基于对比学习的小样本分类方法及系统
本发明属于图像分类,具体涉及基于对比学习的小样本分类方法及系统。
背景技术:
1、小样本学习(few-shotlearning,fsl)是指在只有少量标注数据的情况下,训练一个模型能够识别新的类别的任务。这是一种具有挑战性的机器学习问题,因为在数据稀缺的情况下,模型很容易过拟合或欠拟合。
2、传统的深度学习方法面临着重大挑战,因为这些方法通常需要大量的标注数据才能实现良好的泛化性能。然而,在现实世界的应用中,收集和标注大量数据是昂贵和不切实际的。因此,开发能够在少量样本情况下仍然保持高性能的算法变得至关重要。小样本学习任务通常可以分为两个阶段:预训练和微调。预训练阶段,模型在一个较大的基础类数据集上学习,以获得泛化的特征提取器。微调阶段,特征提取器会被进一步调整以适应新的、少量样本的任务。
3、在这个背景下,对比学习作为一种强有力的无监督学习策略,被广泛应用于预训练阶段。对比学习旨在学习区分不同类别样本的能力,而不是在大量标注数据上进行训练。通过这种方式,模型可以学习到更加鲁棒和泛化的特征表示。然而,如何将这些特征有效地转移到新的、未见过的类别上,仍然是一个值得思考的研究问题。
技术实现思路
1、基于上述技术问题,本发明提供基于对比学习的小样本分类方法及系统,在预训练阶段使用对比学习,使得模型获得了特征提取器来适应下游任务。在适应阶段,利用正则化手段,进一步提升模型泛化能力与鲁棒性。
2、本发明提供了基于对比学习的小样本分类方法,所述方法包括:
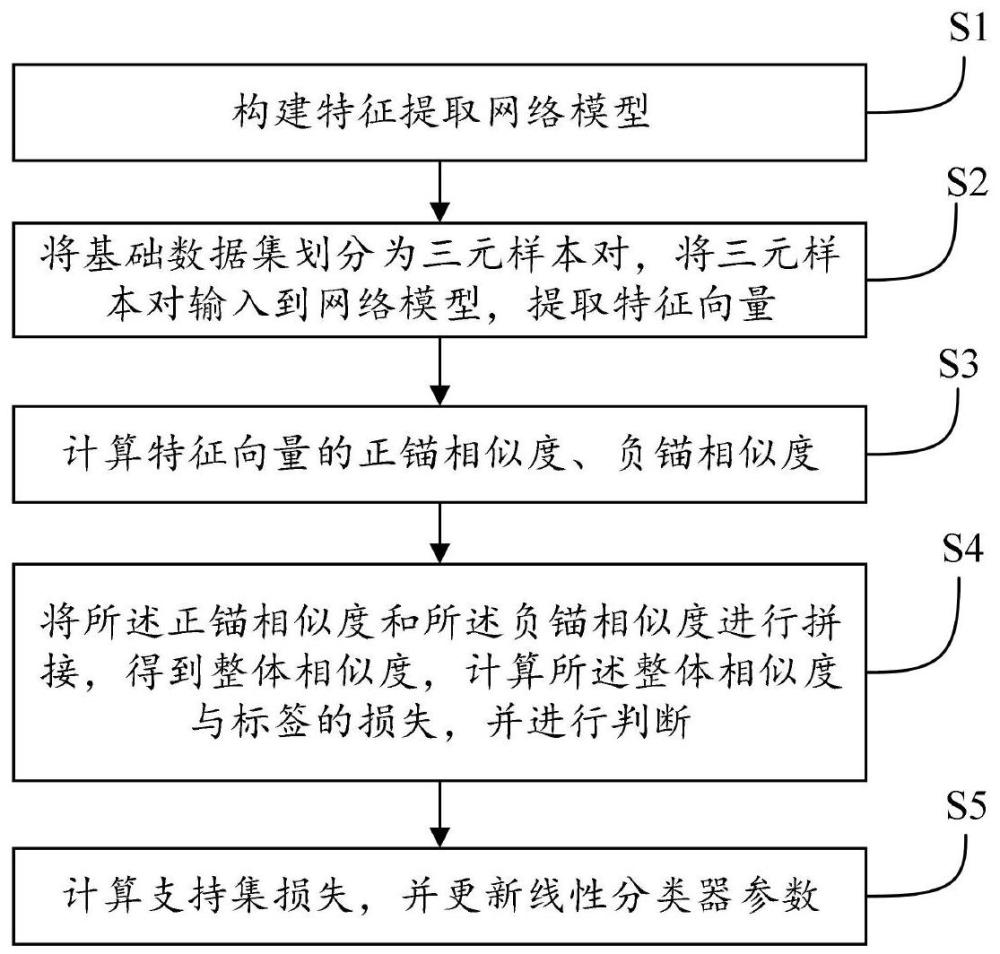
3、步骤s1:构建特征提取网络模型;所述特征提取网络模型包括两个标准卷积模块、两个残差模块、两个分离注意力模块和一个全局平均池化层模块;所述两个标准卷积模块分别为第一标准卷积模块和第二标准卷积模块,所述两个残差模块分别为第一残差模块和第二残差模块,所述两个分离注意力模块分别为第一分离注意力模块和第二分离注意力模块;
4、步骤s2:将基础数据集划分为三元样本对,将所述三元样本对输入到所述特征提取网络模型,提取正样本特征向量,负样本特征向量,锚点样本特征向量;所述三元样本对包括正样本、锚点样本和负样本;
5、步骤s3:计算所述锚点样本特征向量与所述正样本特征向量的余弦相似度,得到正锚相似度;计算所述锚点样本特征向量与所述负样本特征向量的余弦相似度,得到负锚相似度;
6、步骤s4:将所述正锚相似度和所述负锚相似度进行拼接,得到整体相似度,计算所述整体相似度与标签的损失,判断所述损失是否小于或等于第一阈值;如果所述损失大于所述第一阈值,则返回“步骤s2”;如果所述损失小于或等于所述第一阈值,则执行“步骤s5”;
7、步骤s5:计算支持集损失,并更新线性分类器参数。
8、可选地,所述第一残差模块,具体包括:
9、所述第一残差模块包括第一残差输入层、第二标准卷积层、第二规范化激活层、第三标准卷积层、第三规范化激活层、第一元素相加层、第四标准卷积层、第四规范化激活层、第二元素相加层、第五标准卷积层、第五规范化激活层、第一张量拼接层、第六标准卷积层、第一批归一化层、第七标准卷积层、第二批归一化层、第三元素相加层和第一激活函数层;
10、将所述第一残差输入层的特征图f2依次输入到所述第二标准卷积层和所述第二规范化激活层进行卷积和激活操作,得到特征图f4;
11、将所述特征图f4依次输入到所述第三标准卷积层和所述第三规范化激活层进行卷积和激活操作,得到特征图f6;
