一种网络平台文本流话题热度预测方法与流程
本发明属于网络语义检测,具体涉及一种面对海量话题的网络平台文本流话题热度预测方法。
背景技术:
1、社交媒体平台网络舆论信息发布、个人观点表达和传播的中心,拥有低门槛、简洁明了和传播力强的特点。根据数据显示,到2022年底,中国网民数量已达11亿,视频社交平台的月活跃用户数量更是高达7-10亿。因此,社交媒体平台成为大多数网民首选的信息发布、分享和传播平台,这得益于其互动性、广泛的话题内容、实时性和用户自主性。随着社交媒体平台的活动增加和用户兴趣的引导,视频、文本流数据呈现爆炸性增长。这些数据包含丰富多样的内容,涵盖了人类生活的各个方面到个人的情感表达。视频、文本流数据中蕴含了大量有价值的信息,能够为个人、企业和政府等做出决策提供帮助。当发布突发公共事件或重要信息时,这些事件和信息可能会迅速在公众中引起共鸣和激烈讨论,并在平台上迅速传播扩散,形成热门话题。对于文本流数据的突发话题检测,学者们进行了广泛的研究,其中突发词对话题模型被广泛应用。然而,该模型在先验知识计算和吉布斯采样过程中,仅利用了词对的外部信息,如词对的突发概率和频率,而忽略了词对内部的信息,如词对中两个词的语义相似度。在话题热度预测方面,学者们进行了广泛研究,主要分为基于传统统计学方法和基于机器学习方法两大类。传统统计学方法包括arima模型、指数平滑模型、微分方程和logistic回归模型等。然而,这些模型的非线性拟合能力较差,对于具有无规则、随机变化和复杂性特点的话题热度预测效果有限,并且提取话题热度时间序列规律特征信息不充分,预测精度还有待提高。
技术实现思路
1、本发明的目的在于提供一种面对海量话题的网络平台文本流话题热度预测方法。
2、本发明的目的是这样实现的:
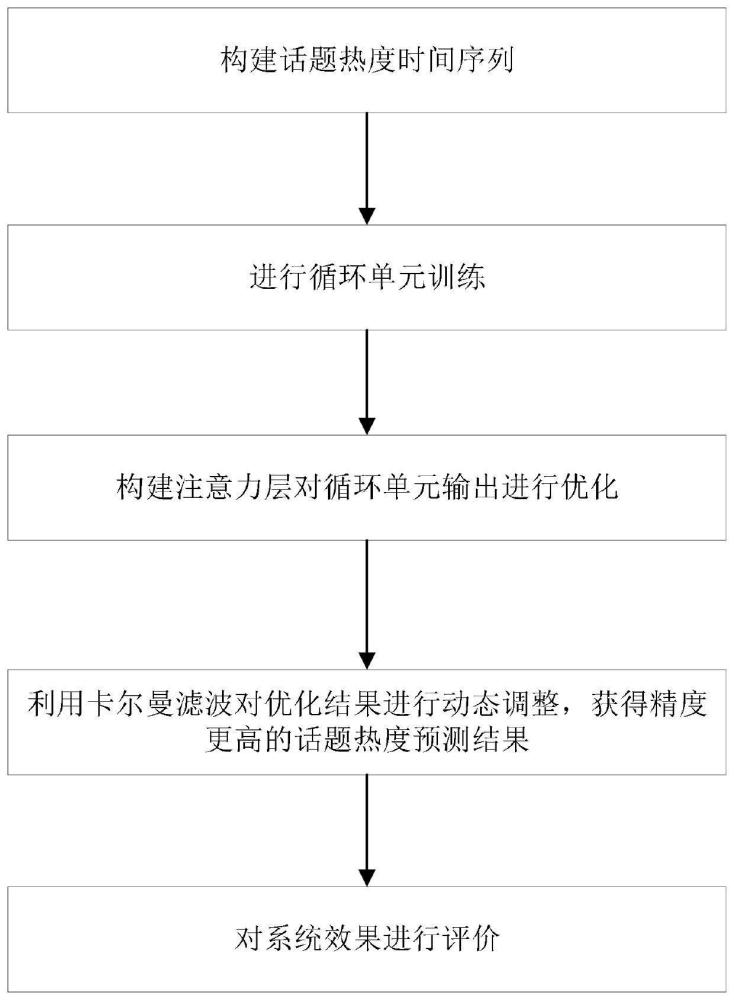
3、一种面对海量话题的网络平台文本流话题热度预测方法,包括如下步骤:
4、(1)构建话题热度时间序列;
5、(2)进行循环单元训练;
6、(3)构建注意力层对循环单元输出进行优化;
7、(4)利用卡尔曼滤波对优化结果进行动态调整,获得精度更高的话题热度预测结果;
8、(5)对系统效果进行评价。
9、所述的构建话题热度时间序列,包括:
10、(1.1)以话题名称为关键字采集连续单位时间g内发布的网络平台文本信息,以单位时间g内与话题u相关的文本总数作为热度;
11、(1.2)以时间间隔g构建话题热度的时间序列值k=[k1,k2,k3,…,kg],kv表示第v个时间段内的话题热度,v=1,2,3,…,g,g为时间序列中连续单元时间数;
12、(1.3)构建预测模型训练集[f,l]a,f=[k1,k2,k3,…,kw]为话题热度值预测的输入样本值,1≤w≤g;l=kw+1为训练输出样本值,a为训练集样本数目
13、(1.4)对k进行归一化处理。
14、所述的进行循环单元训练,包括;
15、(2.1)由一个正向gru神经网络和一个反向gru神经网络组成bigru神经网络;
16、其中,在g时刻正向gru神经网络的更新门为:
17、
18、为正向gru神经网络更新门的权重矩阵;
19、在g时刻正向gru神经网络的重置门为:
20、
21、为正向gru神经网络重置门的权重矩阵;
22、在g时刻正向gru神经网络的隐藏候选状态信息为:
23、
24、
25、为正向gru神经网络g-1时刻的隐藏候选状态信息;为正向gru神经网络g时刻的神经网络输入值也是g时刻的话题热度;为正向gru神经网络隐藏候选状态信息的权重矩阵;
