一种基于细化边缘语义的人脸复原方法
本发明属于人脸图像复原领域,特别是基于细化边缘语义的盲人脸复原方法。
背景技术:
1、现实世界中的低质量人脸图像通常遭遇了复杂退化而导致了糟糕的视觉体验。然而退化类型和退化参数的不可知性赋予了图像复原更多的挑战性。近年来,生成对抗网络(gan)逐步成为一种主流复原的模型架构,生成器和判别器的相互博弈使得生成器学习到高清人脸图像的数据分布进而能够生成以假乱真的人脸图像。
2、当前已有大量研究利用生成对抗网络(gan)进行人脸图像生成方法探索,目前大多有效的方法需要借助于先验信息。常见的先验类型有如几何先验、参考先验(dfdnet、dmdnet)、生成先验(gpen、gfpgan)、3d先验(sgpn)等。然而几何先验的关键点或组件位置难以准确标定,参考先验往往需要人脸检测网络标定组件位置导致了无法应用于退化严重的场景,带来额外的计算同时也拉低了推理速度(甚至超出了复原网络的推理时间)。生成先验虽然封装好了生成人脸的能力,一方面由于过度的依赖先验而限制了模型的灵活性,并且复原效果很大程度上取决于先验模型的性能,此外还可能引入先验网络的缺陷,如styleganv1的水滴。尽管方法(mfpsnet)尝试通过融合多种先验来弥补单一先验的缺陷,不可否认这提升了一定的性能,但也牺牲了一部分实时性能,因为要在恢复前耗费时间获取多种先验信息,导致模型与应用落地的目标越来越远。因此如何在不依赖先验信息的情况实现盲人脸复原是一个值得深思的问题。
3、此外,目前的生成人脸图像结果也是缺乏细节的,表现在生成的结果往往会过度平滑,并且即便是通过随机噪声去生成面部的细节信息,但是也不能保证生成与该身份的人脸图像一致的面部细节,如黑痣、伤疤等,在某些场景下这是不能接受的,如安防、媒体超高清等领域。
4、因此,需要一种基于细化边缘语义的人脸复原方法,通过引入特定的纹理编码,生成指定的细节信息,保证生成人脸和人脸身份的一致性;其次通过细化边缘语义机制来明确人脸组件与组件间、人脸和背景的边缘来近似先验,摒弃获取先验的时间进而提高人脸复原的速度;在结构上以编码-解码架构,将退化图像编码到潜在空间,减少参与到解码过程中的退化信息,类似ghostnet的分支结构有利于减少网络参数、提高检测速度,为超高清人脸场景(4k、8k)提供了一种思路。
5、专利cn114841891a通过训练三个低质量部位编码器将低质量的五官部分映射到高质量特征z空间,进而生成人脸的各个部位图像以完成复原任务。但是该方法存在以下缺陷:
6、(1)该方法需要预训练部位编码器,导致整个复原过程不是端到端的,复原的结果取决于三个编码器、部位映射模块和部位先验模块是否配合良好,加大了训练成本和难度。
7、(2)该方法关注于同一高质量图像在不同的退化程度的人脸显著性部位,忽略了非显著性的区域,因此可能存在图像非显著区域的复原效果欠佳的情况。
8、(3)该方法重建损失依旧使用了欧式距离的组合,会带来复原人脸的过分平滑,缺乏纹理性。
9、相比之下,本方法只训练一个复原网络,可实现端到端的人脸复原,训练成本相对较小;此外本方法不依赖任何先验,不存在显著/非显著区域,人脸图像的复原程度一致性会更高,且具有更好的速度;在纹理方面,本方法解码过程中到动态地引入同一身份的人脸的纹理,平滑性会得到极大改善。
10、此外专利cn114841891a属于先验复原方法,旨在关注人脸的显著性区域,如眼睛、鼻子、嘴巴,实现任意低质量图像的高质量复原。而本方法属于无先验的复原方法,旨在不依赖先验的前提下,实现对同一身份的低质量人脸图像的可靠复原。本方法得益于下列设计:
11、(1)通过固定卷积核来实现边缘语义的细化,以达到类似分割五官和背景的效果,此外固定的卷积核无需反向传播更新其中的参数,训练更加高效。
12、(2)通过构建身份-纹理数据库,如黑痣、伤疤等,复原过程中引入纹理信息可实现同一身份人脸图像的细节信息生成,避免生成结果的平滑。
