基于生成对抗网络的物流车辆轨迹隐私保护方法及装置
本发明属于工业物联网,涉及数据生成与处理,具体基于生成对抗网络的物流车辆轨迹隐私保护方法及装置。
背景技术:
1、现代社会的发展离不开工业,工业革命对人类生产力的影响巨大。工业物联网的核心是互联,它将工厂、设备、供应商、客户和产品等紧密地连在一起,最终目的是实现工业领域的自动化、智能化、信息化。在工业领域中,原材料的购买以及成品的运输等都需要用到物流,智能物流是工业物联网的重要应用之一,也是组成工业物联网系统的关键部分。
2、物流企业通常需要收集物流数据,尤其是货车的轨迹数据。物流企业可以通过对大量的货车轨迹数据进行分析,来获取物流热点区域和路线潮汐、路线优先级和路线规划,以及优化物流路线和资源调度等。由于多数企业使用云平台来存储和维护数据,因此大量的轨迹数据也会被上传到云平台中。虽然近年来云平台的安全性和可靠性都有了很大提升,但仍然无法保证数据不会出现泄露问题,使企业数据隐私面临泄露的风险。如果大量的轨迹数据泄露,那么物流企业的仓库位置、集散中心以及运营机制等敏感信息就有泄露的风险。例如,企业a的竞争对手b可以通过对物流轨迹数据的分析得到a的发货量、收发地址的具体位置等敏感信息,从而可能让企业a处于不利的竞争地位,也会让企业a对物流企业失去信任。因此,物流企业和其客户通常不愿意与外部共享物流数据。
3、而现有技术中的智能物流车辆的轨迹隐私保护方法,没有一种可以同时具有抵抗背景知识攻击、保护算法程序泄露后的隐私以及对轨迹数据个性化混淆处理的功能。
技术实现思路
1、针对现有技术的不足,本发明提出了基于生成对抗网络的物流车辆轨迹隐私保护方法及装置,通过生成对抗网络输出生成轨迹数据,利用生成轨迹数据对原始轨迹数据进行混淆,并针对停留点这类敏感坐标点进行了更强隐私性的处理,能够同时实现抵抗背景知识攻击、保护算法程序泄露后的隐私以及对轨迹数据个性化混淆处理。
2、基于生成对抗网络的物流车辆轨迹隐私保护方法,具体包括以下步骤:
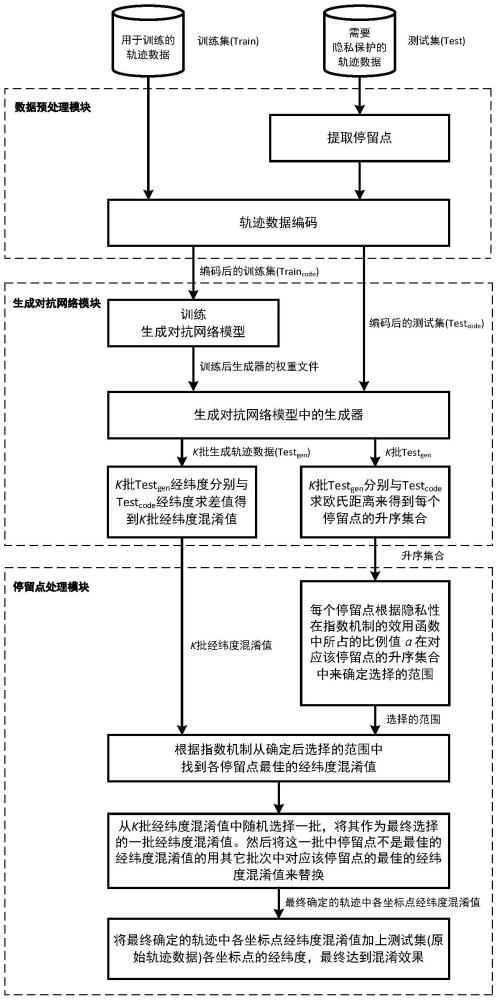
3、步骤1、数据预处理
4、数据预处理过程首先提取原始轨迹数据中的停留点,然后将原始轨迹数据编码,从而形成编码后的轨迹数据,具体步骤如下:
5、步骤1.1、收集用于训练生成对抗网络的轨迹数据,作为训练集dtrain,其中第j个轨迹数据tj由多个坐标点组成,其中pi={lati,loni,timei}表示轨迹数据tj中的第i个坐标点pi的信息,lati、loni和timei分别表示该点的纬度、经度和时间。收集需要进行隐私保护的轨迹数据,作为测试集dtest。
6、步骤1.2、设置距离阈值dthreshold和时间阈值tthreshold。遍历测试集dtest中每个坐标点,依次计算相邻两个坐标点之间的距离,对于第一对距离小于距离阈值dthreshold的相邻坐标点,将前一个坐标点记为pstart,接着向后遍历,直至出现两个相邻坐标点间的距离大于距离阈值dthreshold时,将前一个坐标点记为ppre,计算pstart与ppre之间的时间差,若该时间差大于时间阈值tthreshold,则将{pstart,...,ppre}视为一段停留轨迹,将ppre视为停留点sp,放入停留点集合sstay中,同时从测试集dtest中删除停留轨迹上的其他坐标点。以此类推,直至找到测试集dtest中的所有停留轨迹与停留点。
