基于数据库的数据处理方法、装置和电子设备与流程
本技术涉及数据处理,尤其涉及一种基于数据库的数据处理方法、装置和电子设备。
背景技术:
1、目前,在数据库中对数据压缩是使用较小的数据存储空间以节约存储成本,并减少磁盘io量,从而提升数据库的性能。现有的数据库压缩技术方案包括:(1)页面级压缩方案:在创建数据表的时候指定现有的压缩算法,以page为粒度进行压缩和解压,压缩率较高但会造成解压放大的问题,即只读一行数据,也要解压整个page,解压速度慢。(2)行级压缩方案:以page为单位创建字典,由该字典对page内的每一行数据采用相同的压缩算法进行压缩和解压,且字典存储于page内部。该技术方案是以行为压缩解压粒度,相比页面级压缩方案中,只读一行数据,也要解压整个page,行级压缩方案解压速度较快但压缩率低。即现有数据库压缩技术方案中,只能牺牲解压速度换取更高的压缩率,或者降低压缩率来提高解压速度,导致数据库的性能无法达到最优。为了使数据库的性能可以达到最优,应该使解压速度和压缩率达到平衡。因此,如何实现解压速度和压缩率的平衡,提高数据库的性能,成为了亟待解决的技术问题。
技术实现思路
1、本技术实施例的主要目的在于提出一种基于数据库的数据处理方法、装置和电子设备,旨在实现解压速度和压缩率的平衡,提高数据库的性能。
2、为实现上述目的,本技术实施例的第一方面提出了一种基于数据库的数据处理方法,所述方法包括:
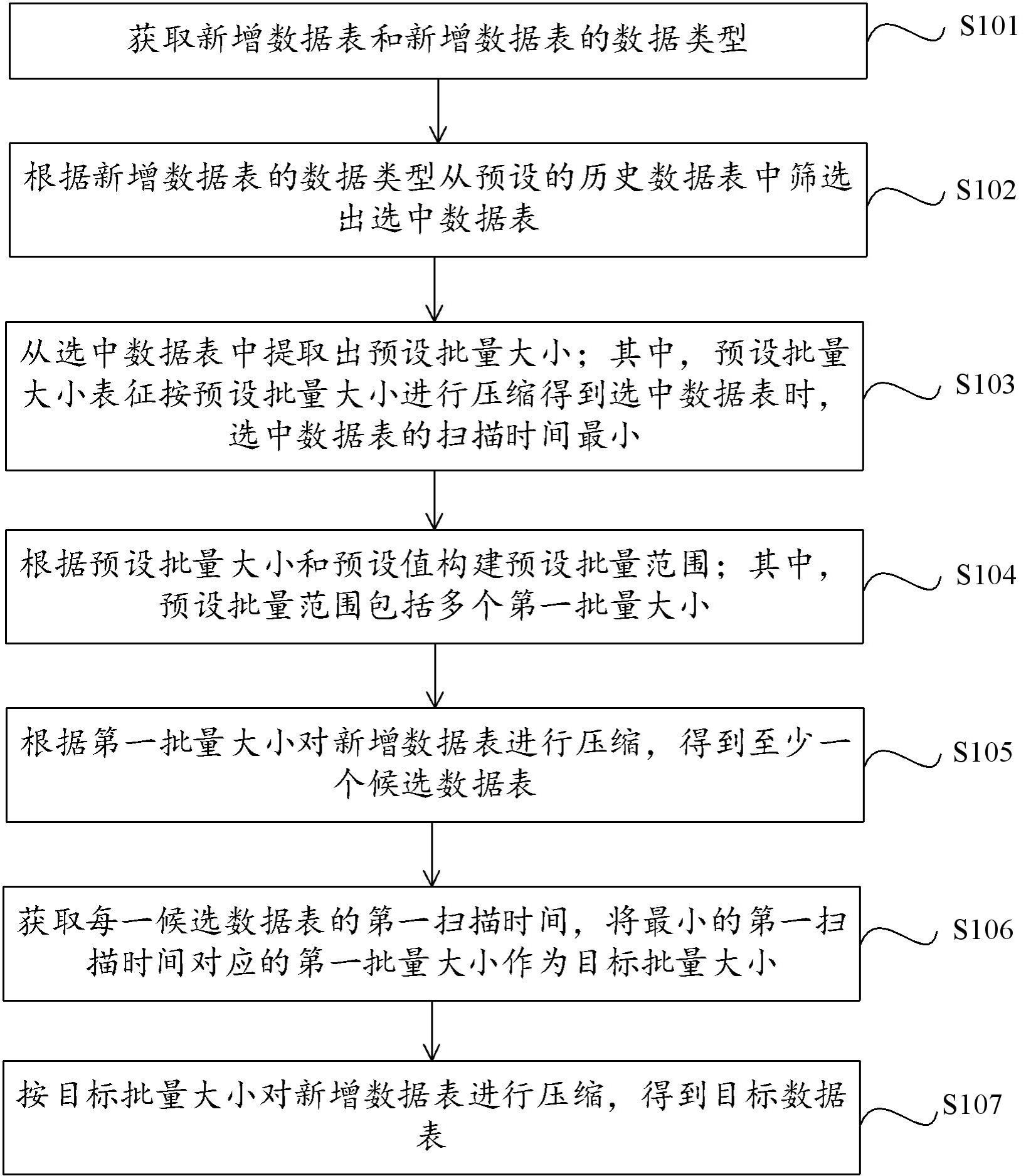
3、获取新增数据表和所述新增数据表的数据类型;
4、根据所述新增数据表的数据类型从预设的历史数据表中筛选出选中数据表;
5、从所述选中数据表中提取出预设批量大小;其中,所述预设批量大小表征按所述预设批量大小进行压缩得到所述选中数据表时,所述选中数据表的扫描时间最小;
6、根据所述预设批量大小和预设值构建预设批量范围;其中,所述预设批量范围包括多个第一批量大小;
7、根据所述第一批量大小对所述新增数据表进行压缩,得到至少一个候选数据表;
8、获取每一所述候选数据表的第一扫描时间,将最小的所述第一扫描时间对应的第一批量大小作为目标批量大小;根据所述目标批量大小对所述新增数据表进行压缩,得到目标数据表。
9、在一些实施例,所述获取新增数据表和所述新增数据表的数据类型之前,所述方法还包括:
10、获取初步数据表;其中,所述初步数据表包括至少一张数据页;
11、获取多个第二批量大小;其中,所述多个第二批量大小分别为1至n,所述n表示为所述数据页包含的行数据数量;
12、根据所述第二批量大小对所述初步数据表进行压缩,得到至少一个压缩数据表;
13、获取每一所述压缩数据表的第二扫描时间,将最小的所述第二扫描时间对应的第二批量大小作为预设批量大小;
14、根据所述预设批量大小对所述初步数据表进行数据压缩,得到历史数据表;
15、将所述历史数据表和所述预设批量大小一起保存。