12、将所述特征图f4和所述特征图f6输入到所述第一元素相加层进行元素相加操作,得到特征图f7;
13、将所述特征图f7依次输入到所述第四标准卷积层和所述第四规范化激活层进行卷积和激活操作,得到特征图f9;
14、将所述特征图f7和所述特征图f9输入到所述第二元素相加层进行元素相加操作,得到特征图f10;
15、将所述特征图f10依次输入到所述第五标准卷积层和所述第五规范化激活层进行卷积和激活操作,得到特征图f12;
16、将所述特征图f4、所述特征图f6、所述特征图f9和所述特征图f12输入到所述第一张量拼接层进行张量拼接操作,得到特征图f13;
17、将所述特征图f13依次输入到所述第六标准卷积层和所述第一批归一化层进行卷积和归一化操作,得到特征图f15;
18、将所述第一残差输入层的所述特征图f2依次输入到所述第七标准卷积层和所述第二批归一化层进行卷积和归一化操作,得到特征图f17;
19、将所述特征图f15和所述特征图f17输入到所述第三元素相加层进行元素相加操作,得到特征图f18;
20、将所述特征图f18输入到所述第一激活函数层进行激活操作,得到特征图f19。
21、可选地,所述第一分离注意力模块,具体包括:
22、所述第一分离注意力模块包括第一分离注意力输入层、第一全局平均池化层、第一全连接激活层、第二全连接激活层、第一维度扩展层、第二维度扩展层、第一元素相乘层、第一最大池化层、第一平均池化层、第二张量拼接层、第八标准卷积层、第二激活函数层、第二元素相乘层、第一深度可分离卷积层和第六规范化激活层;
23、将所述第一分离注意力输入层的特征图f19输入到所述第一全局平均池化层进行全局平均池化操作,得到特征图f20;
24、将所述特征图f20依次输入到所述第一全连接激活层和所述第二全连接激活层进行全连接激活操作,得到特征图f24;
25、将所述特征图f24依次输入到所述第一维度扩展层和所述第二维度扩展层进行维度扩展操作,得到特征图f26;
26、将所述第一分离注意力输入层的所述特征图f19和所述特征图f26输入到所述第一元素相乘层进行元素相乘操作,得到特征图f27;
27、将所述第一分离注意力输入层的所述特征图f19输入到所述第一最大池化层进行最大池化操作,得到特征图f28;
28、将所述第一分离注意力输入层的所述特征图f19输入到所述第一平均池化层进行平均池化操作,得到特征图f29;
29、将所述特征图f28和所述特征图f29输入到所述第二张量拼接层进行张量拼接操作,得到特征图f30;
30、将所述特征图f30依次输入到所述第八标准卷积层和所述第二激活函数层进行卷积和激活操作,得到特征图f32;
31、将所述特征图f27和所述特征图f32输入到所述第二元素相乘层进行元素相乘操作,得到特征图f33;
32、将所述特征图f33依次输入到所述第一深度可分离卷积层和所述第六规范化激活层进行卷积核激活操作,得到特征图f35。
33、可选地,所述计算所述锚点样本特征向量与所述正样本特征向量的余弦相似度,得到正锚相似度,计算所述锚点样本特征向量与所述负样本特征向量的余弦相似度,得到负锚相似度,具体公式为:
34、
35、
36、式中,cos(ai,pi)为正锚相似度,cos(ai,ni)为负锚相似度,ai为锚点样本特征向量,pi为正样本特征向量,ni为负样本特征向量,||||为特征向量范数,i为第i个样本对,i∈[1,m],m为三元样本对总数。
37、可选地,所述计算支持集损失,并更新线性分类器参数,具体公式为:
38、pj=softmax(w·f(xj)+b)
39、
40、
41、式中,xj为支持集样本图片,yj为支持集样本图片对应标签,w为分类器权重,f(xj)为支持集样本图片经过所述特征提取网络模型得到的特征向量,b为偏置量,pj为预测标签值,regularization为熵正则化项,crossentropy为交叉熵损失函数。
42、本发明还提供基于对比学习的小样本分类系统,所述系统包括:
43、网络模型构建模块,用于构建特征提取网络模型;所述特征提取网络模型包括两个标准卷积模块、两个残差模块、两个分离注意力模块和一个全局平均池化层模块;所述两个标准卷积模块分别为第一标准卷积模块和第二标准卷积模块,所述两个残差模块分别为第一残差模块和第二残差模块,所述两个分离注意力模块分别为第一分离注意力模块和第二分离注意力模块;
44、特征向量提取模块,用于将基础数据集划分为三元样本对,将所述三元样本对输入到所述特征提取网络模型,提取正样本特征向量,负样本特征向量,锚点样本特征向量;所述三元样本对包括正样本、锚点样本和负样本;
45、余弦相似度计算模块,用于计算所述锚点样本特征向量与所述正样本特征向量的余弦相似度,得到正锚相似度;计算所述锚点样本特征向量与所述负样本特征向量的余弦相似度,得到负锚相似度;
46、训练损失计算模块,用于将所述正锚相似度和所述负锚相似度进行拼接,得到整体相似度,计算所述整体相似度与标签的损失,判断所述损失是否小于或等于第一阈值;如果所述损失大于所述第一阈值,则返回“特征向量提取模块”;如果所述损失小于或等于所述第一阈值,则执行“损失参数更新模块”;
47、损失参数更新模块,用于计算支持集损失,并更新线性分类器参数。
48、可选地,所述第一残差模块,具体包括:
49、第二标准卷积子模块,用于将第一残差输入层的特征图f2依次输入到第二标准卷积层和第二规范化激活层进行卷积和激活操作,得到特征图f4;
50、第三标准卷积子模块,用于将所述特征图f4依次输入到第三标准卷积层和第三规范化激活层进行卷积和激活操作,得到特征图f6;
51、第一元素相加子模块,用于将所述特征图f4和所述特征图f6输入到第一元素相加层进行元素相加操作,得到特征图f7;
52、第四标准卷积子模块,用于将所述特征图f7依次输入到第四标准卷积层和第四规范化激活层进行卷积和激活操作,得到特征图f9;
53、第二元素相加子模块,用于将所述特征图f7和所述特征图f9输入到第二元素相加层进行元素相加操作,得到特征图f10;
54、第五标准卷积子模块,用于将所述特征图f10依次输入到第五标准卷积层和第五规范化激活层进行卷积和激活操作,得到特征图f12;
55、第一张量拼接子模块,用于将所述特征图f4、所述特征图f6、所述特征图f9和所述特征图f12输入到第一张量拼接层进行张量拼接操作,得到特征图f13;
56、第六标准卷积子模块,用于将所述特征图f13依次输入到第六标准卷积层和第一批归一化层进行卷积和归一化操作,得到特征图f15;
57、第七标准卷积子模块,用于将所述第一残差输入层的所述特征图f2依次输入到第七标准卷积层和第二批归一化层进行卷积和归一化操作,得到特征图f17;
58、第三元素相加子模块,用于将所述特征图f15和所述特征图f17输入到第三元素相加层进行元素相加操作,得到特征图f18;
59、第一激活函数子模块,用于将所述特征图f18输入到第一激活函数层进行激活操作,得到特征图f19。
