一种基于轻量化结构的虚拟试衣方法
本发明涉及虚拟现实与仿真,尤其涉及一种基于轻量化结构的虚拟试衣方法。
背景技术:
1、近年来,随着人们生活水平的提高和消费观念的转变,时尚行业特别是时尚电商领域取得了显著的进步。虽然越来越多的时尚品牌和电商网站提供了便捷的在线购物体验,但是消费者仍然面临一个困扰:无法直接试穿衣服。为此,虚拟试衣技术应运而生,目前主流的vton技术分为两种:基于3d模型和基于2d图像。基于3d模型的vton技术通常需要较强的硬件支持和运算能力,因此成本较高,而基于2d图像的vton技术则更加普及,将用户的照片与具有不同款式和颜色的服装模型进行匹配,从而生成虚拟的穿着效果图。
2、基于图像的虚拟试衣技术具有应用到人工智能的潜力,例如ar技术,它将虚拟视角与现实世界叠加在一起,为用户提供一种身临其境的体验。但是,据我们所了解,目前现有的基于图像的虚拟试衣方法在模型的复杂性上并没有充分考虑,fele等人在2022年提出的c-vton和xie等人在2023年提出的gp-vton试衣方法,上述方法都依赖于由人体解析器获得的人体语义分割图和人体姿势等信息实现服装变形,这类方法更注重提高试穿图像的质量。并且,这些模型网络结构复杂参数多,计算时间很长,无法应用于实时应用中。最新的一些研究方法如由ge等人在2021年提出的无解析器的虚拟试衣方法pfafn,he等人在2022年提出的fsvton试衣方法,上述研究已成功摆脱对人体解析器的依赖,这大大减少了运行时间。然而,它们仍然受到使用较大内存占用的困扰。
3、更重要的是,服装变形需要准确地识别和分割人体部位,以便将服装与人体对应。然而,由bai等人2022年提出的依赖人体解析器的daflow模型会在复杂场景、姿态遮挡或低对比度等情况下使得人体部位分割出现错误或遗漏,导致不正确的服装变形。
4、如何解决上述技术问题为本发明面临的课题。
技术实现思路
1、本发明的目的在于提供一种基于轻量化结构的虚拟试衣方法,在保持生成的试穿图像的一定精度的同时,减少模型计算量和运行时间,降低计算和存储成本,使得虚拟试衣系统更适用于资源受限的移动设备等场景;另外,提升服装外观特征的提取和建模能力,提高虚拟试衣系统的视觉效果和用户满意度。
2、本发明的发明思想为:本发明提供了一种基于轻量化结构的虚拟试衣方法,该框架基于预训练的模型mb生成输出图像作为轻量化结构的虚拟试衣模型m的输入,模型mb作为信息来源指导无需人体表示的轻量化结构的虚拟试衣模型m实现服装变形,该过程只在训练时存在,将模型m中将特征提取模块和生成模块同样基于mobilenetv2架构融合倒残差块,最终生成逼真的试穿图像,在保持生成的试穿图像一定精度的同时,降低计算和存储成本,使得虚拟试衣系统更适用于资源受限的移动设备等场景,另外,提升服装外观和细节特征的理解和建模能力,提高虚拟试衣系统的视觉效果和用户满意度。
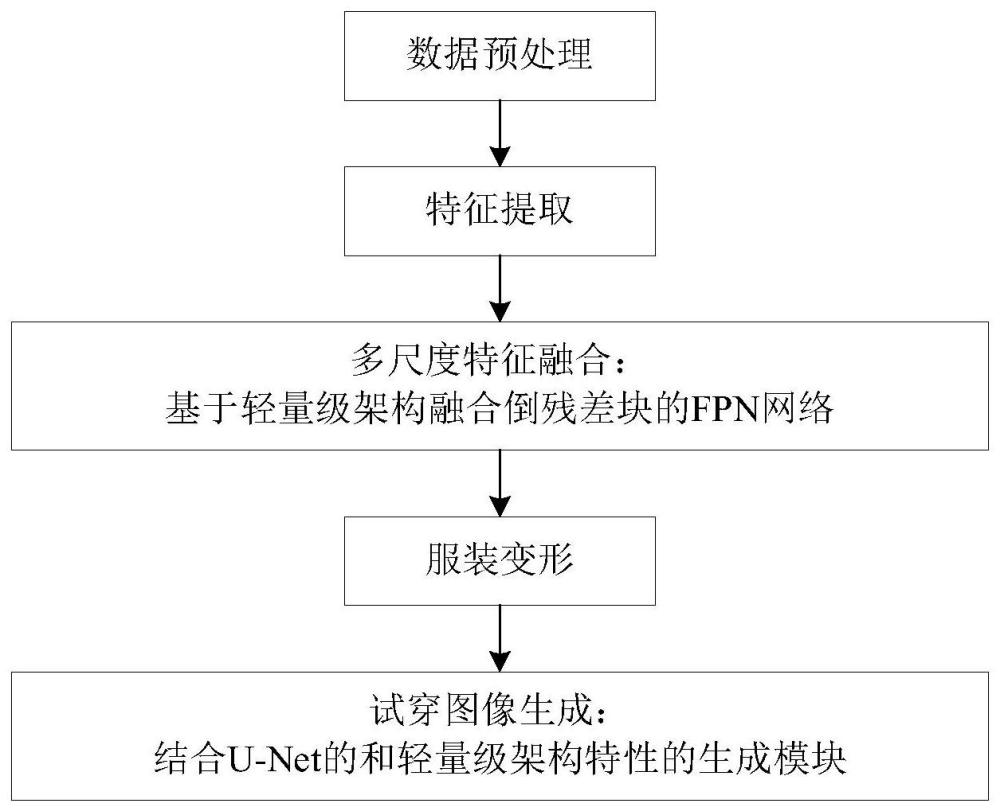
