一种数据驱动的可解释性水稻物候预测方法
本发明属于物候预测,具体涉及一种数据驱动的可解释性水稻物候预测方法。
背景技术:
1、水稻是我国重要粮食作物,其产量约占粮食总产量的43.6%,为全国50%以上的人口提供了稳定的粮食供应。水稻的高产与稳产直接关乎国家粮食安全。准确预测水稻物候日期对于合理制定田间管理措施、促进作物增产具有重要意义。
2、近年来,卫星、无人机和地面传感器等观测设备和技术的快速发展为认知农田系统提供了多源数据,这些数据蕴含着丰富的作物长势信息。机器学习技术具有强大的学习能力,可以学习输入数据和输出变量之间的复杂非线性关系。近年来,该技术被用于预测作物物候,如文献“belda,s.,pipia,l.,morcillo-pallarés,p.,rivera-caicedo,j.p.,amin,e.,de grave,c.,verrelst,j.,2020.datims:a machine learning time seriesgui toolbox for gap-filling and vegetation phenology trends detection[j].environmental modelling&software,127,104666.”、“li,w.,xin,q.,zhou,x.,zhang,z.,ruan,y.,2021.comparisons of numerical phenology models and machinelearning methods on predicting the spring onset of natural vegetation acrossthe northern hemisphere[j].ecological indicators,131,600108126.”、“wang,j.,zhang,x.,rodman,k.,2021.land cover composition,climate,and topography driveland surface phenology in a recently burned landscape:an application ofmachine learning in phenological modeling[j].agricultural and forestmeteorology,304–305,108432.”以及“zhu,y.,chen,m.,gu,q.,zhao,y.,zhang,x.,sun,q.,gu,x.,zheng,k.,2022.machine learning methods for efficient and automatedin situ monitoring of peach flowering phenology[j].computers and electronicsin agriculture,202,107370.”均采用了该技术进行物候预测。然而,基于机器学习技术建立的数据驱动模型的预测能力受到数据类型的显著影响,并且该模型属于“黑箱”模型,难以定量表征数据和变量之间的物理机制,这也限制了数据驱动模型在泛化预测和解译物理规律方面的应用。因此,为了提高机器学习技术的适用性以及数据驱动模型的泛化能力,亟需一种可解释的数据驱动模型,合理确定水稻预测模型的建模数据,并从物理机制层面解释环境因素对水稻物候发展变化的影响机制,完成水稻物候的准确建模与预测,为指导水稻田间管理和作物增产提供方法。
技术实现思路
1、本发明的目的在于针对现有技术的不足之处,提出一种数据驱动的可解释性水稻物候预测方法,通过量化不同类型数据对所预测因子的影响,合理确定水稻物候预测的关键建模数据,并从物理层面分析环境因素对物候发育的影响机制。