7、步骤1.3、将训练集dtrain和步骤1.2处理后的测试集dtest中每个坐标点的纬度和经度分别求各自的质心得到和
8、
9、
10、
11、
12、其中,dtrain.lati和dtrain.loni分别为训练集中第i个坐标点的纬度和经度。dtest.lati和dtest.loni分别为测试集中第i个坐标点的经度和纬度。n和m分别表示训练集和测试集中的坐标点数量。
13、步骤1.4、将训练集dtrain中每一个坐标点的纬度和经度分别与纬度质心和经度质心求偏差,得到对测试集dtest中每一个坐标点的纬度和经度分别与纬度质心和经度质心求偏差,得到
14、步骤1.5、将经过步骤1.4处理的坐标点的经纬度分别与10-2比较,如果经度或纬度大于10-2,则将经度或纬度不断乘以10-1,直至其经度与纬度的值均小于10-2,得到编码后的训练集和测试集。
15、步骤2、生成对抗网络模型训练和混淆值生成
16、构建生成对抗网络模型,输入步骤1编码后的训练集。模型中的生成器会根据输入数据以及噪声输出生成轨迹数据,所述生成轨迹数据和输入的编码后的训练集数据相近,但存在一定区别,两者的相近程度会随着训练轮数增加而更加接近。向判别器输入生成器输出的生成轨迹数据,与编码后的训练集数据进行比较,判别器会判断输入数据是否为编码后的训练集数据,其判别能力也会随着训练轮数增加而增强。生成器和判别器两者通过博弈来完成模型训练,具体步骤如下:
17、步骤2.1、将编码后训练集中的轨迹数据输入生成对抗网络模型中。生成器将编码后的轨迹数据中的每个坐标点转换为嵌入向量
18、
19、其中,wec表示编码后的轨迹数据输入多层感知机(mlp)时的嵌入权重矩阵。fc()函数用于根据输入的编码后的轨迹数据调整嵌入权重矩阵,输出嵌入向量
20、步骤2.2、将步骤2.1得到的嵌入向量与随机噪声拼接,作为多对多结构的lstm模型的输入特征f,得到时间步长与输入特征f相同的输出特征o:
21、o=lstm(f,wlstm) (6)
22、其中,f={f1,...,fn},fi是编码后第i个坐标点的特征向量。wlstm为所述多对多结构的lstm模型的权重矩阵。
23、步骤2.3、使用两个带有双曲正切函数(tanh)的密集层单元dc来解码步骤2.2得到的输出特征o,从而得到与输入的编码轨迹数据相对应的生成轨迹数据(△lati′,△loni′):
24、(△lati′,△loni′)=dc(oi,wd) (7)
25、其中,oi表示输出特征o中的第i个特征。wd表示密集层单元dc的权重矩阵。
26、步骤2.4、判别器将步骤2.3得到的生成轨迹数据(△lati′,△loni′)转换为嵌入向量
27、
28、其中,函数用于根据输入的生成轨迹数据来调整嵌入权重矩阵w′ec。
29、步骤2.5、将步骤2.4得到的嵌入向量输入一个多对一结构的lstm模型中,得到标量
30、
31、其中,是生成轨迹中第i个坐标点的特征向量。w′lstm表示所述多对一结构的lstm模型的权重矩阵。
32、步骤2.6、将标量通过一个带有sigmod激活函数的密集层单元dbc进行解码,并完成二分类:
33、
34、其中,bc表示判别器输出的二分类结果,即输入数据为编码后的轨迹数据或生成器输出的生成轨迹数据,w′bc表示密集层单元dbc的权重矩阵。
35、步骤2.7、上述步骤中的生成器和判别器会根据设置的训练轮数epoch和损失函数来不断地进行对抗训练,以得到不同的权重文件,设置总损失函数为:
36、loss(lr,ls,tr,ts)=λlbce(lr,ls)+βlcoordinate(tr,ts) (11)
37、其中,lr和ls分别表示输入到判别器的轨迹数据的真实轨迹标签和识别出的轨迹标签。tr和ts分别表示输入到生成器的轨迹数据和生成器输出的生成轨迹数据。lbce表示二进制交叉熵损失函数。lcoordinate表示使用最小二乘误差来计算两个轨迹之间相似性的损失函数。λ和β分别表示总损失函数中lbce和lcoordinate的权重值。
38、步骤2.8、将编码后的测试集数据输入到训练后的生成器中,通过生成器输出k批生成轨迹数据,然后将生成轨迹数据的经纬度与编码后的测试集数据的经纬度相减,得到轨迹中各坐标点经纬度的差值,将该差值作为轨迹中各坐标点的经纬度混淆值,注意,每个坐标点的纬度和经度的混淆值是不同的,都是通过各自独立求差值计算得到。此外,由于生成对抗网络模型训练后,是会学习到各坐标点之间方向的变化,因此上述得到的经纬度混淆值在最后加上原始轨迹数据后得到的混淆后轨迹数据的方向变化会趋向于原始轨迹数据的方向变化,不会像普通随机数的混淆值方式出现和原始轨迹数据方向变化完全不一致的情况。
39、步骤3、停留点处理
40、首先从步骤2.8得到的k批经纬度混淆值中选择一批,记为kselect。然后在k批的停留点经纬度混淆值中选择出最合适的停留点经纬度混淆值来替代kselect中对应停留点的经纬度混淆值。最后令确定的各坐标点经纬度混淆值加上原始轨迹数据,得到混淆后的轨迹数据,具体步骤如下:
41、步骤3.1、根据停留点集合sstay,确定k批生成轨迹中每个停留点的经纬度,依次计算每个停留点在k批生成轨迹中的位置与经过步骤1中编码后的位置之间的欧氏距离。
42、步骤3.2、将每个停留点对应的k个欧氏距离的值按由大到小的顺序进行排列,用lists代表第s个停留点的欧氏距离排列集合,设置隐私性所占的比例值α,α∈[0,1]。
43、步骤3.3、根据设置的隐私性所占比例值α确定混淆值的选择范围[left,right]:
44、
45、步骤3.4、使用欧氏距离和曼哈顿距离来作为指数机制中的效用函数
46、
47、其中,norm()表示最大最小归一化。eucl()表示计算欧氏距离,manh()表示计算曼哈顿距离。表示生成轨迹数据中的第s个停留点;表示编码后的轨迹数据中的第s个停留点。sel表示混淆值批次,left≤sel≤right。
48、步骤3.5、定义指数机制中的敏感度△u:
49、
50、步骤3.6、根据公式(15),选择令概率值最大的第sel批生成轨迹的经纬度混淆值,作为第s个停留点的经纬度混淆值,这个经纬度混淆值会替代kselect中对应的该停留点的经纬度混淆值:
51、
52、其中,ε表示指数机制中的隐私预算参数。