3、为了实现上述发明目的,本发明采用技术方案具体为:一种基于轻量化结构的虚拟试衣方法,包括以下步骤:
4、s1:获取人物图像q和选取目标服装图像g,将读取到的数据进行预处理和转换,得到经过转换的图像张量和服装张量。
5、s2:将人物图像和服装图像的张量数据通过两个编码器转化为特征表示,提取图像的特征向量。
6、s3:将两个分支的特征表示作为基于mobilenetv2架构融合倒残差块的fpn网络的输入,将其传递到他的自顶向下和横连接层中,在上采样过程中将低层次特征和高层次特征进行融合。
7、s4:将获得的两个分支的多尺度特征送到流估计网络中计算得出服装图像和人物图像之间像素级的对应关系,实现服装流估计,对目标服装特征图进行反向光流变换,得到最终的变形服装图像。
8、s5:将变形后的服装图像和人物图像送入一个结合u-net的编码-解码结构和轻量级架构mobilenetv2的特性的生成模块产生高质量的试穿图像。
9、具体地,将图像的宽度和高度调整为2的幂次方,避免尺寸不兼容的问题,在训练阶段会将图像进行翻转,增加数据的多样性和泛化能力。对图像进行标准化,使其像素值在[-1,1]之间。
10、进一步地,在训练阶段返回的数据字典包括图像文件名、服装文件名、随机选择的非配对服装名、解析图文件名、经过转换的图像、服装、服装边缘、非配对服装、非配对服装边缘、解析图、人体姿势和密集姿态的张量。在测试阶段数据字典包括经过转换的人体图像、服装、服装边缘的张量,人体图像和服装的文件名。
11、进一步地,构建一系列的残差块,每个倒残差块包含多个深度可分离卷积层和扩张卷积层,不同的倒残差块具有不同的扩张因子、宽度因子和步长。
12、进一步地,通过平均池化层之后将特征图降维为一个像素,以便对整个图像的语义信息进行上采样,因为最后一个倒残差块的输出为320,用一个1x1的卷积层将倒残差块的输出通道数降至256。
13、进一步地,相关性计算公式如下:
14、
15、其中,c(x,y)表示在输入服装图像g的位置(x,y)处的相关性权重;w是配准信息对应的特征张量,i和j代表局部区域每个像素点的偏移量。
16、进一步地,每一个子网络首先经过一系列卷积和激活函数操作进行非线性处理,对于每个金字塔层级根据上一层的光流将当前金字塔的输入进行变换,得到特征图根据输入信息计算服装图像和人物服装区域图像之间的相关性,得到相关性矩阵。然后使用leakyrelu激活函数对相关性进行非线性处理,将处理后的张量经过一系列conv和leakyrelu操作得到fc的估计值,接着对估计值进行偏移操作,将其应用到上一层的光流估计值上得到更准确地光流估计值利用当前光流场的估计对gi进行光流扭曲得到将对齐后的图像和当前层的特征图gi进行通道上的拼接并输入到细化层得到优化流fr,对其进行上采样操作得到下一层的光流估计结果,循环所有金字塔层级的特征图输出最终光流估计结果fi,对输入的服装特征图进行反向光流变换,得到最终的变形服装图像gw。
17、在训练过程中,服装变形模块损失函数定义为:
18、
19、
20、
