融合知识图谱与图注意网络的企业违规数据检测识别方法
本发明涉及知识图谱和风险数据识别领域,特别涉及一种融合知识图谱与图注意网络的企业违规数据检测识别方法。
背景技术:
1、上市企业合规性监管是确保证券市场公正透明的必要前提,也是保护投资者合法权益和进一步推动金融市场的稳健繁荣的重要举措。然而,企业违规行为的披露存在滞后性,通常存在两年之久的监测“空窗期”,致使已经发生违规行为的企业样本数据迟迟未能被准确检测甄别,难以让监管人员及投资者及时辨别出异常企业,为监管不力与投资者蒙受损失埋下隐患。
2、关于上市企业违规数据检测的现有方式通常是运用统计规则或机器学习模型来对结构化数据进行分析,这种方式忽视了企业所遭遇的异常事件风险以及企业间的风险传播动向,而且过于依赖于既定的企业经营指标等数值化信息。伴随大规模语义关联网络知识图谱的迅速发展,其展示出对于多源异构化数据具有卓越的知识表征能力,能够在传统关联网络的拓扑结构信息的基础上增添丰富的语义知识特征,也为建立语义层级的多元化企业风险知识体系奠定了基础。将知识图谱与企业风控相结合的研究方向吸引了相关学者的广泛关注,在企业亏损风险、信贷失约风险等特定业务领域开展了深入探讨与应用。
3、但是现有企业风险网络分析方法在风险传播方法机理层面尚有可优化空间。一方面,合规企业节点即使本身不携带风险,但由于大面积关联节点的微小额度风险值产生汇聚而汲取到过高的风险值,造成部分合规企业节点存在被误传播的负面影响。另一方面,现有企业风险网络分析研究通常基于随机游走模式更新各企业节点的风险值,风险源节点在风险传播过程中将大概率遗失部分的初始风险值,致使高风险节点所携带风险值被过度稀释,出现衰减过度而偏离合理风险水平的现象。此外,现有企业违规数据风险甄别方法的评估维度偏单一化,对于企业不良突发事件、经营指标异常、集群化风险因素以及风险流动传播涉及的多渠道的风险因素缺乏考量,从既有合规企业样本数据与违规企业样本数据识别出的风险特征差异化并不明显,难以完成形成具有较高泛化性与准确性的违规样本数据检测识别方法。
技术实现思路
1、为解决上述技术问题,本发明提供了一种融合知识图谱与图注意网络的企业违规数据检测识别方法,以达到提高上市企业违规数据检测识别精度的目的。
2、为达到上述目的,本发明的技术方案如下:
3、一种融合知识图谱与图注意网络的企业违规数据检测识别方法,包括如下步骤:
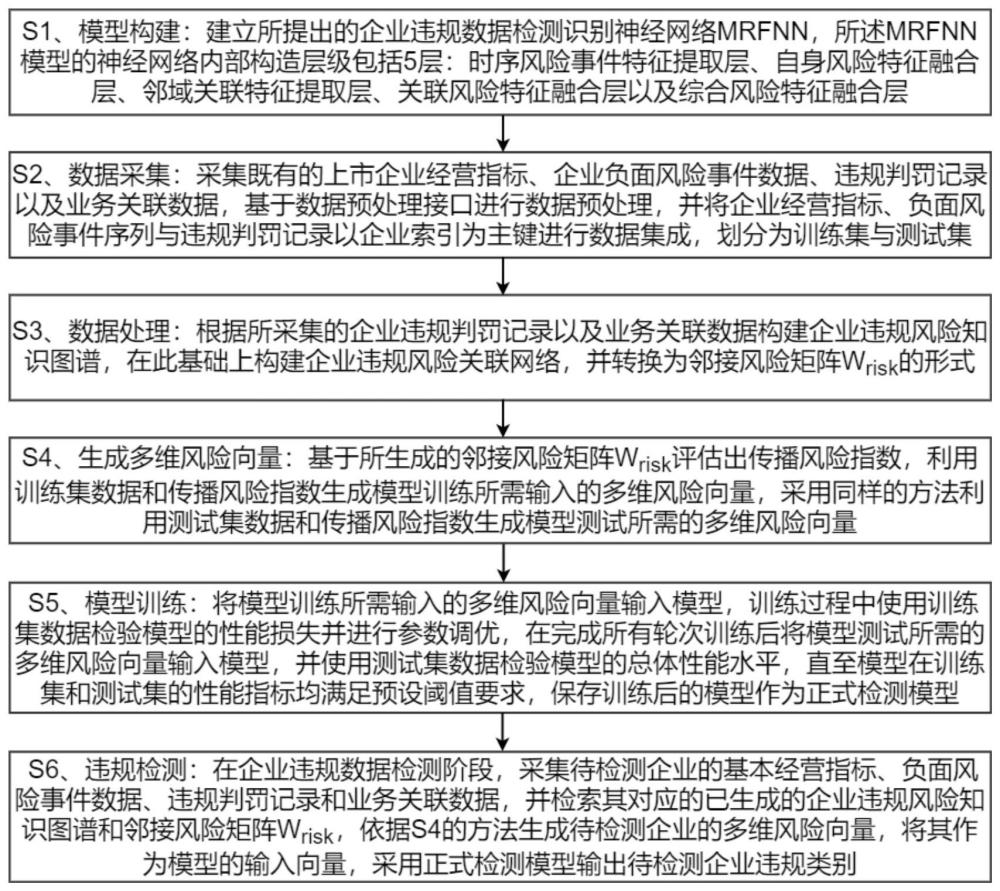
4、s1:模型构建:建立企业违规数据检测识别mrfnn神经网络模型,所述模型的内部构造层级包括5层:时序风险事件特征提取层、自身风险特征融合层、邻域关联特征提取层、关联风险特征融合层以及综合风险特征融合层;
5、s2:数据采集:采集既有的上市企业的基本经营指标、负面风险事件数据、违规判罚记录以及业务关联数据,进行数据预处理,并将预处理后的基本经营指标、负面风险事件数据与违规判罚记录以企业索引为主键进行数据集成,划分为训练集与测试集;
6、s3:数据处理:根据采集的违规判罚记录以及业务关联数据构建企业违规风险知识图谱,在此基础上构建企业违规风险关联网络,并转换为邻接风险矩阵wrisk的形式;
7、s4:生成多维风险向量:基于所生成的邻接风险矩阵wrisk评估出传播风险指数,利用训练集数据和传播风险指数生成模型训练所需输入的多维风险向量,采用同样的方法利用测试集数据和传播风险指数生成模型测试所需的多维风险向量;
8、s5:模型训练:将模型训练所需输入的多维风险向量输入模型,训练过程中使用训练集数据检验模型的性能损失并进行参数调优,在完成所有轮次训练后将模型测试所需的多维风险向量输入模型,并使用测试集数据检验模型的总体性能水平,直至模型在训练集和测试集的性能指标均满足预设阈值要求,保存训练后的模型作为正式检测模型;