26、在g时刻反向gru神经网络的更新门为:
27、
28、为反向gru神经网络更新门的权重矩阵;ζ为sigmoid函数;
29、在g时刻反向gru神经网络的重置门为:
30、
31、为反向gru神经网络重置门的权重矩阵;
32、在g时刻反向gru神经网络的隐藏候选状态信息为:
33、
34、
35、为g-1时刻反向gru神经网络的隐藏候选状态信息;为g时刻反向gru神经网络的神经网络输入值也是g时刻的话题热度;为隐藏候选状态信息的权重矩阵;
36、(2.2)获得g时刻bigru神经网络训练后的隐藏状态信息:
37、
38、ρg为g时刻反向gru神经网络的隐含层输出权重;ψg为g时刻正向gru神经网络的隐含层输出权重;og为隐藏状态信息偏置量;
39、(2.3)采用bigru对话题热度时间序列值k进行训练。
40、所述的构建注意力层对循环单元输出进行优化,包括;
41、(3.1)设置随机初始化的注意力权值ξ;
42、(3.2)计算归一化后的注意力权值:
43、n=softmax[ξtcoth(ug)];
44、(3.3)注意力层输出初始话题热度值:
45、p=ntug。
46、所述的利用卡尔曼滤波对优化结果进行动态调整,获得精度更高的话题热度预测结果,包括:
47、(4.1)估计状态变量:
48、确定从g-1时刻到g时刻的状态转移矩阵n以及控制输入和状态量之间的转换系数o,查询g-1时刻的话题热度估计值k'g-1和系统的控制输入预先估计g时刻的话题热度值:
49、
50、确定g-1时刻的均方误差矩阵cg-1和过程噪声的均方误差矩阵d,预估计g时刻的均方误差矩阵:
51、cg=d+ntcg-1n;
52、(4.2)校正状态变量:
53、查询测量系统参数u,确定卡尔曼增益矩阵:
54、xg=cgut(ucgut+e)-2;
55、e为卡尔曼增益矩阵系数;
56、通过g时刻的真实值与估计值之间的差值来校正g时刻的估计值:
57、k'g=k'g-xg(uk'g-kg-1);
58、kg-1是g-1时刻的话题热度真实值。
59、所述的对系统效果进行评价,包括:
60、(5.1)计算系统均方根误差:
61、
62、(5.2)计算系统平均绝对误差:
63、
64、(5.3)计算决定系数:
65、
66、是测试集话题热度真实值的均值;
67、rmse和mae的值小于阈值η和θ,e2的值大于阈值ε,表明系统合格;rmse和mae的值越小,e2的值越大,表明性能越优。
68、本发明的有益效果在于:本发明提供了一种面对海量话题的网络平台文本流话题热度预测方法。为了提高模型的预测精度和迭代求解的收敛速度,在处理复杂、不确定和随机的网络热点话题时,我们采取了一系列方法。首先,我们对数据进行了归一化处理,以避免较大数值的变化覆盖较小数值的变化,从而改善了模型的性能。其次,我们引入了bigru神经网络来解决超参数对模型预测精度的影响问题。这种网络结构可以挖掘话题热度时间序列的全局特征信息,并通过注意力机制自适应地提取特征信息,从而提高了时间序列特征的表达能力。为了进一步优化预测结果,我们使用卡尔曼滤波对注意力机制层的输出进行动态调整。这种方法可以有效抑制噪声,并提高最终的话题热度预测的准确性。最后在rmse、mae和e2三个指标上表现出更加理想的预测精度,在绝对误差上表现出更好的鲁棒性,能够更好地模拟话题热度的变化趋势。综上所述,通过归一化处理、采用bigru神经网络、引入注意力机制和卡尔曼滤波等方法,我们成功地提升了对网络热点话题的预测能力,能够更准确地模拟话题热度的变化趋势。
- 还没有人留言评论。精彩留言会获得点赞!