一种数据文件均衡分区的方法与流程
本发明涉及物理,具体涉及一种数据文件均衡分区的方法。
背景技术:
1、在对大批量文件进行并行操作(包括传输、读取、解密和写入等)时,涉及磁盘i/o、网络、cpu和内存,不同文件大小和数量对资源的需求和性能产生影响也不同。如何将文件均衡分发到不同线程、分区、服务器上。此方法需同时兼顾文件大小和文件数量对资源消耗及性能的影响系数。
2、在数据集成、数据开发中,往往需要对大批量文件进行并行传输、读取、解密、解析、写入等操作。目前常用的方法有以下几种:
3、贪心算法,将文件按大小从大到小排序,每次按放入当前总大小最小的分区中。这个方法更加强调每个分区的总大小均衡,并且通过从最大的文件开始分配,减少了由于分区大小限制造成的问题。但是,这种方法并不能保证每个分区的文件数量均衡,因为它主要是基于文件大小进行分配的。
4、双层循环平衡算法,通过两个阶段的文件分配和一个平衡阶段,将大于平均大小的文件优先分配到分区并在需要时进行文件移动,以实现分区的平衡和文件管理。可总结为四步:1.初始化分区:为每个分区创建一个集合,用于存储文件,并记录分区总大小;2.分配大文件:遍历所有文件,将超过平均大小的文件优先分配到各分区,确保不超过大小限制。3.分配小文件:再次遍历所有文件,为小于平均大小的文件选择适合的分区;4.平衡分区:比较分区大小,在需要时在分区间移动文件,以实现分区的平衡。该算法的平衡逻辑需要根据实际需求进行调整。在不超过大小限制的情况下移动文件。
5、模拟退火算法是一种启发式搜索算法,用于解决最优化问题。通过模拟固体退火的过程,系统会逐渐稳定在一种状态。在这种情况下,我们可以使用模拟退火来寻找一种将文件分布在分区中的方法,使每个分区的大小和数量达到理想的均衡状态。模拟退火算法的核心思想在于允许在搜索过程中接受一些稍差的解,以避免陷入局部最优解。通过随机性和概率控制,算法能够在解空间中进行全局搜索,从而在文件分配问题中找到更好的解决方案,考虑到不同文件大小、数量以及资源消耗和性能的影响系数,以实现更优的资源利用和性能优化。
6、基尼系数(gini coefficient),是一种用来衡量不平等程度的统计指标,经常用于描述收入、财富、资源或其他分布不均匀的情况。它的值介于0到1之间,0表示完全平等,即所有个体拥有相同的份额,而1表示完全不平等,即一部分个体占有所有资源,而其他个体没有任何份额。
技术实现思路
1、本发明是为了解决如何能将大小不一的文件分发到不同的线程、分区、服务器上,同时避免因数据倾斜引起的资源和性能问题,提供一种数据文件均衡分区的方法,对退火算法进行改造,将在将大批量文件分发到不同线程、分区、服务器时,兼顾文件大小和文件数量对资源消耗及性能的影响系数,避免因数据倾斜引起的资源和性能问题,也就是不出现资源长板和性能短板。本方法有助于优化大规模文件处理过程中的资源利用和性能,提高数据处理效率,同时具有一定的灵活性和适用性,使其成为在数据集成和数据开发领域中有益的解决方案。这种方法的独特之处在于考虑了文件大小和数量对资源和性能的综合影响,从而实现了更好的均衡分发。
