一种基于对比学习和双曲图卷积网络的国际疾病分类方法
本技术属于数据处理,尤其涉及一种基于对比学习和双曲图卷积网络的国际疾病分类方法。
背景技术:
1、国际疾病分类(icd)是世界卫生组织推出的疾病分类标准,已广泛应用于健康监测、医疗数据分析、医疗报销定价等领域。icd也是智能医疗应用的有效标准和基础。它以独立的代码结束,并描述了病因、病理、症状和解剖位置。
2、国际疾病分类通常需要临床医生手动将国际疾病分类编码分配到临床文档,这是费时费力且易出错的。因此,已经有很多研究引入了用于自动国际疾病分类编码的方法。自动化icd编码的主要挑战包括标签分布不平衡、代码层次结构和噪声文本。
3、标签分布不均衡:mimic-iii数据集中的标签不平衡并呈现长尾分布,有大量的数据在头部类别和少量的数据在尾部类别中,主要是有些疾病类型比较罕见。一些标签经常出现,但大多数标签只有少量数据并且从未出现过,导致国际疾病分类编码的长尾分布。在mimic-iii数据集中,近50%的代码仅出现1至5次。同时提高预测密集和稀疏数据的精度显得尤为重要。而主要难点就是解决分类问题中不常见的标签。
4、代码层次结构:在icd编码系统中观察到树状层次结构,其中上层节点对应于更广泛的疾病类别,而下层节点对应于更具体的疾病。一方面,层次结构可以解释一些代码是互斥的。共享父节点的最后一层兄弟节点不能同时指定为父节点或子节点。另一方面,距离较小的代码更相关。如果码树中a和b之间的距离小于b和c之间的距离,则在icd预测中a比c更有可能是正确码。
5、噪声文本:在编写诊断描述时,具有不同写作风格的医生经常使用缩写和同义词,这在专业编码人员将icd代码分配给医疗描述时可能会导致潜在的错误和歧义。据统计,临床文档中只有10%的单词与icd编码相关。因此,存在大量冗余或误导性信息,可能对自动icd编码产生不利影响。如何应对也是一个至关重要的问题。
6、现阶段有人考虑使用代码层次结构和描述来更好地表示标签,以解决不平衡数据的分类问题;一种常见方法是分别对文本和标签进行编码,然后在分类之前使用特征聚合层将它们组合起来。这些方法虽然可以将文档表示与标签特征充分结合起来以致于增强了表示,这对于标签分类很有用;但是标签编码器根据标签描述或层次结构为任何输入文本表示提供完全恒定且相同的标签表示。这种文本仅与恒定的层次表示进行交互是不必要的,而且效率较低。另一方面,大多数模型通过图编码器利用分类层次结构,例如图卷积神经网络(gcnn)和图通用回归神经网络(grnn)。图神经网络中的这些模型受到欧几里得几何表示的限制,并导致层次结构的巨大失真,造成国际疾病分类准确性低。