16、在一些实施例,所述获取初步数据表之前,所述方法还包括:
17、获取原始数据表;
18、对所述原始数据表进行压缩,获得原始压缩数据表;
19、获取所述原始数据表的扫描时间和所述原始压缩数据表的扫描时间;
20、若所述原始数据表的扫描时间大于所述原始压缩数据表的扫描时间,则将所述原始数据表作为所述初步数据表。
21、在一些实施例,所述根据所述目标批量大小对所述新增数据表进行压缩,得到目标数据表,包括:
22、获取所述新增数据表内每一行数据,得到新增行数据;
23、根据预设的压缩格式和所述目标批量大小对每一所述新增行数据进行压缩,得到至少一个数据帧和/或匹配帧;其中,所述预设的压缩格式包括所述数据帧和所述匹配帧,所述数据帧包括:不重复数据长度、不重复数据和分隔符,所述分隔符用作区分不重复数据的末端位置;所述匹配帧包括重复数据当前位置到匹配位置的偏移量、重复引用匹配的总长度、重复数据的第一个匹配长度;
24、重复上述步骤,直至遍历完所述新增行数据,将至少一个所述数据帧和/或所述匹配帧进行组合,得到所述目标数据表。
25、在一些实施例,所述根据预设的压缩格式和所述目标批量大小对每一所述新增行数据进行压缩,得到至少一个数据帧和/或匹配帧,包括:
26、通过滑动窗口遍历每一所述新增行数据,并计算所述滑动窗口的哈希值;
27、若所述哈希值不存在于共享表中,则所述滑动窗口遍历的数据为不重复数据,将所述哈希值、不重复数据当前位置在压缩数据中的偏移量和指向未压缩数据当前位置的指针记录在共享表中;
28、根据不重复数据的长度和不重复数据将连续的不重复数据存储为数据帧;
29、若所述哈希值存在于共享表中,则所述滑动窗口遍历的数据为重复数据,根据共享表中对应的所述指向未压缩数据当前位置的指针,获得所述重复数据的重复引用匹配的总长度,根据所述不重复数据当前位置在压缩数据中的偏移量和所述重复数据当前位置在压缩数据中的偏移量,获得所述重复数据当前位置到匹配位置的偏移量,根据所述重复数据当前位置到匹配位置的偏移量,获得所述重复数据的第一个匹配长度;
30、根据所述重复数据当前位置到匹配位置的偏移量、所述重复引用匹配的总长度和所述重复数据的第一个匹配长度将所述重复数据存储为匹配帧。
31、在一些实施例,所述将至少一个所述数据帧和/或所述匹配帧进行组合,得到所述目标数据表之后,所述方法还包括:
32、获取查询计划;
33、对所述查询计划进行解析,得到解压数据选择信息;
34、根据所述解压数据选择信息对所述目标数据表进行行数据选择,得到目标压缩数据;其中,所述目标压缩数据包括至少一个数据帧和/或匹配帧;
35、依次遍历所述目标压缩数据中的数据帧和匹配帧;
36、复制所述数据帧中的不重复数据,根据所述匹配帧获取所述重复数据的位置和长度,根据所述重复数据的位置和长度从所述数据帧中复制出重复数据;
37、将所有所述不重复数据和所有所述重复数据依次进行组合,得到解压数据。