2、为实现上述目的,本发明通过以下技术方案实现:
3、一种数据驱动的可解释性水稻物候预测方法,包括如下步骤:
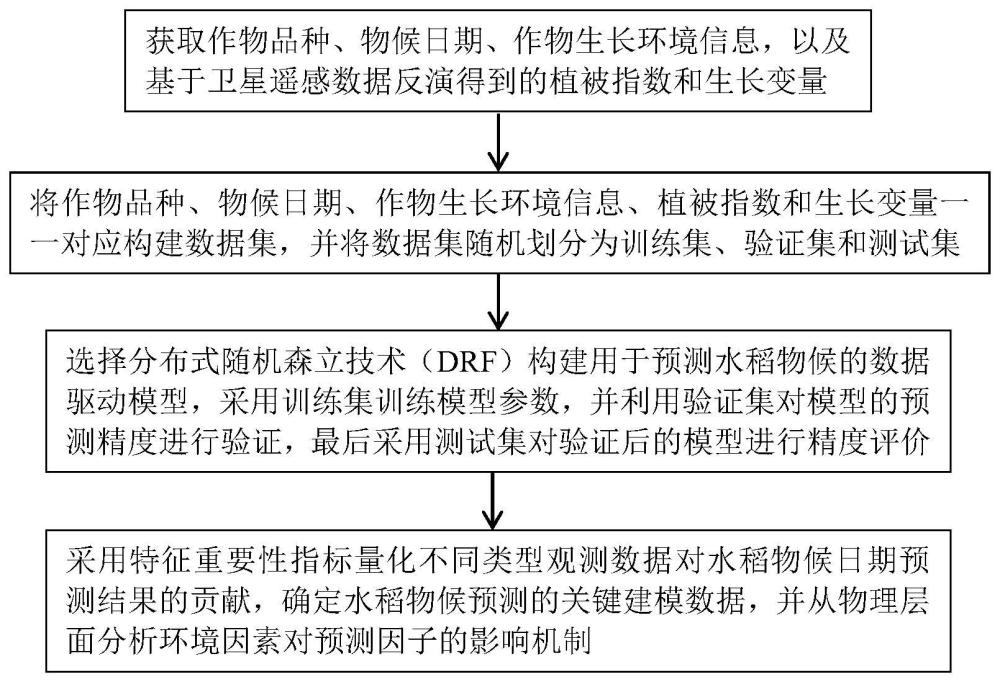
4、步骤1:获取作物品种、物候日期、作物生长环境信息,以及基于卫星遥感数据反演得到的植被指数和生长变量;
5、步骤2:将作物品种、物候日期、作物生长环境信息、植被指数和生长变量一一对应构建数据集,并将数据集随机划分为训练集、验证集和测试集;
6、步骤3:选择分布式随机森立技术(drf)构建用于预测水稻物候的数据驱动模型,采用训练集训练模型参数,并利用验证集对模型的预测精度进行验证,最后采用测试集对验证后的模型进行精度评价;
7、步骤4:采用特征重要性指标量化不同类型观测数据对水稻物候日期预测结果的贡献,确定水稻物候预测的关键建模数据,并从物理层面分析环境因素对预测因子的影响机制。
8、进一步地,作物品种包括龙粳31(最大11叶龄)和绥粳18(最大12叶龄)的水稻。
9、进一步地,物候日期包括育苗、移苗、拔节、开花和成熟日期。
10、进一步地,作物生长环境信息包括水稻的育苗模式、移苗时间、农田土壤理化特性和水稻生长地的气象数据。
11、进一步地,基于卫星数据反演得到的植被指数包括差值环境植被指数dvi、地表水分指数lswi、归一化植被指数ndvi、比值植被指数rvi和rb、土壤调节植被指数savi、三角植被指数tvi、keetch-byram干旱指数kbdi,生长变量包括叶面积指数lai和蒸散发量et。
12、进一步地,步骤3建立预测模型的具体过程为:首先,确定输入变量和预测因子,将移栽日期、积温、水稻品种和栽培模式,以及基于卫星遥感数据反演得到的植被指数和作物生长变量作为输入变量,将水稻拔节和开花日期作为预测因子;其次,确定机器学习算法和相关参数,选择学习能力强大且应用广泛的分布式随机森立技术(drf)构建预测模型,利用训练集对模型参数进行训练,并最终确定模型结构和参数;最后,模型精度验证及评价,利用验证集对模型的预测精度进行验证,利用测试集对验证后的模型采用均方根误差(rmse)、相对误差平均值(mape)和决定系数(r2)进行预测精度评价。
13、进一步地,步骤4利用分布式随机森林技术(drf)内置的特征属性方法(featureattribution method)完成对数据驱动的预测模型中不同输入变量对水稻拔节和开花日期预测结果的特征重要性分析,实现量化不同输入变量对水稻物候日期预测的贡献,该方法可以通用于不同领域或情景下的特征重要性分析,特征重要性的计算过程包含以下三步,首先,将训练集随机生成多个子样本,并基于子样本生成多棵决策树;其次,在每棵决策树的训练过程中,每个特征会根据决策树节点分裂中所带来的不纯度的减少量来进行排序;最后,计算每个特征在所有决策树中平均不纯度减少量,并依此完成特征重要性计算,数据的特征重要性用0~1的数值进行表征,数值越大表明该数据越重要,对预测因子的贡献越大,通常最重要的一类数据的特征重要性为1,依据特征重要性分析结果,可以合理确定水稻物候日期预测的关键建模数据,并且可以从物理机制层面解译环境因素对水稻物候发展变化的影响机制。
14、与现有技术相比,本发明的有益技术效果为:
15、利用机器学习技术构建了用于水稻物候预测的数据驱动模型,实现了对不同品种、农场的水稻拔节和开花日期的准确预测;同时,量化了不同类型的观测数据对预测变量的重要性,实现了对数据驱动模型的数据价值分析和物理机制解译,解决了传统数据驱动预测模型经验性强、泛化能力弱等问题,并且阐明了环境因素对水稻物候发育的影响机理,在准确预测水稻长势的同时,也为机器学技术在农业领域的推广应用提供重要参考。
- 还没有人留言评论。精彩留言会获得点赞!