9、s6:违规检测:在企业违规数据检测阶段,采集待检测企业的基本经营指标、负面风险事件数据、违规判罚记录和业务关联数据,并检索其对应的已生成的企业违规风险知识图谱和邻接风险矩阵wrisk,依据s4的方法生成待检测企业的多维风险向量,将其作为模型的输入向量,采用正式检测模型输出待检测企业违规类别。
10、上述方案中,s1中模型构建包括如下步骤:
11、step1:设计mrfnn神经网络的时序风险事件特征提取层,通过gru门控神经网络生成出企业历史风险事件特征向量,采用更新门与重置门来提取有效特征;
12、具体地,重置门控制前一个时间步的隐层状态向量ht-1中的信息有多少将被保留在当前时间步的候选隐层状态矢量中,更新门控制当前时刻的输入特征xt与前一时间步的隐层状态向量ht-1,融合生成当前时间步的隐层状态向量ht;
13、具体地,时序风险事件特征提取层的公式如下:
14、rt=σ(wrxxt+wrhht-1+br)
15、zt=σ(wzxxt+wzhht-1+bz)
16、
17、
18、dt=σ(wo*ht)
19、其中,rt与zt分别为gru重置门状态向量与更新门状态向量;wrx,wrh,br分别为重置门当前时间步权重、重置门前一时间步权重、重置门偏置向量;wzx,wzh,bz分别为更新门当前时间步权重、更新门前一时间步权重、更新门偏置向量;whx,whh,bh为候选隐层当前时间步权重、候选隐层前一时间步权重、候选隐层偏置向量,进而控制当前时间步候选隐层向量的生成;
20、当前时间步隐层向量ht经过权重矩阵wo与激活函数σ的转换后生成当前状态的输出向量dt;最后一个时间步的输出向量即为企业历史风险事件特征向量初始输入特征xt作为事件风险特征输入向量被预先提供;
21、step2:设计mrfnn神经网络的自身风险特征融合层,融合企业经营指标特征输入向量与历史风险事件特征向量自身风险特征融合层的公式如下:
22、
23、其中,wu为目标企业i的超参数权重,fi为企业自身风险特征向量,企业经营指标特征输入向量是企业经营指标的向量化表征,作为输入向量被预先提供;
24、step3:设计mrfnn神经网络的邻域关联特征提取层,在多关系注意力神经网络基础上采用多头注意力汇聚生成出来源于不同关系类别的企业邻域关联特征向量,并采用残差连接的方式防止原始企业节点特征过度遗失,邻域关联特征提取提取层的公式如下:
25、
26、
27、
28、
29、
30、其中,邻域风险特征输入向量作为输入向量被预先提供,vh为头实体h的一阶邻域节点集合,eh为实体h与邻接节点间的关系集合,为实体h邻域内任意三元组的注意力贡献,为实体h自身的注意力权重,为实体h单通道内汇聚后的注意力特征,为实体h多通道汇聚后的注意力特征,为第k层多头注意力的融合矩阵,concat代表向量拼接操作,σ为relu激活函数,m为多头注意力机制的总数量,为企业实体h的初始特征,为该神经网络模块最后一层传输后的多元关系综合注意力特征向量,为企业i的邻域关联风险特征向量,为用于调节残差连接特征融合比例的超参数;
31、step4:设计mrfnn神经网络的关联风险特征融合层,融合传播风险特征输入向量与邻域关联风险特征向量ui,具体公式如下:
32、
33、具体地,传播风险特征输入向量作为输入向量被预先提供;
