基于轻量化视觉自注意力网络的双分支人像自动抠图模型
本发明属于图像处理领域,具体为基于轻量化视觉自注意力网络的双分支人像自动抠图模型。
背景技术:
1、人像抠图作为图像处理领域一项基础且极具挑战的视觉任务,旨在从输入图像或视频帧中预测一个透明度遮罩以提取人像前景,所提取的前景比语义分割处理的结果更加细腻自然,在图像编辑、广告制作、影音修改、行业直播等领域有着十分广泛的应用。自从20世纪70年代初以来,研究人员就广泛探索了与抠图相关的领域,从基于采样的方法到基于传播的方法的研究。然而,这两类传统的方法依赖低级的颜色或结构特征,这导致它们在复杂场景下存在抠取图像前景的完整性较差的问题,抠图算法的性能鲁棒性不佳。
2、传统抠图方法,通常将rgb通道图像与附加输入(即三元图和涂鸦)一起使用。三元图是将图像粗略地分割为三个部分:前景、背景和未知区域,而涂鸦则表示属于前景或背景的少量像素。额外输入的目的是降低透明度遮罩估计的难度,这是一个高度不适定的问题。根据如何使用附加输入,传统的抠图方法进一步分为两类:基于采样的方法和基于亲和力的方法。基于采样的方法通过类模型推断过渡区域的透明度值,该类模型是通过使用颜色特征以及采样像素的附加低级特征构建的。这些方法的准确性通常取决于三维地图的质量。基于亲和力的方法利用空间和颜色特征计算的像素相似性将已知前景和背景像素的alpha值传播到过渡区域。由于空间接近,基于亲和力的方法可以生成比基于采样的方法更平滑的遮罩。
3、目前的人像抠图方法dim采用传统的三元图作为辅助输入,增加了抠图用户的抠图成本,这是极其不便的,同时模型具有极大的参数量与计算量。shm方法虽然舍弃了三元图作为额外输入,但串行的网络结构使得模型出现语义错误不能很好地实现权重更新,影响了模型抠图监督。再者,两个模型并非端到端训练的模型。
4、现有的人像抠图方法大多是基于卷积神经网络特征编码的,虽然人像抠图任务中取得了高效的性能,但仍然存在三个主要问题:(1)使用繁琐的三元图作为辅助输入,耗费大量的时间和精力并导致高昂的人力成本。(2)使用大型的深度学习模型如resnet或densenet通常会导致模型具有大量的参数和较高的计算复杂度,需要更多的计算资源和存储空间,使得这些模型在部署到嵌入式设备或需要低延迟的实时应用中变得不够实际。(3)卷积核的大小限制了卷积神经网络的感受野,无法进行长距离建模,难以提取有用的人像边界和图像细节。
技术实现思路
1、为解决上述技术难点,本发明提出一种基于轻量化视觉自注意力网络的双分支人像自动抠图模型,创新地将人像抠图任务分解为伪三元图生成以及细节提取两个路径分支,构建单编码器-双解码分支的模型结构,实现了无需额外输入的高效的人像自动抠图。
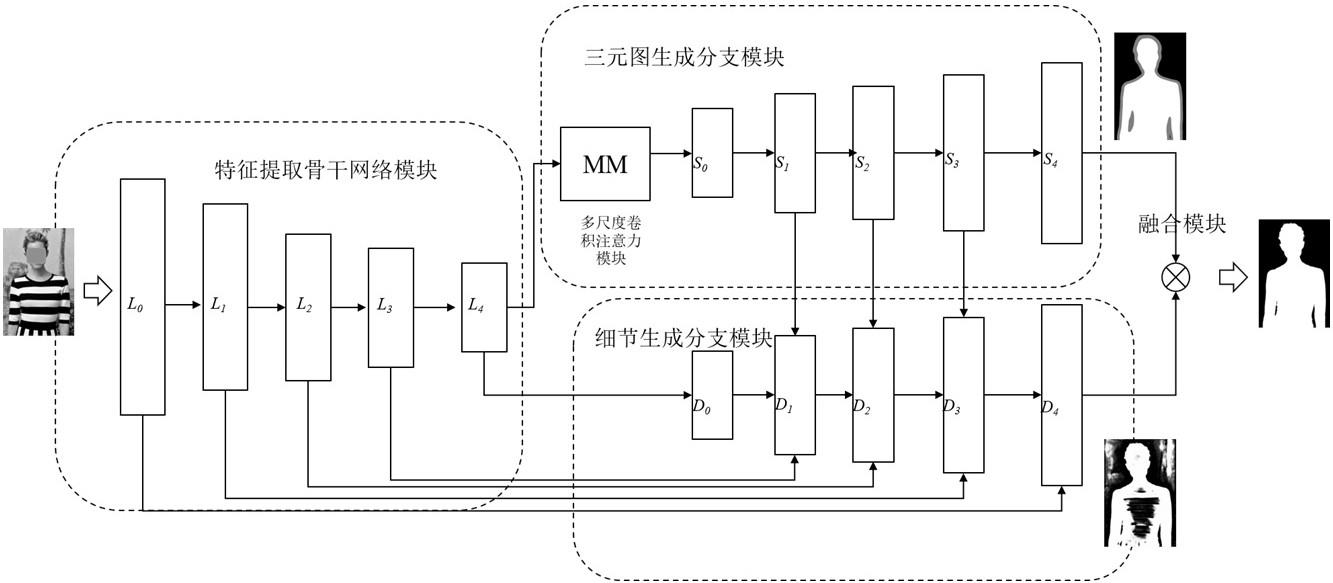
2、本发明采用的技术方案如下:基于轻量化视觉自注意力网络的双分支人像自动抠图模型,包括特征提取骨干网络模块、三元图生成分支模块、细节提取分支模块和融合模块;