2、本发明提供一种数据文件均衡分区的方法,使用退火算法依据文件数量、文件大小将待发放文件分到n个分区中;
3、包括以下步骤:
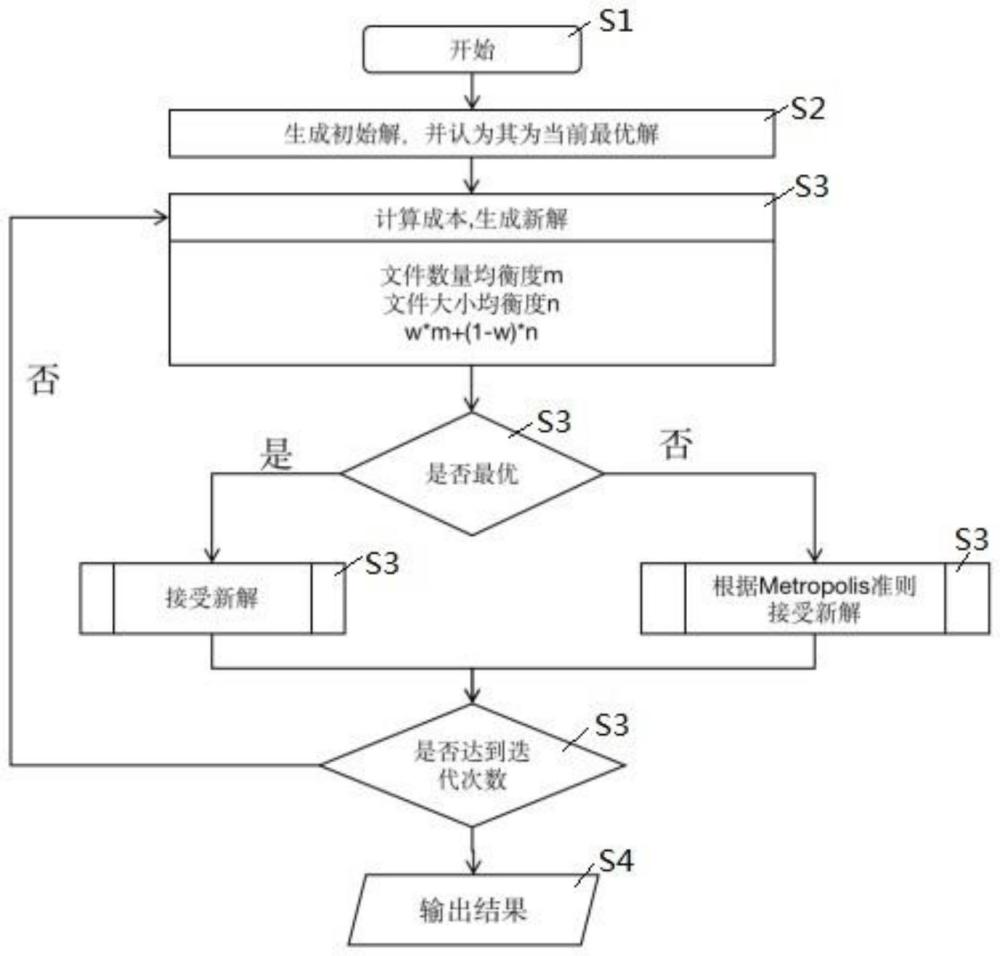
4、s1、将每个待发放文件作为一个状态,每个分区作为一个可能的解,设定成本函数,成本函数包括文件数量均衡度、文件大小均衡度和影响系数,将待发放文件的文件名称和大小送入数据文件均衡分区的方法中;
5、s2、使用退火算法随机生成一个文件分区的初始解,初始解中包括将每一个待发放文件分配到分区中的方案;
6、s3、根据成本函数计算成本,生成新解,随机选择新解中的一个文件并重新分配到另一个分区,计算新状态的内能值ej,判断新解是否为最优,如果是,接受新解;如果否,根据metropolis准则接收新解;
7、s4、判断是否达到迭代次数或者目标收敛程度,如果否,返回步骤s3,如果是,输出分区结果,依据分区结果将待发放文件进行分区,一种数据文件均衡分区完成。
8、本发明所述的一种数据文件均衡分区的方法,作为优选方式,步骤s1中,文件数量均衡度为:
9、
10、其中,xi为第i个分区的文件数量,n为分区数量,总文件数量为所有分区文件数量之和。
11、本发明所述的一种数据文件均衡分区的方法,作为优选方式,可用基尼系数来评估文件数量均衡度。
12、本发明所述的一种数据文件均衡分区的方法,作为优选方式,步骤s1中,文件大小均衡度为:
13、
14、其中,yi为第i个分区的文件大小,总文件大小为所有分区文件大小之和。
15、本发明所述的一种数据文件均衡分区的方法,作为优选方式,可用基尼系数来评估文件大小均衡度。
16、本发明所述的一种数据文件均衡分区的方法,作为优选方式,步骤s1中,影响系数为文件数量均衡度和文件大小均衡度对成本函数的影响系数,影响系数为w,w∈[0,1];
17、成本函数的返回为:
18、文件数量均衡度*w+文件数量均衡度*(1-w)。
19、本发明所述的一种数据文件均衡分区的方法,作为优选方式,步骤s3中,若新状态的内能ep小于上一个状态k的内能,即ep<ek,则判断新状态为最优,接收p为新的状态,其对应的内能作为目前的最优解;
20、否则,以概率:
21、
22、接收p状态,其中k为boltzmann常数,t为目前的温度;
23、未达到最优解时,移动一个待发放文件的分区重新计算。
24、本发明所述的一种数据文件均衡分区的方法,作为优选方式,步骤s4中,输出分区结果后,并行进行待分区文件的分区。
25、本发明所述的一种数据文件均衡分区的方法,作为优选方式,并行操作包括读、解析和解密。