34、step5:设计mrfnn神经网络的综合风险特征融合层,采用包含两层线性层与relu激活函数的mlp神经网络模块对企业自身风险特征fi进行维度变换生成向量并引入mish激活函数完成企业关联风险特征ui的非线性激活,融合为企业综合风险特征向量再通过全连接层映射为模型所检测的企业违规类别具体计算公式如下:
35、
36、
37、
38、其中,w1与w2为两层线性层的权重向量,b1与b2为偏置向量,f用于在训练过程中调节企业自身风险特征与关联风险特征的融合比例,是可训练的超参数,w3与b3为最终输出层的超参数向量。
39、上述方案中,s3的数据处理包括如下步骤:
40、(1)定义企业违规风险知识图谱的模式层,规定特定实体类型和关系类型的约束条件,以确保数据的一致性和准确性;
41、(2)根据所定义的企业违规风险知识图谱的模式层,采用d2r server工具编写r2rml映射语言,分别将企业违规判罚记录以及业务关联数据转换为rdf格式的三元组,构建出不同时区对应的企业违规风险知识图谱;
42、(3)根据不同时区的企业违规风险知识图谱,评估不同时间区间条件下的企业直接关联风险传播概率与间接关联风险传播概率;
43、(4)基于风险路径概率融合计算企业间的综合风险传播概率,生成不同时区的企业违规风险关联网络,并将其转换为邻接风险矩阵wrisk的形式。
44、进一步的技术方案中,步骤(3)中,企业直接关联风险传播概率与间接关联风险传播概率的计算方法如下:
45、针对知识图谱中的任意企业节点依次检索其一阶邻域范围内的关联企业节点及关系类型,计算企业直接关联风险传播概率,任意节点vk与其邻接节点vfir间的路径携带的企业直接关联风险传播概率计算公式如下:
46、
47、其中,为包括持股、控股、投资关系的企业直接风险关联类别集合,代表任意一种关系,为关联类别为的企业直接关联总数,evio代表高风险状态,即对于任意的关系efir,若关系两端的企业节点其中一方当年度处于违规状态,并且另一端企业节点半年内同样出现违规行为;sum(evio)代表满足高风险关联状态的关系数目总和;
48、针对不同类别的间接关联类型,采用不同的风险概率评估方式,节点vk与二阶关联节点vsec的企业间接关联风险传播概率计算公式如下:
49、
50、其中,pfir与psec为一阶关联efir与二阶关联esec的传播概率,为一阶关联类别与二阶关联类别构成的间接关系元组,代表间接关系元组总数,代表节点vk与vsec存在共同的直接利益关联企业节点,代表当年度目标企业间存在共同任职人员。
51、进一步的技术方案中,步骤(4)中,邻接风险矩阵wrisk的计算方法如下:
52、对于头节点vh与尾节点vt,若节点对(vh,vt)间存在多条企业风险关联路径,采用多变量条件概率计算方法求解节点对间的综合风险传播概率并作为企业违规风险关联网络的权重,具体计算公式如下:
53、
54、其中,为节点对(vh,vt)间任一路径的风险概率项。
55、上述方案中,s4中生成多维风险向量的方法如下:
56、步骤1,根据目标企业索引,检索s3所生成的企业违规风险知识图谱,评估目标企业的初始风险值节点vi初始风险评估的公式具体如下:
57、
58、其中,为企业节点vi的邻接违规事件节点集合,为其中的违规事件节点;为节点对应的违规行为类别;为节点的风险时间区间,即违规事件发生的月份至当年度1月份的间隔月份;代表当年度发生类别为的违规事件的企业节点总数,代表类别违规事件发生后企业节点vi的邻接企业节点半年内相继发生违规行为的企业总数;
59、步骤2,根据s3所生成的邻接风险矩阵wrisk获取目标企业样本vi与邻域企业节点vj间的综合风险传播概率基于pvr-le算法结合初始风险值评估目标企业节点的风险水平,并衰减大规模小额风险汇聚产生的高额风险值,对拥有较多邻接节点的企业节点传播风险指数予以一定程度削弱,评估目标企业的传播风险指数