13、(3)特征选择和特征补充模块结构上类似ghostnet,对不同方向的特征偏移特征进行加权以提高特征的表达能力,有利于减少网络参数,以便用于超高清场景和快速推理、部署。
技术实现思路
1、本发明旨在解决以上现有技术的问题。提出了一种基于细化边缘语义的人脸复原方法。本发明的技术方案如下:
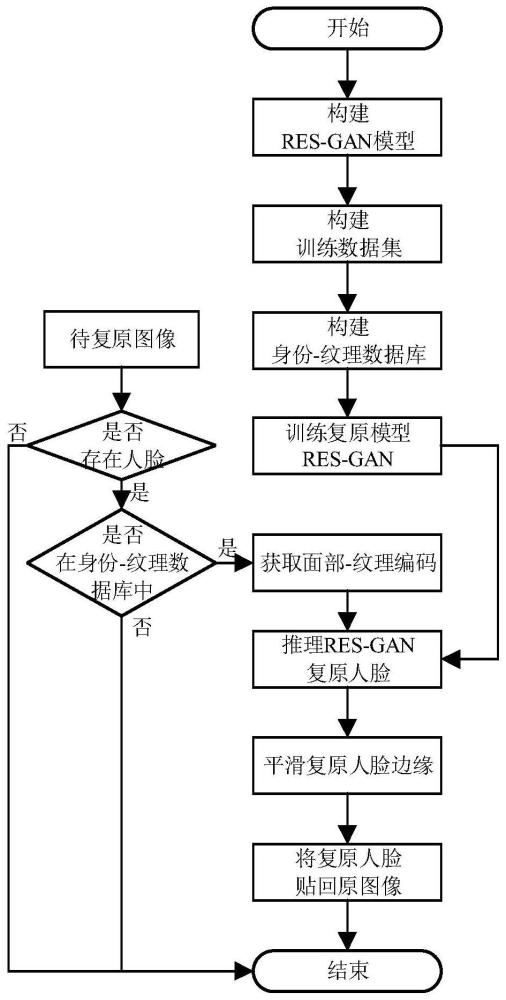
2、一种基于细化边缘语义的人脸复原方法,其特征在于,包括以下步骤:
3、步骤1:构建身份-纹理数据库;
4、步骤2:使用编码-解码架构来构建复原模型res-gan;并使用步骤1中的训练集训练res-gan用于复原退化的图像;
5、步骤3:以检测网络retinaface获取待检测图像中人脸的大致位置,再对其进行人脸关键点的检测,将人脸对齐到模板样式作为res-gan的输入,并在身份-纹理数据库中检索,寻找需要复原的身份纹理信息;
6、步骤4:将步骤3中的对齐后的人脸和身份纹理信息传入步骤3中训练好的res-gan,复原具有特定细节信息的人脸图像(restored-face)。
7、步骤5:根据步骤4中的restored-face的边缘进行掩码操作后进行仿射变换将其贴回检测图像,以避免边缘的不自然的过渡,实现场景中人脸的复原;
8、进一步的,所述步骤1:构建身份-纹理数据库,具体包括:
9、通过对高清人脸图像数据集ffhq、celeba进行纹理标注并收集关键点坐标作为模板,然后进行人为退化以模拟真实世界的退化人脸图像,作为复原网络的训练集并进行数据增强,同时将构建的数据集命名为低质量人脸数据集,并划分训练集和测试集的比例为8:2;并对特定身份的人脸图像进行纹理标注,并将人脸图像身份、纹理标签加密后存入数据库,就得到身份-纹理数据库。
10、进一步的,所述数据增强的步骤具体包括:对图像进行下采样、加高斯噪声、jpeg压缩在内的退化操作,操作如下:
11、
12、其中gray(x,p)表示在概率p下将高清人脸图像x进行灰度化,表示图像gray(x,p)与模糊核kσ进行卷积,↓r表示尺度因子为r的下采样操作,n表示高斯白噪声;[·]jpegq表示质量因子为q的jpeg压缩操作;概率p为0.3,此外分别从{3:9}、{1:16}、{3:15}、{10:65}中随机取样σ、r、δ和q;
13、随后进行数据增强操作并同步操作标签的位置,保证数据集和标签的一致性构建低质量人脸-纹理数据集,并随机划分训练集和测试集的比例为8:2;此外对特定的人脸图像按照上述标注方式进行标注,并将对应的人脸身份和纹理标签加密后存入数据库,构建身份-纹理数据库。
14、进一步的,所述步骤2:使用编码-解码架构来构建复原模型res-gan,具体包括:(1)编码阶段使用多个编码块,将退化的图像编码到潜在空间;(2)使用边缘语义细化机制来近似先验信息,利用对称偏移提高特征的有效偏移率,进行强化不同色彩的边缘;(3)采取类似ghostnet的并行架构设计特征选择块,一方面使用边缘语义细化机制生成近似先验,此外使用卷积和自适应池化生成选择权重对近似先验进行进一步选择;(4)采取通道拆分设计细节补充模块,将纹理标签编码为one-hot编码,将特征经过全局平均池化后归一化得到对应的权重,one-hot编码与之进行特征融合后补充到拆分剩余的通道中。
15、进一步的,所述步骤2编码-解码架构具体包括:编码块由两个卷积+下采样操作,逐步减少特征尺寸同时增加特征通道,将退化的图像编码到潜在空间,并保存不同的尺度的特征作为解码阶段的跳跃连接;在解码块,使用风格调制(stylegan中依赖于adain的调制操作)和上采样对潜在向量逐步进行尺寸的提升,其中对跳跃连接使用自定义的卷积核(卷积核有且仅有一个非中心位置的元素设置为1,其余为0,且不参与参数更新)来偏移特征,强化边缘细节来近似先验;此外使用类似ghostnet的并行结构,一个支路进行边缘细化,另外一个支路通过卷积调整通道和自适应池化来调整特征尺度以生成和细化边缘特征数目通道的一维向量,对细化边缘的特征进行选择和增强,并且使用残差来保证