3、特征提取骨干网络模块使用轻量化视觉自注意力网络用于特征编码,特征提取骨干网络模块分别连接三元图生成分支模块、细节提取分支模块,三元图生成分支模块和细节提取分支模块位置分布上呈并行结构且设置特征交互,三元图生成分支模块、细节提取分支模块后连接融合模块;
4、特征提取骨干网络模块,一共有五个层级的编码层,每个层级的编码层都包括轻量化倒残差块mv2和轻量化视觉自注意力块mvit,轻量化倒残差块mv2和轻量化视觉自注意力块mvit组合进行人像特征提取,轻量化倒残差块mv2用于调整输入特征通道数和深度可分离卷积,轻量化视觉自注意力块mvit用于特征的局部和全局双重建模;具体包括:
5、步骤s1,通过轻量化倒残差块mv2以1×1的卷积核调整输入的特征f0通道数,以大小为3×3的卷积核对输入的特征f0进行深度可分离卷积操作,输出特征;
6、步骤s2,通过轻量化倒残差块mv2进一步使用逆操作,对步骤s1的输出特征进行上采样;使用深度可分离卷积操作进行特征提取,轻量化倒残差块mv2进一步下采样,得到输出的特征f1,同时使输出的特征f1维持输入时的维度;
7、步骤s3,通过轻量化视觉自注意力块mvit对输入的特征f1进行下采样,将下采样后输入的特征f1进行分块得到块状特征,并将块状特征铺平,轻量化视觉自注意力块mvit从左至右取对应位置的像素点经自注意力机制计算得到输出的特征f2;
8、步骤s4,轻量化视觉自注意力块mvit通过残差连接,拼接输入特征f1和特征f2得到f3,特征f3再通过一个卷积核大小为3×3的卷积层做特征,融合得到输出的特征f4;
9、步骤s5,输入图像i经过五个层级的编码层,经过步骤s1-步骤s4后分别输出五个层级特征,f为最终输出特征;
10、三元图生成分支模块,包括多尺度注意力模块mm和三元图多重解码块;具体包括步骤s6和步骤s7:
11、步骤s6,特征提取骨干网络模块得到的最终输出特征f,通过多尺度注意力模块mm中的深度卷积聚合局部信息,利用多尺度注意力模块mm中捕获多尺度上下文的多分支带状卷积,提取不同尺度人像特征,使用1×1卷积建模不同尺度人像特征中不同通道之间的关系;
12、将1×1卷积的输出直接作为输入特征f注意力权重,对输入特征f进行重新加权运算操作;多尺度注意力模块mm计算见公式(1):
13、(1);
14、其中,表示多尺度注意力模块mm最终输出,f表示输入特征,是逐元素矩阵乘法运算操作,conv1×1表示进行卷积核大小为1×1的卷积操作,scalej表示多分支卷积中的第j个分支,j∈{0,1,2,3},scale0是一个直接连接,dwconv表示深度卷积;
15、步骤s7,多尺度注意力模块mm最终输出o送入5个解码块组成的三元图多重解码块中,依次还原输出64×64、128×128、256×256、512×512大小的特征,每个解码块都有3个卷积层、3个批量归一化层和3个relu层堆叠而成,最终生成与特征f0大小一致的三元特征图ftrimap,三元特征图ftrimap包含人像前景区域、背景区域、未知区域;