38、在一些实施例,所述获取原始数据表的扫描时间,包括;
39、获取所述原始数据表的物理空间和数据库的页面逐出开销;
40、根据所述物理空间、预设内存预算、预设磁盘i/o带宽和所述页面逐出开销进行扫描时间预测,得到所述原始数据表的扫描时间。
41、在一些实施例,所述获取原始压缩数据表的扫描时间,包括:
42、获取所述原始数据表的物理空间和数据库的页面逐出开销;
43、获取缓冲池中内存对齐所消耗的比例、第二批量大小下的压缩率和第二批量大小下的解压速度;其中,所述原始数据表存储在所述缓冲池中;
44、根据所述物理空间、预设内存预算、预设磁盘i/o带宽、所述页面逐出开销、所述缓冲池中内存对齐所消耗的比例、所述第二批量大小下的压缩率和所述第二批量大小下的解压速度进行扫描时间预测,得到所述原始压缩数据表的扫描时间。
45、为实现上述目的,本技术实施例的第二方面提出了基于数据库的数据处理装置,所述装置包括:
46、第一获取模块,用于获取新增数据表和所述新增数据表的数据类型;
47、筛选模块,用于根据所述新增数据表的数据类型从预设的历史数据表中筛选出选中数据表;
48、提取模块,用于从所述选中数据表中提取出预设批量大小;其中,所述预设批量大小表征按所述预设批量大小进行压缩得到所述选中数据表时,所述选中数据表的扫描时间最小;
49、构建模块,用于根据所述预设批量大小和预设值构建预设批量范围;其中,所述预设批量范围包括多个第一批量大小;
50、第一压缩模块,用于根据所述第一批量大小对所述新增数据表进行压缩,得到至少一个候选数据表;
51、第二获取模块,用于获取每一所述候选数据表的第一扫描时间,将最小的所述第一扫描时间对应的第一批量大小作为目标批量大小;
52、第二压缩模块,用于根据所述目标批量大小对所述新增数据表进行压缩,得到目标数据表。
53、为实现上述目的,本技术实施例的第三方面提出了一种电子设备,所述电子设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面所述的方法。
54、本技术提出的基于数据库的数据处理方法、装置和电子设备,其通过根据新增数据表的数据类型从预设的历史数据表中筛选出选中数据表,并从选中数据表中提取出预设批量大小,其中,按预设批量大小进行压缩得到选中数据表时,选中数据表的扫描时间最小。根据预设批量大小和预设值构建预设批量范围后,其中,预设批量范围包括多个第一批量大小,根据第一批量大小对新增数据表进行压缩,得到至少一个候选数据表。获取每一候选数据表的第一扫描时间,将最小的第一扫描时间对应的第一批量大小作为目标批量大小;按目标批量大小对新增数据表进行压缩,得到目标数据表。按目标批量大小对新增数据表进行压缩时,得到的目标数据表扫描时间最小,因此实现了解压速度和压缩率之间的平衡,且从预设批量范围选出目标批量大小,能够减少计算过程,快速地选出目标批量大小,提高了数据库的性能。
- 还没有人留言评论。精彩留言会获得点赞!