基于STL-SVR-AdaBoost模型的短期负荷预测方法及系统
本发明涉及负荷预测,具体为基于stl-svr-adaboost模型的短期负荷预测方法及系统。
背景技术:
1、电力需求预测是电力系统规划的重要组成部分,也是电力系统经济运行的基础,是以电力负荷为对象进行的一系列预测工作,通过对电力负荷的时间分布和空间分布进行预测,为电力系统规划和运行提供可靠的决策依据,负荷预测的精度越高,越有利于提高发电设备的利用率和经济调度的有效性,促进电力系统安全稳定运行。反之,如果预测误差较大时,会造成大量的运行成本和电量损失,增大了经济压力,严重时还会影响电力系统的安全稳定运行和电力市场的供需平衡。因此,对电力负荷进行准确的预测是非常有必要的。目前有研究提出了svr预测算法对负荷进行预测,但是该算法在样本噪声较大的情况下预测性能会有所下降,不能满足预测精度的要求,并且原始数据未经过处理,也会对预测精度有所影响,影响电力系统的安全经济运行。
技术实现思路
1、鉴于上述存在的问题,提出了本发明。
2、因此,本发明解决的技术问题是:现有技术在样本噪声较大的情况下预测准确度不高,不能满足预测精度的要求。
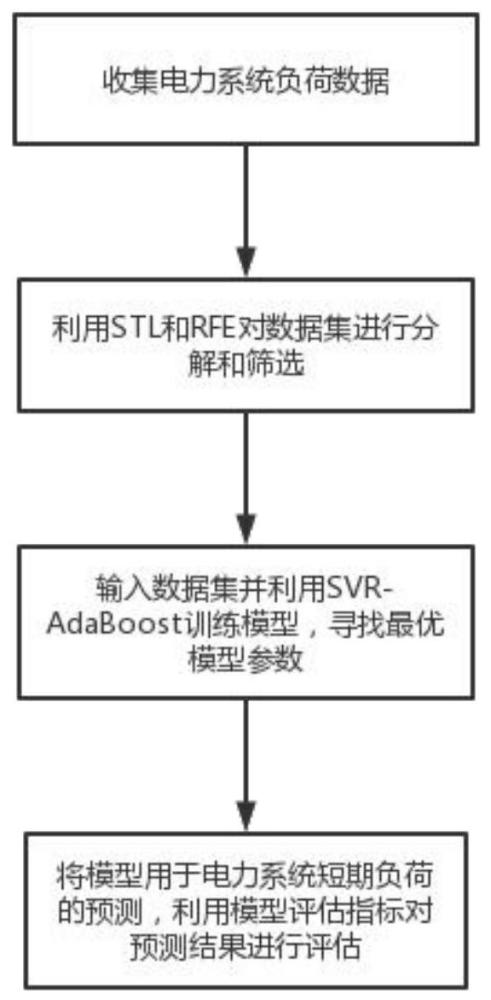
3、为解决上述技术问题,本发明提供如下技术方案:一种基于stl-svr-adaboost模型的短期负荷预测方法,包括:
4、收集电力系统负荷数据;利用stl和rfe对数据集进行分解和筛选;输入数据集并利用svr-adaboost训练模型,寻找最优模型参数;将模型用于电力系统短期负荷的预测,利用模型评估指标对预测模型进行评估。
5、作为本发明所述的基于stl-svr-adaboost模型的短期负荷预测方法的一种优选方案,其中:数据预处理包括,
6、对历史数据进行预处理,并利用adf检验划分平稳数据集和非平稳数据集;
7、预处理主要包括对数据含有的异常值和空缺值进行修正和填充,并对数据进行归一化处理,处理完后的数据集表示为x’;
8、利用adf检验方法,对样本数据集进行平稳性分析:
9、
10、p=1-f
11、其中,adf表示adf统计量,是检验的关键统计量;μ表示回归模型中的估计系数;se(μ)表示估计系数的标准误差;p表示伴随概率,当原假设为真时检验统计量取该观察值或更极端值的概率;f表示adf统计量的累积分布函数;
12、计算输入数据集x’对应的adf统计量及p值,设置显著水平值α,查找对应的临界值,若adf统计量小于临界值,表示时间序列数据不具有单位根,拒绝数据是不平稳数据的零假设;同时,若p值小于所选的显著性水平,表示拒绝零假设,数据为平稳数据。
13、将数据集分为平稳数据特征集x1,以及不平稳数据特征集x2。
14、作为本发明所述的基于stl-svr-adaboost模型的短期负荷预测方法的一种优选方案,其中:所述不平稳数据集的处理包括,利用stl将不平稳数据特征集x2分解为趋势和季节性两个分量,为筛选数据提供支撑,作为扩充的特征数据集;
15、分解式表示为,
16、x2(t)=h(t)+k(t)
17、趋势分量的计算公式表示为,
18、
19、季节性分量的计算公式表示为:
20、
21、其中,h(t)表示t时刻的趋势值,k(t)表示t时刻季节项值;x2(j)表示数据集合中第j个时间点的观测值;表示数据集合中所有观测值的平均值;表示数据集合中所有时间点的平均值;v表示季节性的周期长度。x2(t)表示在时间t处的观测值。
22、作为本发明所述的基于stl-svr-adaboost模型的短期负荷预测方法的一种优选方案,其中:所述求最佳数据特征组合包括,将筛选的k个特征作为初始特征子集输入到随机森林分类器中,计算得到每个特征的重要性,并利用交叉验证方法得到初始特征子集的分类精度;
23、从当前特征子集中移除特征重要性最低的一个特征,得到一个新的特征子集,再次输入到随机森林分类器中,计算新的特征子集中每个特征的重要性,并利用交叉验证方法得到新的特征子集的分类精度;
24、递归的重复移除特征重要性最低的一个特征,得到一个新的特征子集,直至特征子集为空,最后一共得到k个不同特征数量的特征子集,选择分类清度最高的特征子集作为最优特征组合。
25、作为本发明所述的基于stl-svr-adaboost模型的短期负荷预测方法的一种优选方案,其中:所述svr-adaboost预测模型包括,设置基学习器和强学习器的初始参数,步骤如下:
26、将最佳特征组合数据集作为svr-adaboost算法模型的输入,并划分样本集为测试集和训练集其中xi∈rn表示输入数据集,yi∈rn表示输入数据对应的输出样本;
27、将训练集数据进行建模作为弱学习器,设置迭代次数q来决定弱学习器的个数,给出误差限值阈值;
28、初始化样本权重,对训练集数据分配相同的权值,表示第m个数据作为第q个模型样本的概率,表示为:
29、
30、进行训练集的循环迭代;根据svr算法计算预测的回归函数,在高维特征空间中构造最优线性函数,表示为:
31、f(x)=dtφ(x)+b
32、其中,d表示权重,b表示偏置项;
33、引入不敏感损失函数ε,使预测输出值与样本集中实际值的误差不超法ε,则认为模型是无损的,表示为:
34、
35、若预测结果与原始实际数据不等,则不敏感函数表示为:
36、|y-f(x)|ε=max{0,|y-f(x)|-ε}
37、简化模型求解,使||d||2的值最小;定义两个松弛变量ζm和计算超出ε不敏感带外的样本的误差,表示为;
38、
39、约束条件表示为:
40、
41、其中,g为惩罚因子,通过调节g的大小表示对误差的惩罚大小;
42、作为本发明所述的基于stl-svr-adaboost模型的短期负荷预测方法的一种优选方案,其中:所述最终求解模型包括,
43、将问题转化成对偶问题,通过lagrange函数求解,得到回归函数,其中为径向基核函数,回归函数表示为:
44、
45、k(x,xm)=exp(-||x-xm||/σ2)
46、得到svr模型受惩罚因子g和核函数参数σ影响;衡量模型精确度,计算相对预测误差,表示为:
47、
48、其中,fq(xm)表示第q个模型样本的预测输出值;计算第q次迭代回归预测模型的误差率,表示为:
49、
50、其中,δ表示设定的误差限值阈值(0<δ<1),目的是将训练效果差的样本剔除出来;
51、计算回归模型的误差率eq,如果eq≥0.5,则直接进行模型预测,否则根据本次预测模型的误差率计算该弱学习器的权值,表示为:
52、
53、更新训练集样本的权值分布,表示为:
54、
55、其中z为归一化因子;
56、当循环迭代次数小于q时,循环回到根据svr算法计算预测的回归函数,继续相同操作,直至循环迭代次数达到q,结束循环;
57、得到最终预测模型;
58、得到强学习器和弱学习器,将弱学习器的权重进行归一化处理,表示为:
59、
60、得到最终预测模型,表示为:
61、
62、作为本发明所述的基于stl-svr-adaboost模型的短期负荷预测方法的一种优选方案,其中:所述评估算法的准确度包括,利用均方根误差rmse、平均绝对百分比误差mape、平均绝对误差mae这三个指标来衡量预测算法的准确率,计算公式表示为:
63、
64、
65、
66、其中:lpre为预测值,xrea为真实值,a为预测点数量。
67、一种基于stl-svr-adaboost模型的短期负荷预测系统,其特征在于:
68、数据收集模块,选取某地区的电网的历史负荷数据,对数据进行归一化处理;利用adf检验将数据集分为平稳数据和非平稳数据。
69、模型预测模块,得到处理后的数据集,利用特征递归消除,对扩充后的特征数据集进行筛选形成最佳特征组合,选取训练样本集作为弱学习器,初始化设定,开始预测算法循环流程,更新迭代,得到强学习器;
70、信息传递模块,传递收集到的数据、处理后的数据集、模型输出信息给所需的模块,接收输出信息;
71、综合处理模块,负责将传递模块传输的信息进行综合计算处理并输出,对得到的模型预测内容进行评估。
72、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现本发明中任一项所述的方法的步骤。
73、一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现本发明中任一项所述的方法的步骤。
74、本发明的有益效果:本发明提供的基于stl-svr-adaboost模型的短期负荷预测方法,能够利用stl分解和rfe分析出不稳定数据并进行筛选,改善预测输入数据的性能;而svr算法能够较好的处理小样本高维数据问题,改善噪声干扰对adaboost算法训练效果的影响,增强模型的抗干扰能力,提高预测精度。
- 还没有人留言评论。精彩留言会获得点赞!