21、其中,式(8)表示像素级别的损失,gw表示经过变形的服装图像,p表示带有服装掩码的真实人物图像;式(9)表示感知损失,φi是预训练vgg19模型的第i个块;式(10)中表示二阶平滑损失,表示蒸馏损失。
22、为了保留服装特征,引入二阶平滑损失进行优化,公式如下:
23、
24、式(11)中fit表示第i个尺度的流图中第t个点;nt是t点周围的水平、垂直和对角线邻域的集合;charloss代表广义charbonnier loss,最小化服装的形变与失真。
25、进一步地,结合u-net的编码-解码结构和轻量级架构mobilenetv2的特性的生成模块在编码器部分我们构建了7个倒残差块,每个倒残差块具有不同的参数设置,其中包括扩展因子、输入通道数、输出通道数和步长。每个倒残差块采用了深度可分离卷积结构减少参数量和计算量,首先根据扩张因子计算出中间层的通道数,根据步长来判断是否是用残差连接,如果需要则直接将输入数据与卷积结果相加并返回,否则直接返回。然后根据扩展因子的值确定是否需要通道扩张,数值为1则不需要,直接采用深度可分离卷积,否则先进行1×1的卷积进行通道扩张,再使用深度可分离卷积。然后,将编码器路径的特征图和解码器路径的特征图进行拼接,同时通过设置的倒残差块实现特征的融合,接着通过插值将上采样后的特征图尺寸恢复到原始输入图像的尺寸,为7×256×192,最后使用一个3×3卷积层得到最终的输出。
26、在合成人物图像和人物真实图像之间使用损失和感知损失来监督生成模块的训练过程,公式如下:
27、
28、其中式表示损失;表示感知损失,s和p表示模型m生成的输出图像和人物真实图像。
29、与现有技术相比,本发明的有益效果为:
30、1、基于3d模型的vton技术通常需要较强的硬件支持和运算能力,因此成本较高,而基于2d图像的vton技术成本低,计算量低,效率高。
31、2、在训练阶段,应用预训练模型mb生成的输出图像作为轻量化结构的虚拟试衣模型m的输入,作为信息来源指导模型m的训练,将一个大型的深度神经网络的知识传递给一个小型的深度神经网络,实现了模型的压缩和加速。
32、3、采用基于mobilenetv2架构融合倒残差块的fpn网络,倒残差块主要针对单个网络中有效地提取特征,并减少计算量和参数数量。而fpn主要用于多尺度特征融合,以便在不同层级上获取更丰富的语义信息。fpn可以从底层到顶层逐渐融合不同层级的特征图,而倒残差块可以在每个层级上进行高效的特征提取。将倒残差块和fpn结合在一起可以获得更好的多尺度表达能力,使模型对不同尺度的目标有更好的感知能力,在每个层级上更有效地进行特征提取和传播。
33、4、采用一个结合u-net的编码-解码结构和轻量级架构mobilenetv2的特性的生成模块,u-net常用于图像分割任务,已被证明是在保留服装纹理细节方面是有效的,mobilenetv2是一种专为移动设备优化的轻量级模型。基于轻量化架构的生成模块能够在产生高质量的试穿图像的同时,减少计算资源的消耗,缩小整个模型的体积。
- 还没有人留言评论。精彩留言会获得点赞!