灌装领域标签文字检测方法、装置、设备及可读存储介质与流程
本发明涉及灌装,特别是涉及一种灌装领域标签文字检测方法、装置、设备及可读存储介质。
背景技术:
1、随着数字化技术的广泛应用,人们的生活方式和工业生产方式已经发生了改变,特别是在工业生产中,数字化技术的应用大大提高了生产的效率和质量,减少了人力成本和机器故障率。工业标签是灌装领域广泛应用的一种数据标识手段,包含很多重要信息,如序列号、批次、重量、生产日期/保质期以及生产标准等,通过提取工业标签上的关键信息,可以方便地对灌装容器近行分拣、灌装、运输和储存。
2、灌装领域的工业标签上的文字密集、背景复杂,并且灌装领域获取的工业标签图像的视觉对比度一般比较低、照明不均匀、背景杂乱,还可能发生形变,这些都导致灌装领域工业标签的文字检测具有一定的挑战性。现有大多数基于深度学习的文字检测算法在灌装场景中的应用存在以下问题:1、由于文字密集,过小文字会出现漏检,影响后续文字识别的效果;2、由于背景复杂,产生大量与检测内容无关的候选框,增加计算时间;均无法准确定位文本区域。
技术实现思路
1、本发明的目的是提出一种灌装领域标签文字检测方法、装置、设备及可读存储介质,解决灌装领域标签文字检测困难的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、一方面,本技术提供一种灌装领域标签文字检测方法,包括以下步骤:
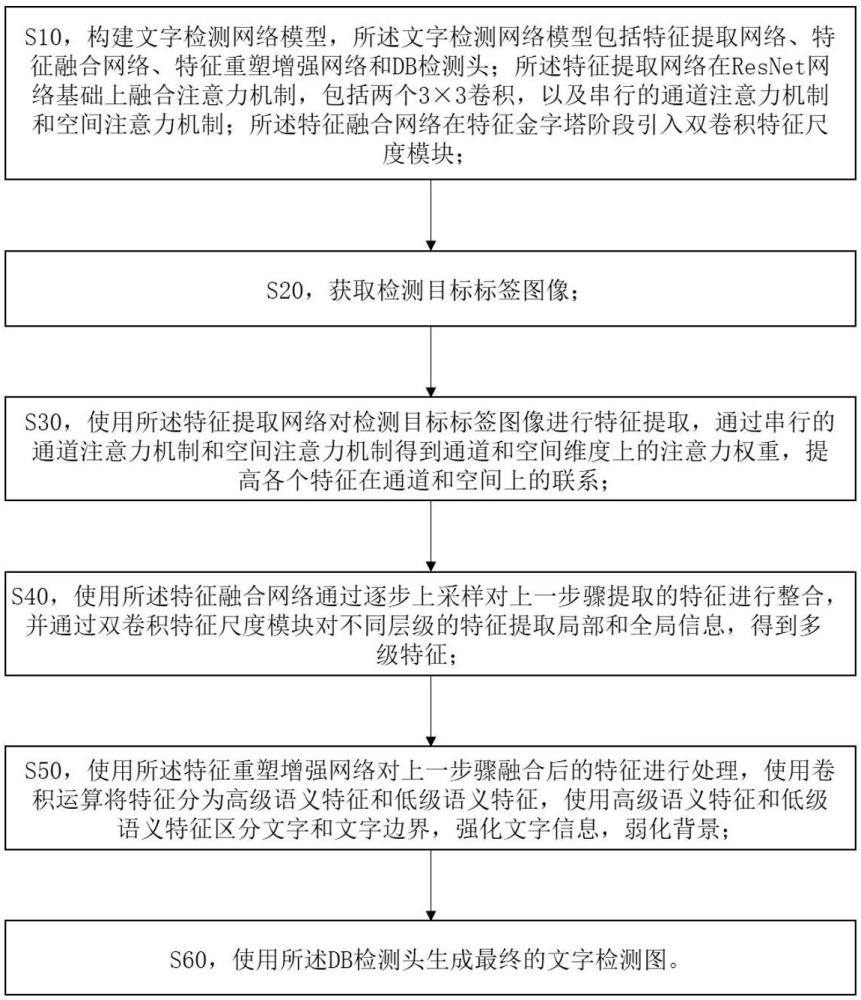
4、s10,构建文字检测网络模型,所述文字检测网络模型包括特征提取网络、特征融合网络、特征重塑增强网络和db检测头;所述特征提取网络在resnet网络基础上融合注意力机制,包括两个3×3卷积,以及串行的通道注意力机制和空间注意力机制;所述特征融合网络在特征金字塔阶段引入双卷积特征尺度模块;
5、s20,获取检测目标标签图像;
6、s30,使用所述特征提取网络对检测目标标签图像进行特征提取,通过串行的通道注意力机制和空间注意力机制得到通道和空间维度上的注意力权重,提高各个特征在通道和空间上的联系;
7、s40,使用所述特征融合网络通过逐步上采样对上一步骤提取的特征进行整合,并通过双卷积特征尺度模块对不同层级的特征提取局部和全局信息,得到多级特征;
8、s50,使用所述特征重塑增强网络对上一步骤融合后的特征进行处理,使用卷积运算将特征分为高级语义特征和低级语义特征,使用高级语义特征和低级语义特征区分文字和文字边界,强化文字信息,弱化背景;
9、s60,使用所述db检测头生成最终的文字检测图。
10、进一步地,在所述步骤s30中,通道注意力机制首先对特征进行全局最大池化和全局平均池化并行处理,接着经过一个全连接层,将特征图进行降维,再使用relu函数进行激活,再经过一个全连接层,将特征图进行升维,然后加和,再通过sigmoid函数对加和后的特征图进行处理,得到归一化注意力权重,最后通过乘法逐通道加权到原始输入的特征图上,得到特征图fc;空间注意力机制将得到的特征图fc进行全局最大池化和全局平均池化并行处理,并将各自生成的特征连接,接着通过7×7卷积操作建立高维空间特征的相关性,再使用sigmoid函数进行处理,获得空间注意力权重,最后通过相乘加权到特征图fc上,得到特征图fs。