60、步骤3,生成多维风险向量:将目标企业的时序风险序列向量化生成事件风险特征输入向量xt,将目标企业的基本经营指标向量化生成企业经营指标特征输入向量将目标企业邻域范围内的知识图谱三元组进行特征嵌入,生成目标企业的邻域风险特征输入向量将目标企业传播风险指数向量化生成传播风险特征输入向量
61、进一步的技术方案中,步骤2中目标企业的传播风险指数的计算方法如下:
62、在风险传播深度迭代的衰减策略方面,引入风险传播动态调节因子δ控制阻尼系数的衰减速率,使得各节点风险值的流失速度在违规样本数据风险传播陷入深度迭代时逐渐减缓;目标企业节点vi基于pvr-le算法的第轮次传播风险指数的计算公式如下:
63、
64、
65、其中,由步骤1评估生成,ξ代表初始阻尼系数,为迭代轮次,θ为风险衰减开始减缓的最小轮次阈值,为最大迭代轮次,防止风险传播的收敛周期过长,vj为企业节点vi的邻接企业节点集合内的企业节点,为上轮次企业节点vj的传播风险指数;
66、目标企业节点vi风险削弱后的传播风险指数计算公式如下:
67、
68、其中,为最后一轮迭代后企业节点vi携带的传播风险指数,n(vi)为节点vi的邻接节点数目,ω代表控制风险衰减速率的线性权重,β代表控制风险衰减速率的幂次权重。代表风险衰减比例下限。
69、进一步的技术方案中,步骤3中,企业时序风险序列由目标企业负面风险事件数据包含的事件发生月份、事件类别、事件发生次数构成,维度拼接后被向量化为初始的事件风险特征输入向量xt;
70、目标企业邻域范围内的知识图谱三元组(h,r,t)采用多通道图注意力网络完成特征嵌入,任意通道内目标企业邻域风险特征输入向量的生成公式如下:
71、
72、其中,||代表向量拼接,分别为实体h,实体t与关系r经过第k-1层注意力层后的特征表示,m代表多通道注意力机制下的通道序号,与分别用于实体特征与关系特征的线性变换,是可训练的权重参数,g是将拼接后的高维特征映射为实数的参数向量,leakyrelu是激活函数。
73、上述方案中,s5中模型训练的具体方法如下:
74、(一)设定mrfnn神经网络模型的各项初始化模型训练的超参数,并拟定训练神经网络的损失函数,进而以多维风险向量作为模型输入开始迭代训练神经网络;
75、具体地,采用交叉熵损失函数计算mrfnn神经网络的损失具体公式如下:
76、
77、其中,为企业违规样本数据模型所识别的分类值,yk为企业违规类别真实值;
78、(二)根据设定的初始学习率,采用余弦退火学习率调度器对训练过程中每个训练轮次的学习率αt进行动态调节,具体公式如下:
79、
80、其中,αmin为预设置的最小学习率阈值,αmax为预设置的最大学习率阈值,t是总的训练周期数,t是当前的训练周期;
81、(三)根据设定的损失函数、权重参数,基于训练集数据计算每一轮次训练完毕后各项权重参数相对于损失函数的梯度信息,并根据梯度信息与动态调节后的学习率αt,采用adamw作为神经网络参数优化器,对mrfnn神经网络模型的训练权重参数执行调优更新操作;权重参数的调优更新伴随训练轮次的迭代持续进行,针对每个训练轮次的权重参数迭代更新公式如下:
82、
83、其中,wt代表训练轮次t涉及的权重矩阵,αt是轮次t当前的学习率,mt是用于存储梯度移动量的平均值,vt是用于存储梯度平方移动量的平均值,ε是用于防止分母为零的小数值常数,λ是l2正则化参数,用于降低权重参数的变化幅度;
84、(四)当训练轮次达到所预设置的最大训练轮次时,终止训练,并以最后一轮次训练后的mrfnn神经网络作为最优候选模型,并以auc、g-mean、recall作为评估指标,判断针对训练集数据的检测性能是否达到所述评估指标的预设阈值要求;