26、文件操作包括传输、读取、解密和写入等涉及磁盘i/o、网络、cpu和内存,随着文件大小和数量不同对资源的需求和性能产生影响也不同。传输1000个1m的文件和100个10m的速度不同,解析一个txt和xml的性能不同,不同的加解密算法的文件大小和对cpu的消耗也不同。
27、虽然大文件可以更好地利用网络带宽,然而却可能降低后续处理(解析)的并行度;高压缩率的加密算法可能提高网络传输速度,却可能影响解密的速度。
28、可将问题提炼为:如何将n个大小不一的文件均衡分发到p个分区中?考虑到文件将用于并行读取、解密、写入等涉及磁盘io/网络/cpu/内存的操作。而文件大小和数量对资源消耗和性能的影响不一。需要均衡分发算法同时兼顾文件大小和文件数量对资源消耗、性能的影响系数。
29、本方法在将大批量文件分发到不同线程、分区、服务器时,兼顾文件大小和文件数量对资源消耗及性能的影响系数,避免因数据倾斜引起的资源和性能问题,也就是不出现资源长板和性能短板。
30、本方法并不要求使用者精准测算各文件操作,不同操作组合对资源的需求及性能的影响,仅需要根据实际环境和场景评估文件大小和文件数量的影响系数便可使用。
31、metropolis准则:从当前i状态发展到下一状态j,若新状态的内能小于状态i的内能,即ej<ei,则接收j为新的状态,其对应的内能作为目前的最优解;否则,以概率:
32、
33、接收该新解,其中k为boltzmann常数,t为目前的温度,在后续的判断过程中可加入计算机的蒙特卡罗实验模拟产生概率(随机数)。
34、算法设计为了寻找最小的内能,那可以对应到实际情况中的全局最小解。
35、本发明具有以下优点:
36、(1)本方法有助于优化大规模文件处理过程中的资源利用和性能,提高数据处理效率,同时具有一定的灵活性和适用性,使其成为在数据集成和数据开发领域中有益的解决方案。这种方法的独特之处在于考虑了文件大小和数量对资源和性能的综合影响,从而实现了更好的均衡分发。
37、(2)本发明在资源利用率的优化方面,通过考虑文件大小和数量的影响系数,能够更有效地分发文件到不同的线程、分区和服务器上,以充分利用磁盘i/o、网络、cpu和内存等资源,有助于避免资源短缺问题,提高整体资源利用率。
38、(3)本发明在性能提升方面,通过均衡地分发不同大小和数量的文件,有助于优化并行读取、解密、解析和写入操作的性能。这意味着可以更快速地完成数据处理任务,提高数据处理的效率。
39、(4)本发明在灵活性和适用性方面,不要求用户精确测算不同操作组合对资源需求和性能的影响,提供了一种基于实际环境和场景的评估方法,使用户可以根据自身情况来确定文件大小和数量的影响系数。这增加了方法的灵活性和适用性。
40、(5)本发明在避免数据倾斜方面,通过均衡分发文件,有助于避免因数据倾斜而引起的资源和性能问题。这意味着不会出现某些资源成为瓶颈(资源长板)或某些任务耗时过长(性能短板)的情况。
- 还没有人留言评论。精彩留言会获得点赞!