53、步骤3.7、最后将经过替换后的生成轨迹kselect中每个坐标点的经纬度混淆值与原始轨迹数据中的经纬度相加,完成轨迹的隐私保护。
54、基于生成对抗网络的物流车辆轨迹隐私保护装置,包括数据预处理模块、生成对抗网络模块和停留点处理模块。
55、所述的数据预处理模块收集用于训练生成对抗网络的轨迹数据作为训练集,把需要隐私保护的轨迹数据作为测试集。对于测试集需要提取停留点处理,通过将停留轨迹转换成单个坐标点即停留点,这样可以防止轻易的识别出停留点这类敏感位置。接下来将训练集和测试集分别独立求质心偏差并让每个经纬度的值都小于10-2,其原因是控制后续步骤得到的经纬度混淆值的范围,可以控制最终的混淆距离在百米至千米之间。
56、所述的生成对抗网络模块首先将生成对抗网络模型进行训练,得到训练轮数的权重文件,该训练轮数权重决定了整体混淆程度。训练完成后,将编码后的需要隐私保护的轨迹数据(测试集)输入到生成器中输出k批生成轨迹数据,然后将这k批生成轨迹数据经纬度与输入到生成对抗网络模块前的编码后的轨迹数据经纬度相减得到差值作为轨迹中各坐标点的经纬度混淆值,即可以得到k批经纬度混淆值。
57、所述的停留点处理模块首先将k批生成轨迹数据与输入到生成对抗网络模块前的编码后的轨迹数据求欧氏距离并升序排列。然后可以设置隐私性在指数机制的效用函数中所占比例值α来确定每个停留点各自在这k批经纬度混淆值选择的范围,最后根据指数机制在这选择范围内确定一个最佳的经纬度混淆值来作为该停留点最后的经纬度混淆值。
58、本发明具有以下有益效果:
59、1、本方法属于语义隐私的范畴,通过对每个坐标点的经纬度都进行混淆,即使上传到云端的轨迹数据遭到泄漏,攻击者根据其它属性信息推断出属于用户的轨迹,该轨迹也是经过混淆后的轨迹数据,能够抵抗背景知识攻击。
60、2、将原始轨迹数据进行提取停留点处理,可以防止攻击者根据一连串邻近的坐标点判断出该点为停留点,从而暴露位置敏感的停留点。然后将经过提取停留点处理后的轨迹数据进行编码,求质心偏差并让其缩小直到小于10-2。这样可以控制后续经纬度混淆值的范围,使其保持在百米到千米的混淆范围之间。
61、3、在生成对抗网络模块中,将生成对抗网络模型训练后得到的权重文件和数据预处理模块得到的编码后的轨迹数据输入生成器从而输出k批生成轨迹数据,然后将k批生成轨迹数据经纬度与编码后的轨迹数据经纬度相减得到k批差值作为轨迹中各坐标点的经纬度混淆值。由于生成对抗网络是一种“黑匣子”的机器学习算法,没有明确的函数表示,并且每次生成的数据也是各不相同的。因此,即使算法程序暴露,攻击者也无法还原出原始轨迹数据。此外,还可以根据模型训练后的权重文件来调节需要隐私保护的轨迹数据的整体混淆程度。
62、4、根据停留点集合来对停留点逐一进行额外处理。可以根据设置的隐私性在指数机制的效用函数中所占比例值α来从k批经纬度混淆值中选择出最适合的一个作为该点最后的经纬度混淆值。如果需要在保持轨迹的整体混淆程度下单独对停留点这类坐标点提高或降低隐私性,可以增大或降低比例值α和生成对抗网络模型的输出次数k。输出次数k越多,所能取到的经纬度混淆值的范围就越广,即经纬度能取到更大或者更小的混淆值。因此可以个性化地对停留点这类敏感位置点采取额外的混淆处理。
- 还没有人留言评论。精彩留言会获得点赞!