技术实现思路
1、本技术实施例提供了一种基于对比学习和双曲图卷积网络的国际疾病分类方法,可以解决国际疾病分类效率和准确性低的问题。
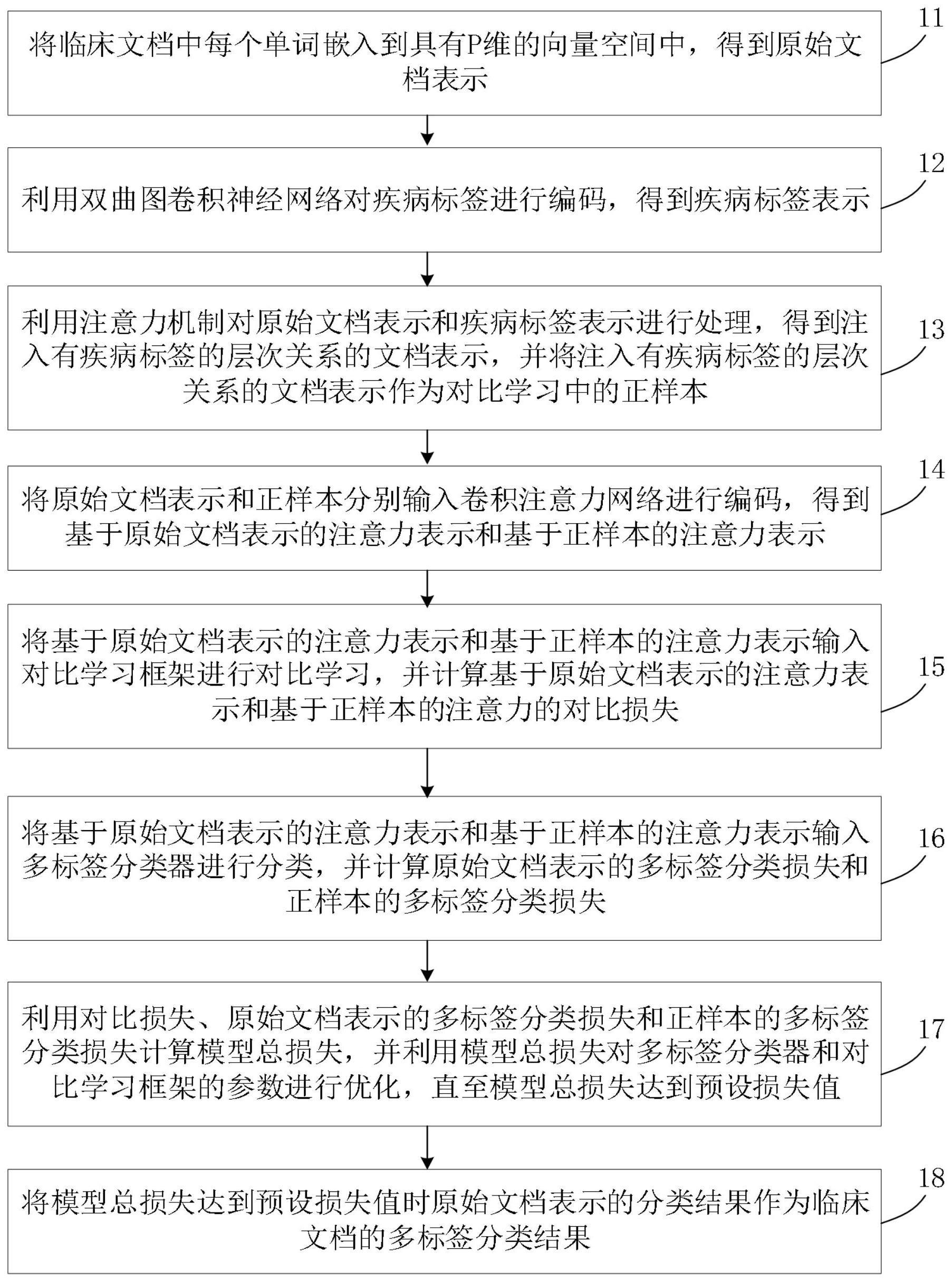
2、本技术实施例提供了一种基于对比学习和双曲图卷积网络的国际疾病分类方法,包括:
3、将临床文档中每个单词嵌入到具有p维的向量空间中,得到原始文档表示;
4、利用双曲图卷积神经网络对疾病标签进行编码,得到疾病标签表示;
5、利用注意力机制对原始文档表示和疾病标签表示进行处理,得到注入有疾病标签的层次关系的文档表示,并将注入有疾病标签的层次关系的文档表示作为对比学习中的正样本;
6、将原始文档表示和正样本分别输入卷积注意力网络进行编码,得到基于原始文档表示的注意力表示和基于正样本的注意力表示;
7、将基于原始文档表示的注意力表示和基于正样本的注意力表示输入对比学习框架进行对比学习,并计算基于原始文档表示的注意力表示和基于正样本的注意力的对比损失;
8、将基于原始文档表示的注意力表示和基于正样本的注意力表示输入多标签分类器进行分类,并计算原始文档表示的多标签分类损失和正样本的多标签分类损失;
9、利用对比损失、原始文档表示的多标签分类损失和正样本的多标签分类损失计算模型总损失,并利用模型总损失对多标签分类器和对比学习框架的参数进行优化,直至模型总损失达到预设损失值;
10、将模型总损失达到预设损失值时原始文档表示的分类结果作为临床文档的多标签分类结果。
11、可选的,将临床文档中每个单词嵌入到具有p维的向量空间中,得到原始文档表示,包括:
12、利用预先训练后的词嵌入模型将临床文档中每个单词嵌入到具有p维的向量空间,得到原始文档表示;原始文档表示为矩阵x;
13、x={x1,…,xn}
14、其中,xn表示临床文档中第n个单词对应的嵌入词向量,n表示临床文档中单词的总数。
15、可选的,利用双曲图卷积神经网络对疾病标签进行编码,得到疾病标签表示,包括:
16、利用预先训练后的词嵌入模型将每个疾病标签嵌入到具有p维的向量空间,得到疾病标签嵌入表示c;
17、利用双曲图卷积神经网络对疾病标签嵌入表示c进行编码,得到疾病标签表示g。
18、可选的,基于原始文档表示的注意力表示a为:
19、a={a1,…,aj}
20、aj表示a中的第j个隐藏表示,j为a中隐藏表示的总数;
21、基于正样本的注意力表示为:
22、
23、表示aj对应的正样本。
