一种基于深度学习的关键文档自适应识别方法及其系统与流程
本发明属于计算机与信息科学,具体涉及一种基于深度学习的关键文档自适应识别方法及其系统。
背景技术:
1、随着人们环保意识的增强,以及各行业对办公模式需求的不断升级,现代化、信息化建设步伐的加快,无纸化办公已经由概念逐渐应用到多个行业领域中。传统的纸质文档已逐步转变为电子文档。同时随着互联网的发展,电子文档的获取和传输变得轻而易举,互联网、社交软件、自媒体的出现给我们带来很多便利,但同时也带来各种各样的安全问题。近年来,行政机关及企业内部的文档泄露也变得越来越常见,给相关单位带来了极大的负面影响。
2、传统的关键文档可通过人工查看的方式进行识别,但是针对电子文档数据量巨大且存放位置不确定等因素,如果通过人工逐一搜索、查看会造成严重的人力资源浪费。
3、目前针对关键文档识别的方法,主要基于传统的图像处理技术,对于不同格式的文档无法准确的覆盖;传统的关键文档识别方法,主要针对关键文档中的部分特征进行识别,如公章和横线,在输入的图片不够清晰或存在污染的情况下,无法进行准确的识别;部分关键文档识别的方法,主要针对文档中的文本进行关键词匹配,在词库不够充足,或者未能覆盖到的特定领域的文本,例如收集了某个特定领域的关键词,而给出另一个领域的文档,无法进行准确的识别。
4、有鉴于此,提出一种基于深度学习的关键文档自适应识别方法及其系统是非常具有意义的。
技术实现思路
1、本发明提供一种基于深度学习的关键文档自适应识别方法及其系统,通过使用深度学习及文本处理技术,实现高效准确地从不同类型的文档中识别出电子公文、财务报表、销售合同等关键文档,以便于对文档加以控制和保护,防止文件泄露,以解决上述存在的技术缺陷问题。
2、第一方面,本发明提出了一种基于深度学习的关键文档自适应识别方法,该方法包括如下步骤:
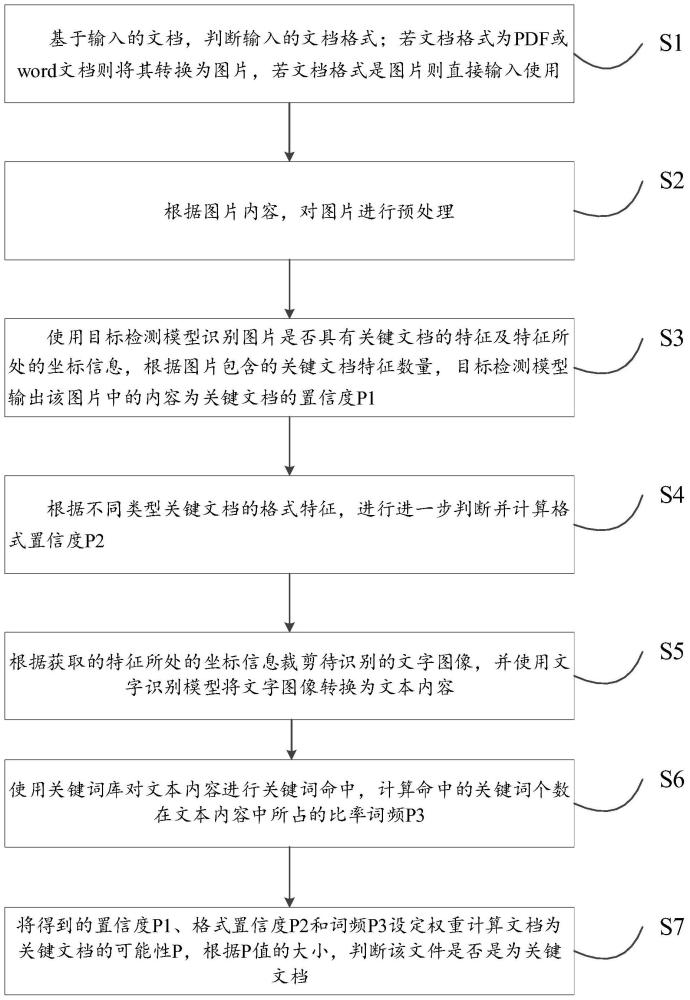
3、基于输入的文档,判断输入的文档格式;若文档格式为pdf或word文档则将其转换为图片,若文档格式是图片则直接输入使用;
4、根据图片内容,对图片进行预处理;
5、使用目标检测模型识别图片是否具有关键文档的特征及特征所处的坐标信息,根据图片包含的关键文档特征数量,目标检测模型输出该图片中的内容为关键文档的置信度p1;
6、根据不同类型关键文档的格式特征,进行进一步判断并计算格式置信度p2;
7、根据获取的特征所处的坐标信息裁剪待识别的文字图像,并使用文字识别模型将文字图像转换为文本内容;
8、使用关键词库对文本内容进行关键词命中,计算命中的关键词个数在文本内容中所占的比率词频p3;
9、将得到的置信度p1、格式置信度p2和词频p3设定权重计算文档为关键文档的可能性p,根据p值的大小,判断该文件是否是为关键文档。
10、优选的,将得到的置信度p1、格式置信度p2和词频p3设定权重计算文档为关键文档的可能性p,置信度p1由每项关键文档的特征置信度加权累加得出,格式置信度p2为每项关键文档特征格式的正确率加权累加得出,具体包括:
11、若为单张图片,可能性p=w1*p1+w2*p2+w3*p3;
12、若为一组图片,可能性p=∑(w1*pn1+w2*pn2+w3*pn3);
13、其中,w1、w2和w3为权重值,n为输入图片组张数,pn1为图片组第n张图片的置信度p1,pn2为图片组第n张图片的格式置信度p2,pn3为图片组第n张图片的词频p3。
14、优选的,根据图片内容,对图片进行预处理包括:使用目标检测模型判断图片中是否出现文档纸张区域,区分输入的图片是否为包含可能为关键文档的照片,具体包括:
15、若输入的图片为包含可能为关键文档的照片,则根据目标检测模型所输出的坐标信息,对图片进行裁剪及梯形矫正,转化为原始文档截图的形式;
16、若输入的图片为文档截图的形式,则跳过。
17、优选的,关键文档的特征包括:公章、标题下方红色横线、发文机关标志的格式、文件内容的间距、图片的整体特征、密级和保密期限、资产负债表、利润表、现金流量表、合同的甲乙方、合同条款、合同期限。
18、优选的,还包括:
19、初始化关键词库,所述关键词库由收集到的关键文档分析得出基础数据;
20、根据目标检测模型识别图片所输出的特征数据,提取关键文档的内容信息,并对所提取的文本信息进行分词解析,更新关键词库,用于提高识别准确率。
21、优选的,目标检测模型使用基于nanodet-plus模型训练,文字识别模型使用crnn。
22、优选的,还包括使用深度学习技术,训练一个线性回归模型:
23、收集一批文件,包含真实关键文档、含有正确格式的虚假内容关键文档、其他文件三类,并标注对应的类别;
24、根据计算得到置信度p1、格式置信度p2、词频p3;
25、基于线性回归模型,将置信度p1、格式置信度p2和词频p3作为输入,基于可能性p的计算方式计算p,并与文件对应标注的类别做比较,根据差距调整权重值w1、w2及w3;
26、通过训练得出一个符合预期的模型,用于可能性p的计算。
27、第二方面,本发明实施例还提供基于深度学习的关键文档自适应识别系统,包括:
28、转换模块,配置用于基于输入的文档,判断输入的文档格式,若文档格式为pdf或word文档则将其转换为图片,若文档格式是图片则直接输入使用;
29、预处理模块,配置用于根据图片内容,对图片进行预处理;
30、置信度p1计算模块,配置用于使用目标检测模型识别图片是否具有关键文档的特征及特征所处的坐标信息,根据图片包含的关键文档特征数量,目标检测模型输出该图片中的内容为关键文档的置信度p1;
31、格式置信度p2计算模块,配置用于根据不同类型关键文档的格式特征,进行进一步判断并计算格式置信度p2;
32、裁剪模块,配置用于根据获取的特征所处的坐标信息裁剪待识别的文字图像,并使用文字识别模型将文字图像转换为文本内容;
33、词频p3计算模块,配置用于使用关键词库对文本内容进行关键词命中,计算命中的关键词个数在文本内容中所占的比率词频p3;
34、可能性p计算模块,配置用于将得到的置信度p1、格式置信度p2和词频p3设定权重计算文档为关键文档的可能性p;
35、判断模块,配置用于根据p值的大小,判断该文件是否是为关键文档。
36、第三方面,本发明实施例提供了一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现如第一方面中任一实现方式描述的方法。
37、第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如第一方面中任一实现方式描述的方法。
38、与现有技术相比,本发明的有益成果在于:
39、(1)通过使用深度学习及文本处理技术,实现高效准确地从不同类型的文档中识别出电子公文、财务报表、销售合同等关键文档,以便于对文档加以控制和保护,防止文件泄露。
40、(2)通过对不同文档的转换,结合深度学习和文本处理技术,提高关键文档的识别准确度;支持对不同类型的文档进行识别,提高文档类型的覆盖度;支持对关键文档更多特征的提取,提高识别率;支持对关键词库的自动维护,减少人工操作复杂度。
41、(3)通过对不同类型文档的转换,使该方案能够覆盖不同类型的文档;通过结合深度学习技术和文本处理技术,在不需要人为更新关键词库的情况下,该方案能够处理和发现不同类型的关键文档。
- 还没有人留言评论。精彩留言会获得点赞!