16、细节提取分支模块,包括残差连接结构与细节多重解码块,细节提取分支模块与三元图生成分支模块利用残差连接结构形成交互,细节多重解码块解码输入特征,输出细节特征图fdetail;具体为:
17、步骤s8,输入特征提取骨干网络模块得到的最终输出特征f,通过五个层级的细节多重解码块,每个解码块都有3层3×3卷积层、2层bn层、2层relu层和一个上采样层,堆叠的五个层级的细节多重解码块输出人像的细节特征图fdetail;
18、步骤s9,在五个层级的细节多重解码块中,特征提取骨干网络模块和五个层级的细节多重解码块输入进行残差连接,共享特征提取骨干网络模块与细节多重解码块的网络参数;
19、融合模块,合并三元特征图ftrimap和细节特征图fdetail,生成人像透明度遮罩预测图;具体为:
20、步骤s10,利用sigmoid函数激活三元特征图ftrimap和细节特征图fdetail的预测概率矩阵,通过预测概率矩阵构建三元特征图掩码、细节特征图掩码,在三元特征图ftrimap未知区域,与细节特征图掩码进行点乘操作,限制三元特征图ftrimap未知区域内的概率值;对于细节特征图fdetail未知区域,与细节特征图掩码进行点乘操作,形成人像前景概率值分布;
21、步骤s11,利用组合损失函数监督三元图生成分支模块、细节提取分支模块和融合模块训练,训练损失l分为三个部分,即三元图生成分支模块损失ls、细节抠图分支模块损失ld和融合模块的损失lf。
22、进一步的,使用轻量化视觉自注意力块mvit用于特征的局部和全局双重建模,提取人像特征,计算流程具体见公式(2)、公式(3)、公式(4)、公式(5)、公式(6):
23、(2);
24、(3);
25、(4);
26、(5);
27、(6);
28、其中,表示经过卷积操作后得到的特征,,表示特征的行方向的维度、列方向的维度以及通道数大小,r表示实数的集合;
29、分别表示卷积核大小为n×n和1×1的卷积操作,x0表示输入特征,,表示特征的行方向的维度、列方向的维度以及通道数大小;
30、其中,表示经过切分后得到的n个特征块,,为特征行方向的维度,n为特征块的数量,表示特征切分操作函数;
31、其中,表示经过自注意力机制建模后得到的特征块,q表示每个特征块中的像素,,hxg表示xg特征块行方向的维度,表示特征块的通道数大小,表示对自注意力计算建模操作函数;
32、其中,表示折叠操作后得到的特征块,,表示特征块的行方向的维度、列方向的维度以及通道数大小,表示折叠操作函数,即逆切分操作;
33、其中,x表示经过卷积操作后得到的输出特征,,表示特征的行方向的维度、列方向的维度以及通道数大小;
34、在轻量化视觉自注意力块mvit进行特征建模过程中,输入特征经过n×n卷积用于学习局部的空间信息,经过1×1卷积调整输入特征的通道数;利用操作获得,紧接着通过操作对特征进行全局建模得到特征块,将建模好的特征块进行折叠操作恢复成原始大小即折叠操作后得到的特征块;经过折叠操作后得到的特征块送入1×1的卷积层中调整通道数为c,最后使用n×n卷积操作融合局部和全局信息,经过卷积操作后得到输出特征x。