11、进一步地,在所述步骤s40中,所述特征融合网络采用双卷积特征尺度模块对上一步骤中提取的特征图分别使用两组1×1卷积将特征数减半,接着在第一组的1×1卷积后加入一组3×3卷积;第组的1×1卷积后加入两组3×3卷积,提取不同感受野的特征;再按通道进行拼接,得到特征图,再对特征图进行1×1卷积操作,得到特征图;再将特征图行全局平均池化,得到输出,最后将输出经过fex得到权重向量;再将权重向量与输入的特征图进行加和得到最终特征图;fex包括两个全连接层、一个relu激活函数和一个sigmoid函数,fex的计算过程为:,其中,表示计算生成的实数,和分别是全连接层中第一层和第二层的权重参数,,,r表示降维的超参数,用于调节隐层神经元个数。
12、进一步地,所述特征重塑增强网络对输入的特征图依次使用步长为2的1×1卷积和步长为2的3×3卷积进行降维处理,再进行上采样,得到低级语义特征图;然后将经过步长为2的1×1卷积和步长为2的3×3卷积生成的特征与经过一次步长为2的1×1卷积生成的特征进行拼接,生成特征图ftemp,再将特征图ftemp和低级语义特征图进行逐像素相乘,得到高级特征图。
13、进一步地,在所述步骤s10中还包括:
14、制作工业标签文字数据集,所述工业标签文字数据集的文本包括中文、英文、罗马字和艺术字,使用多边形裁剪算法vatti生成概率图的训练标签和阈值图的训练标签,在标签制作过程中,概率图和阈值图的训练标签分别是将文本的多边形标签经过一定偏移量d缩小和扩大产生,偏移量d的计算公式为:,其中,k是标注文本框的周长,a是标注文本框的面积,e是预设的缩放因子;
15、使用所述工业标签文字数据集训练所述文字检测网络模型;
16、定义损失函数,损失函数由概率图损失、阈值图损失和二值化图损失加权和得到,计算如公式为:,其中和的取值分别设置为1和10,概率图损失和阈值图损失采用二进制交叉熵损失,计算如公式为:其中,是采样集,正负样本的比例为1:3;为扩展多边形内侧预测值与标签值之间的距离之和,计算如公式为:,其中为扩展多边形内像素的一组索引,是阈值图的标签,是真实标签值。
17、进一步地,在使用所述工业标签文字数据集训练所述文字检测网络模型时,首先使用synthtext数据集对所述文字检测网络模型进行两个epoch的训练,得到预训练模型,然后在所述工业标签文字数据集上进行一千个epoch的训练。
18、另一方面,本技术还提供一种灌装领域标签文字检测装置,包括:
19、模型构建模块,用于构建文字检测网络模型,所述文字检测网络模型包括特征提取网络、特征融合网络、特征重塑增强网络和db检测头;所述特征提取网络在resnet网络基础上融合注意力机制,包括两个3×3卷积,以及串行的通道注意力机制和空间注意力机制;所述特征融合网络在特征金字塔阶段引入双卷积特征尺度模块;
