态计算这两个主要的研究方向。模型压缩方法通过减少语言模型的层数和表示维度以得到一个固定的小模型,从而提升其计算速度,代表方法有知识蒸馏、剪枝、量化等;而动态计算方法则不需要改变给定的语言模型的结构,其在模型计算过程中对不同样本或样本中的不同部分动态地修建其前向传播的计算图,代表方法有动态深度剪枝(层剪枝)和动态宽度剪枝(词剪枝)等。
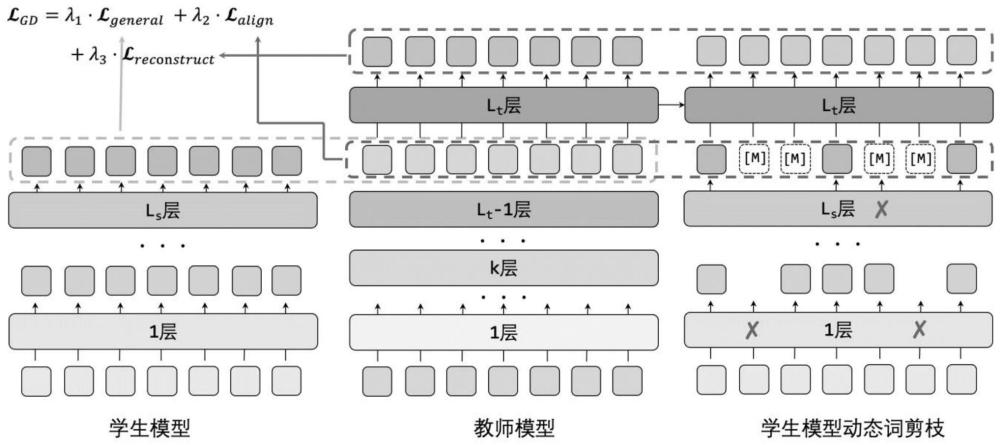
3、在过去的研究中,研究者们通常单独研究模型压缩与动态计算,或直接对一个压缩后的小模型开展动态计算。尽管这种简单组合的方法取得了一定的效果,但由于模型压缩和动态计算过程是分别设计的,小模型并没有从训练过程中获得对动态词剪枝的鲁棒性,因此现有的方法中,动态词剪枝的性能和效果尚未完全发挥。
技术实现思路
1、针对现有技术中存在的技术问题,本发明的目的在于提供一种更有效的语言模型轻量化方法,该方法结合了知识蒸馏和动态词剪枝,针对一个小语言模型,在知识蒸馏的训练的过程中通过目标函数的设计在传递知识的同时提升了其面向动态词剪枝的鲁棒性,从而可以在计算时在相同的词剪枝比例下取得更好的性能,从而使得语言模型在性能一致时实现更高的加速比。
2、本发明实现上述目的所采用的技术方案为:
3、一种结合知识蒸馏和动态词剪枝的语言模型轻量化方法,其步骤包括:
4、1)基于transformer模型构建学生模型和教师模型,向学生模型和教师模型输入文本序列;
5、2)通用知识蒸馏阶段,学生模型和教师模型的各层根据输入的文本序列分别输出词表示和注意力矩阵,以基于对比学习的词表示对齐和基于均方误差的注意力矩阵对齐为目标来约束学生模型非剪枝情况下输出和教师模型对应输出一致;
6、对学生模型逐层进行动态词剪枝,学生模型输出经过动态词剪枝后保留的词表示和注意力矩阵,教师模型输出对应的词表示和注意力矩阵,以基于对比学习的词表示对齐和基于均方误差的注意力矩阵对齐为目标来约束学生模型动态词剪枝后剩余输出和教师模型对应输出一致;
7、对学生模型逐层进行动态词剪枝,通过教师模型重建学生模型的已被剪去的词表示并计算相应的注意力矩阵,教师模型输出与之对应的词表示和注意力矩阵,以基于对比学习的词表示对齐和基于均方误差的注意力矩阵对齐为目标来约束学生模型经过重建的被剪枝的输出和教师模型对应输出一致;
8、3)特定任务知识蒸馏阶段,向学生模型和教师模型输入该特定任务的文本序列,学生模型输出经过动态词剪枝后的分类结果的表示,教师模型输出分类结果的表示,以分类结果的表示对齐为目标进行对比学习来约束学生模型动态词剪枝后输出层分类结果的表示和教师模型输出层的分类结果的表示一致;
9、4)利用依次经过上述两阶段的对比学习训练的学生模型来正式处理输入的文本序列。
10、进一步地,在通用知识蒸馏阶段和特定任务知识蒸馏阶段,对于输入的文本序列,首先使用分词器进行分词处理。
11、进一步地,步骤2)中以基于对比学习的词表示对齐和基于均方误差的注意力矩阵对齐为目标来约束学生模型非剪枝情况下输出和教师模型对应输出一致,包括以下步骤:
12、对于词表示对齐,将学生模型的最上层的每个词表示进行线性映射,得到与教师模型具有相同隐藏维度的中间表示;将教师模型自上而下第二层的与中间表示对应的每个词表示作为正样本,将教师模型自上而下第二层的与中间表示不对应的所有词表示作为负样本,并根据词表示对齐的目标函数进行对比学习来约束学生模型的表示与正样本的相似度尽可能大,同时与负样本的相似度尽可能小;
13、对于注意力矩阵对齐,用基于均方误差函数的注意力矩阵对齐的目标函数来约束学生模型最上层的注意力矩阵和教师模型自上而下第二层的注意力矩阵一致;
14、根据词表示对齐的目标函数与注意力矩阵对齐的目标函数之和,得到教师模型向学生模型通用知识蒸馏的第一项目标函数。
15、进一步地,词表示对齐的目标函数为:
16、
17、其中,τ为温度系数、s(·)为余弦相似度,log的底数为e,为学生模型的最上层的每个词表示进行线性映射的中间表示,为教师模型自上而下第二层的与中间表示对应的每个词表示,m1为存储负样本的记忆矩阵,其中每个负样本用表示;
18、注意力矩阵对齐的目标函数为:
19、
20、其中,mse(·)表示均方误差函数,为学生模型最上层的注意力矩阵,为教师模型自上而下第二层的注意力矩阵。
21、进一步地,步骤2)中以基于对比学习的词表示对齐和基于均方误差的注意力矩阵对齐为目标来约束学生模型动态词剪枝后剩余输出和教师模型对应输出一致,包括以下步骤:
22、对于词表示对齐,将学生模型的最上层剩余的每个词表示进行线性映射,得到与教师模型具有相同隐藏维度的中间表示;将教师模型自上而下第二层的与学生模型剩余词中间表示对应的每个词表示作为正样本,将教师模型自上而下第二层的与学生模型剩余词中间表示不对应的所有词表示作为负样本,并根据词表示对齐的目标函数进行对比学习来约束学生模型的表示与正样本的相似度尽可能大,同时与负样本的相似度尽可能小;
23、对于注意力矩阵对齐,用基于均方误差函数的注意力矩阵对齐的目标函数来约束学生模型最上层剩余词表示的注意力矩阵和教师模型自上而下第二层对应词表示的注意力矩阵一致;
24、根据词表示对齐的目标函数与注意力矩阵对齐的目标函数之和,得到教师模型向学生模型通用知识蒸馏的第二项目标函数。
25、进一步地,词表示对齐的目标函数为:
26、
27、其中,τ为温度系数、s(·)为余弦相似度,log的底数为e,为学生模型的最上层剩余的每个词表示进行线性映射的中间表示,为教师模型自上而下第二层的与学生模型剩余词中间表示对应的每个词表示,m1为存储负样本的记忆矩阵,其中每个负样本用表示;
28、注意力矩阵对齐的目标函数为:
29、
30、其中,mse(·)表示均方误差函数,为学生模型最上层剩余词表示的注意力矩阵,为教师模型自上而下第二层对应词表示的注意力矩阵。
31、进一步地,步骤2)中以基于对比学习的词表示对齐和基于均方误差的注意力矩阵对齐为目标来约束学生模型经过重建的被剪枝的输出和教师模型对应输出一致,包括以下步骤:
32、对于词表示对齐,将学生模型的最上层剩余的每个词表示进行线性映射,得到与教师模型具有相同隐藏维度的中间表示,并基于这些中间表示重建学生模型被剪去的词表示和对应的注意力矩阵;将教师模型最上层的与学生模型重建的词表示对应的词表示作为正样本,将教师模型最上层的与学生模型重建的词表示不对应的所有词表示作为负样本,并根据词表示对齐的目标函数进行对比学习来约束学生模型的表示与正样本的相似度尽可能大,同时与负样本的相似度尽可能小;
33、对于注意力矩阵对齐,用基于均方误差函数的注意力矩阵对齐的目标函数来约束学生模型最上层重建词表示的注意力矩阵和教师模型最上层的注意力矩阵一致;
34、根据词表示对齐的目标函数与注意力矩阵对齐的目标函数之和,得到教师模型向学生模型通用知识蒸馏的第三项目标函数。
35、进一步地,词表示对齐的目标函数为:
36、
37、其中,τ为温度系数、s(·)为余弦相似度,log的底数为e,为学生模型的最上层剩余的每个词表示进行线性映射的中间表示,为教师模型最上层的与学生模型重建的词表示不对应的所有词表示,m1为存储负样本的记忆矩阵,其中每个负样本用表示;
38、注意力矩阵对齐的目标函数为:
39、
40、其中,mse(·)表示均方误差函数,为学生模型最上层重建词表示的注意力矩阵,为教师模型最上层的注意力矩阵。
41、进一步地,步骤3)中以分类结果的表示对齐为目标进行对比学习来约束学生模型动态词剪枝后输出层分类结果的表示和教师模型输出层的分类结果的表示一致,包括以下步骤:
42、按照教师模型最上层输出的分类结果的表示的维度,将学生模型经过动态词剪枝后的最上层输出的分类结果的表示进行线性映射,得到与教师模型具有相同隐藏维度的中间表示;
43、将教师模型最上层的分类结果的表示作为正样本,将教师模型最上层的其他样本的分类结果的表示作为负样本,并根据分类结果的表示对齐的目标函数进行对比学习来约束学生模型的表示与正样本的相似度尽可能大,同时与负样本的相似度尽可能小。
44、进一步地,分类结果的表示对齐的目标函数为:
45、
46、其中,τ为温度系数、s(·)为余弦相似度,log的底数为e,为学生模型经过动态词剪枝后的最上层输出的分类结果的表示进行线性映射的中间表示,为教师模型最上层的分类结果的表示,m2为存储负样本的记忆矩阵,其中每个负样本用表示。
47、本发明取得的有益效果如下:
48、本发明提出了动态序列长度知识蒸馏的训练方法,在传统的知识蒸馏算法对齐教师模型和学生模型对应中间表示的基础上,额外为学生模型引入了一个在前向传播计算中随着层数的加深动态缩减序列长度的模式,并引入定制的目标函数从而在知识蒸馏的过程中提升学生模型对动态词剪枝的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!