24、可选的,将基于原始文档表示的注意力表示和基于正样本的注意力表示输入对比学习框架进行对比学习,并计算基于原始文档表示的注意力表示和基于正样本的注意力的对比损失,包括:
25、将基于原始文档表示的注意力表示a中的隐藏表示ai和ai对应的正样本作为正示例,并将正示例输入对比学习框架进行对比学习,i=1,…,j;
26、计算隐藏表示ai和正样本的对比损失;
27、将所有正示例对应的对比损失的平均值作为基于原始文档表示的注意力表示和基于正样本的注意力的对比损失。
28、可选的,计算隐藏表示ai和正样本的对比损失,包括:
29、通过公式计算隐藏表示ai和正样本的对比损失
30、其中,sim函数表示余弦相似度的计算,zi=wsrelu(wcai),ws∈r|l|×d,wc∈rd×d,|l|表示疾病标签的总数,d表示relu输出层的输出维度,τ表示温度超参数,zk表示zi和的集合。
31、可选的,计算原始文档表示的多标签分类损失和正样本的多标签分类损失,包括:
32、通过公式计算原始文档表示的多标签分类损失lm;|l|表示疾病标签的总数,ym表示多标签分类器对原始文档表示进行分类时输出的第m个疾病标签的分类结果输出的原始文档表示的分类结果,wo表示权重,wo∈rd,d表示sigmoid输出层维度,bo表示偏差;
33、通过公式计算正样本的多标签分类损失l^m;表示多标签分类器对正样本进行分类时输出的第m个疾病标签的分类结果,
34、可选的,利用对比损失、原始文档表示的多标签分类损失和正样本的多标签分类损失计算模型总损失,包括:
35、通过公式l=lm+l^m+βlcon计算模型总损失l;lm表示原始文档表示的多标签分类损失,l^m表示正样本的多标签分类损失,lcon表示基于原始文档表示的注意力表示和基于正样本的注意力的对比损失,β表示对比损失的权重。
36、本技术的上述方案有如下的有益效果:
37、在本技术的实施例中,通过利用双曲图卷积神经网络对疾病标签进行编码来捕获不可见图上的代码层次结构和关系而不失真,从而大大提高了国际疾病分类的准确性。此外,通过注意力机制对临床文档的原始文档表示和疾病标签表示进行处理来生成分层感知的正样本,而不是聚合文本和恒定代码特征,引入自动国际疾病分类编码的对比学习,并利用对比学习损失和多标签分类损失对多标签分类器和对比学习框架进行优化,得到优化后的多标签分类结果,这种省去文本仅与恒定的层次表示进行交互这一不必要过程的方式,大大提升了国际疾病分类的效率。
38、本技术的其它有益效果将在随后的具体实施方式部分予以详细说明。
- 还没有人留言评论。精彩留言会获得点赞!