梯度回传;此外将细节补充块顺序的连接两级解码块之间,采取通道拆分为两部分,一部分经过全局平均池化、逐点卷积和sigmoid将特征进行归一化处理,随后与one-hot标签进行点乘,显式的引入纹理信息,通过大卷积核进行特征融合后与另一支路进行通道堆叠;res-gan网络由生成器和判别器构成,生成器以重建损失、对抗损失、感知损失、纹理损失的和为优化目标,判别器以对抗损失为优化目标,交替训练生成器和判别器,保存测试集中fid最低的生成器和判别器的权重,使用适应性矩估计adam优化算法来更新生成器和判别器的权重。
16、进一步的,所述生成器以重建损失、对抗损失、感知损失、纹理损失的和为优化目标,判别器以对抗损失为优化目标,交替训练生成器和判别器,具体包括:
17、重建损失:使用传统的l1损失约束生成的结果在像素层面趋近于真实图像。
18、
19、其中ih、分别代表真实人脸图像和生成人脸图像;
20、感知损失:感知损失的定义如下式子:
21、
22、其中φ(·)表示vgg16网络,使用了conv4_3层的特征;
23、对抗损失:使用对抗损失来鼓励模型倾向于生成符合真实的人脸图像的数据分布,采用logistic loss;
24、
25、
26、其中ih、分别代表真实人脸图像和生成人脸图像,d表示为判别器,为真实数据分布,为生成数据分布,分别表示对于满足生成数据分布和真实数据分布的样本的损失计算;
27、纹理损失:通过计算纹理one-hot编码m的克拉姆矩阵损失以提高生成特定纹理的真实性;
28、
29、
30、其中φ(·)表示vgg16网络,分别表示生成人脸图像和高清图像,⊙是元素的乘积,ε=1×10-8用于避免除零。
31、进一步的,所述步骤3具体为:
32、使用单阶段的检测网络retinaface来检测实际场景图像的人脸图像并粗略标记五官,将其中人脸截取出来作为人脸区域,记作face-area;然后使用dlib(机器学习算法的开源工具包)进行精细的人脸关键点标注,结合模板的关键点的坐标和图像尺寸进行仿射变化,将人脸区域中人脸进行对齐得到对齐人脸;此外将人脸身份在身份-纹理数据库中检索对应的面部纹理标签,随后将其编码为one-hot编码加入解码阶段,进而复原人脸的细节信息。
33、进一步的,所述步骤6具体为:
34、将复原的人脸图像仿射变换回场景图大小作为背景图,对背景图中的人脸区域置0生成掩码,并使用大小为5的模糊核对掩码进行模糊;然后进行平滑边缘。
35、本发明的优点及有益效果如下:
36、现有人脸复原方法大多依赖于先验信息,诸如几何先验、生成先验、人脸部位先验,先验的获取通常需要训练额外的先验网络,导致了较慢的推理速度和较大的网络参数,更加不利于超高清的场景,因为超高清输入需要更多的计算资源。此外现有人脸复原方法大多依赖以曼哈顿距离或者欧式距离来约束修复图像趋近于真实图像,而往往带来过分平滑的效果并丢失人脸身份的纹理。
37、本发明的创新主要是权利要求中步骤1-3的组合:本方法以对称偏移实现边缘细化,进而取代常规的先验信息,巧妙地避免了对先验网络的训练和额外获取先验的时间,另外一亮点在于对称偏移操作通过简单的卷积实现且无需反向传播更新卷积核参数,有效提高网络训练的效率。
38、进一步的,为加快推理速度和利用边缘细化特征,以类似ghostnet的并行框架设计特征选择模块,对不同方向的特征偏移特征进行加权以提高特征的表达能力。
39、进一步的,为避免过分平滑的效果,针对同一身份的人脸图像进行特定的面部纹理生成,细节补充模块将身份-纹理数据库中同一人的纹理信息动态的融入解码过程,以实现复原人脸身份的强一致性和细腻的纹理生成。
40、最终在边缘语义细化机制、特征选择块和细节补充模块的作用下,训练得到具有轻量并具有较好性能的可靠人脸复原模型,能够直接对输入的视频/图像中的人脸进行快速修复,同时具有较快的推理速度,大大降低算法所需要的资源和部署到硬件的难度,为超高清人脸场景(4k、8k)提供了一种思路。
- 还没有人留言评论。精彩留言会获得点赞!