20、图像获取模块,用于获取检测目标标签图像;
21、特征提取模块,用于通过所述特征提取网络对检测目标标签图像进行特征提取,通过串行的通道注意力机制和空间注意力机制得到通道和空间维度上的注意力权重,提高各个特征在通道和空间上的联系;
22、特征融合模块,用于通过所述特征融合网络对所述特征提取模块提取的特征进行整合,并通过双卷积特征尺度模块对不同层级的特征提取局部和全局信息,得到多级特征;
23、特征重塑增强模块,用于通过卷积运算将所述特征融合模块融合后的特征分为高级语义特征和低级语义特征,使用所述高级语义特征和低级语义特征区分文本边界,提高对文本边界区域的灵敏度;
24、目标检测模块,用于通过所述db检测头生成最终的文字检测图。
25、进一步地,所述的灌装领域标签文字检测装置,还包括模型训练模块,用于制作工业标签文字数据集,定义损失函数,并利用所述工业标签文字数据集训练所述文字检测网络模型,训练过程中,首先使用synthtext数据集对所述文字检测网络模型进行两个epoch的训练,得到预训练模型,然后在所述工业标签文字数据集上进行一千个epoch的训练;所述工业标签文字数据集的文本包括中文、英文、罗马字和艺术字,使用多边形裁剪算法vatti生成概率图的训练标签和阈值图的训练标签,在标签制作过程中,概率图和阈值图的训练标签分别是将文本的多边形标签经过一定偏移量d缩小和扩大产生,偏移量d的计算公式为:,其中,k是标注文本框的周长,a是标注文本框的面积,e是预设的缩放因子;损失函数由概率图损失、阈值图损失和二值化图损失加权和得到,计算如公式为:,其中和的取值分别设置为1和10,概率图损失和阈值图损失采用二进制交叉熵损失,计算如公式为:其中,是采样集,正负样本的比例为1:3;为扩展多边形内侧预测值与标签值之间的距离之和,计算如公式为:,其中为扩展多边形内像素的一组索引,是阈值图的标签,是真实标签值。
26、另一方面,本技术还提供一种灌装领域标签文字检测设备,包括处理器和存储器,所述处理器执行存储器中存储的计算机程序时实现上述的灌装领域标签文字检测方法。
27、另一方面,本技术还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的灌装领域标签文字检测方法。
28、与现有技术相比本发明的有益效果是:
29、本发明提供的灌装领域标签文字检测方法,基于dbnet网络模型构建一种低对比度工业标签文字检测网络模型,首先将卷积注意力机制应用于特征提取网络,获取更多重要的文本特征图;其次在特征融合金字塔结构中引入特征尺度分支,丰富上下文信息,使网络自适应地学习不同通道特征的重要性;最后在概率图生成阶段,提出特征重塑增强模块,进一步区分文字和文字边界,提高对文本边界区域的灵敏度,增强文字检测的准确率。在自制工业标签数据集上的准确率为94.7%,召回率为90.0%,f值为92.3%,在icdar2015和msra-td500两个标准数据集上,相较于dbnet网络模型,f值分别提升1.8%和1.5%。
- 还没有人留言评论。精彩留言会获得点赞!