85、具体地,若训练集性能达到预设阈值要求,则进入训练模型验证阶段;若训练集性能未达到预设阈值要求,则返回步骤(一)根据神经网络调参准则重新拟定模型的初始化参数;
86、(五)在训练模型验证阶段,重复进行模型测试输入的预处理,使用测试集数据检验模型的性能水平,若达到预设阈值要求,则将最优候选模型标记为正式检测模型用于后续阶段的违规数据检测,若未达到预设阈值要求,且超过3.5%的误差容忍度,则将检测样本标记为需要重新检测的失败样本,需重新拟定模型的初始化参数并重复上述模型训练过程;
87、(六)基于测试集数据,分别选取机器学习模型逻辑回归、xgboost以及lstm神经网络与异构图图神经网络与所生成的mrfnn正式检测模型进行多轮次的对比测试,进一步检验模型的性能效果。
88、上述方案中,s6中违规检测的具体方法如下:
89、①对于待检测企业涉及的非结构化数据,即负面风险事件数据及违规判罚记录,输入至企业违规数据信息预处理接口函数,采用ocr技术完成pdf文件的识别与文字转换,并通过正则表达式提取涉事企业、违规事件、违规类别等事件元素;并对于待检测企业涉及的结构化数据,即基本经营指标、业务关联数据进行结构化数据预处理;
90、②以待检测企业的企业唯一索引为主键,检索其对应的步骤s3已生成的企业违规风险知识图谱和邻接风险矩阵wrisk;
91、③重复步骤s4对待检测的目标企业样本进行向量化预处理,得到由事件风险特征输入向量xt、企业经营指标特征输入向量邻域风险特征输入向量传播风险特征输入向量所组成的待检测企业样本的多维风险向量;
92、④将待检测企业样本的多维风险向量作为mrfnn神经网络模型的输入,基于步骤s5训练得到的且被标记为正式检测模型的mrfnn神经网络输出待检测企业违规类别。
93、通过上述技术方案,本发明提供的一种融合知识图谱与图注意网络的企业违规数据检测识别方法具有如下有益效果:
94、(1)针对于现有企业违规样本数据风险传播方法存在微小额度风险值大规模汇聚产生过高的风险值,造成部分合规企业节点样本存在被误传播的问题,本发明引入风险权重平滑衰减机制,设定触发风险衰减的邻接节点阈值以及风险衰减速率,对拥有较多邻接节点的企业节点风险值予以一定程度削弱,以拟合企业的真实违规风险值,有效缓解了处于高风险集群的合规企业被误识别为违规企业的问题。
95、(2)针对现有企业违规样本数据风险传播方法中出现的风险源节点在风险传播过程中将大概率遗失部分的初始风险值,致使高风险节点所携带风险值被过度稀释而偏离合理风险水平的问题,本发明提出一种新颖的并且契合于企业风险传播过程的风险传播机制pvr-le,通过控制后续不同风险模式的权重系数占比,使得各节点初始风险值的流失速度在违规样本数据风险传播陷入深度迭代时逐渐减缓,而未达到风险值流失衰减轮次时能够保持原有风险状态,企业风险值根据轮次变化而动态调整,遏制违规企业节点在风险传播过程中自身风险被稀释的效应。
96、(3)针对现有企业违规数据检测识别方法考量维度较为单一、片面的问题,本文提出了融合多元化风险因素的企业违规数据检测神经网络mrfnn,改良异构关系图神经网络嵌入企业违规关联知识图谱的多源异构信息,完成企业关联特征的表征。并基于gru神经网络模块汲取时序负面事件特征,将企业基本特征、企业邻域关联特征、企业负面事件特征以及风险大规模传播特征相融合,针对具有不同违规特征的企业实现个性化的违规样本数据识别评估,相比于现有方法显著提高了上市企业违规数据检测识别的精度。
- 还没有人留言评论。精彩留言会获得点赞!