35、进一步的,步骤s6中,公式(1)中多尺度注意力模块mm最终输出o送入三元图多重解码块中,见公式(7)、公式(8)、公式(9):
36、(7);
37、(8);
38、(9);
39、其中,表示第k层卷积层输出特征,表示第k层卷积核的权重矩阵,表示第k层卷积层的偏置向量;表示第k层批量归一化层输出的特征,表示批量归一化操作,表示第k层激活函数后输出特征,表示激活函数操作;
40、步骤s8中,将特征提取骨干网络模块得到的最终输出特征f送入细节生成分支模块中,见公式(10)、公式(11)、公式(12):
41、(10);
42、(11);
43、(12);
44、其中,表示拼接操作,表示骨干网络中第k层级的编码特征,表示第k层卷积层输出特征,表示第k层批量归一化层输出的特征,表示第k层激活函数后输出特征。
45、进一步的,将三元图生成分支模块与细节提取分支模块预测结果送入融合模块中,见公式(13)、公式(14)、公式(15):
46、(13);
47、(14);
48、(15);
49、其中,表示三元特征图预测概率矩阵,ftrimap表示三元特征图, 表示细节特征图预测概率矩阵,fdetail表示细节特征图,e为一个自然常数,表示最终预测的人像透明度遮罩预测图,分别表示细节特征图掩码和三元特征掩码,表示点乘操作;
50、利用sigmoid函数激活预测概率矩阵,将预测概率矩阵的每个元素的取值范围限制在0到1之间,根据三元图分支模块的预测概率矩阵设置阈值以构建一个三元特征图掩码,三元图特征掩码每个元素的值表示对应位置的像素是否属于前景对象,根据细节提取分支模块的预测概率矩阵构建一个细节特征图掩码;分别对三元图特征掩码和细节特征图掩码进行点乘操作。
51、进一步的,步骤s11中,模型整体损失l见公式(16):
52、(16);
53、其中,分别为三元图生成分支损失权重值、细节提取分支损失权重值、融合模块损失权重值;
54、三元图生成分支模块采用交叉熵损失函数,其定义见公式(17):
55、(17);
56、其中,表示像素点的真实标签,,表示像素点是第c类的预测概率值,;
57、细节提取分支模块采用混合损失函数进行监督,见公式(18):
58、(18);
59、其中,表示透明度遮罩的真值标签,表示未知区域的预测值,i表示像素索引数,表示像素i是否属于未知区域,,是一个自定义实数,表示真值标签的第k层拉普拉斯金字塔,表示融合模块预测未知区域的值的第k层拉普拉斯金字塔,表示l1范式的计算函数;
60、融合模块的训练损失由多部分组成,定义见公式(19):
61、(19);
62、其中,为融合模块中预测的透明度遮罩,m为图像中的像素总数。
63、本发明的有益效果是:(1)较其它使用三元图作为输入的方法,本发明仅使用一张rgb图像作为输入用于抠图,实现了自动抠图;(2)通过采用轻量化视觉自注意力网络架构作为人像抠图模型的骨干网络模块,提高了模型的表征能力的同时降低了模型的复杂度;(3)设计多尺度卷积注意力模块,提高了人像边缘细节的抠图效果。
- 还没有人留言评论。精彩留言会获得点赞!