60、可选地,所述第一分离注意力模块,具体包括:
61、将第一分离注意力输入层的特征图f19输入到第一全局平均池化层进行全局平均池化操作,得到特征图f20;
62、第一二全连接激活子模块,用于将所述特征图f20依次输入到第一全连接激活层和第二全连接激活层进行全连接激活操作,得到特征图f24;
63、第一二维度扩展子模块,用于将所述特征图f24依次输入到第一维度扩展层和第二维度扩展层进行维度扩展操作,得到特征图f26;
64、第一元素相乘子模块,用于将所述第一分离注意力输入层的所述特征图f19和所述特征图f26输入到第一元素相乘层进行元素相乘操作,得到特征图f27;
65、第一最大池化子模块,用于将所述第一分离注意力输入层的所述特征图f19输入到所述第一最大池化层进行最大池化操作,得到特征图f28;
66、第一平均池化子模块,用于将所述第一分离注意力输入层的所述特征图f19输入到所述第一平均池化层进行平均池化操作,得到特征图f29;
67、第二张量拼接子模块,用于将所述特征图f28和所述特征图f29输入到第二张量拼接层进行张量拼接操作,得到特征图f30;
68、第八标准卷积子模块,用于将所述特征图f30依次输入到第八标准卷积层和第二激活函数层进行卷积和激活操作,得到特征图f32;
69、第二元素相乘子模块,用于将所述特征图f27和所述特征图f32输入到第二元素相乘层进行元素相乘操作,得到特征图f33;
70、第一深度可分离子模块,用于将所述特征图f33依次输入到第一深度可分离卷积层和第六规范化激活层进行卷积核激活操作,得到特征图f35。
71、可选地,所述余弦相似度计算模块,具体公式为:
72、
73、
74、式中,cos(ai,pi)为正锚相似度,cos(ai,ni)为负锚相似度,ai为锚点样本特征向量,pi为正样本特征向量,ni为负样本特征向量,||||为特征向量范数,i为第i个样本对,i∈[1,m],m为三元样本对总数。
75、可选地,所述损失参数更新模块,具体公式为:
76、pj=softmax(w·f(xj)+b)
77、
78、
79、式中,xj为支持集样本图片,yj为支持集样本图片对应标签,w为分类器权重,f(xj)为支持集样本图片经过所述特征提取网络模型得到的特征向量,b为偏置量,pj为预测标签值,regularization为熵正则化项,crossentropy为交叉熵损失函数。
80、本发明与现有技术相比,具有以下有益效果:
81、本发明通过构建高效的特征提取网络模型,该方法能够更好地理解和区分不同类别的样本,特别是在样本数量有限的情况下。残差模块的使用可以帮助网络学习深层特征而不丢失细节信息,而分离注意力模块则可以增加模型对关键特征的关注,这都有助于提高分类的准确性;使用残差模块和注意力机制可以使网络在增加深度的同时减少训练中的过拟合问题,因为这些模块可以通过跳跃连接和聚焦于重要特征来避免梯度消失和过度依赖少数特征;通过对比学习的方式,模型不仅学习单个样本的特征表示,还学习样本之间的相似性和差异性,这种方式有助于模型在遇到未见过的数据时更好地泛化;在训练时,模型采用小批量的三元样本对,减少了计算资源的需求,这对于资源受限的环境特别有益,也使得这种方法在实际应用中更加灵活和高效;在迁移学习的适应阶段,模型能够快速地适应新任务,这使得模型在实际应用中更加有效和实用;通过在微调阶段引入正则化手段,模型的泛化能力和鲁棒性得到了显著提升。
- 还没有人留言评论。精彩留言会获得点赞!