融合知识图谱实体属性值的机器阅读理解方法及系统
本发明涉及人工智能,具体涉及一种融合知识图谱实体属性值的机器阅读理解方法及系统。
背景技术:
1、随着信息技术和互联网的快速发展,中文互联网上每天产生大量的文本类型数据既蕴含着丰富的知识和信息,也充斥着大量的重复文本和噪声。为节省人们筛选分析互联网上文本信息的时间,机器阅读理解利用人工智能算法赋予了计算机阅读和分析文本的能力。
2、目前的机器阅读理解任务还停留在依赖问题和文本的匹配关系阶段,对于需要额外知识推理的问题效果不好。引入外部知识是解决该问题的一种方法。中文机器阅读理解任务中,一般将知识图谱作为外部知识。然而,知识图谱的引入面对两大挑战:首先,中文知识图谱中存在较多的是“实体-属性-属性值”类型的三元组,针对该类型三元组的编码方式目前还是空白。其次,如何将编码后的知识融合到模型自身参数是不可缺少的一环。
3、现有的一种基于外部知识增强的机器阅读理解方法、系统、装置。包括生成问题及原文文本中各实体的上下文表示;基于外部知识库,获取问题及原文文本中各实体的三元组集合及原文文本中各实体相邻实体的三元组集合;并基于三元组集合,通过外部知识图谱获取各实体的知识子图;通过图注意力网络更新融合知识子图,获取知识表示;通过哨兵机制将上下文表示和知识表示进行拼接,通过多层感知器和softmax分类器获取待回答问题的答案。该方法利用图结构信息,虽然能够充分挖掘三元组中实体间蕴含的深层信息,使机器阅读理解任务完成的效果更好。但是中文知识图谱中“实体-关系-实体”类型三元组占比较少,实体的知识信息更多来源于“实体-属性-属性值”类型三元组中的属性值。即使该发明充分挖掘了实体间的深层关系,可学习的知识仍然有限。
4、现有的另一种基于外部知识和片段选择的抽取式阅读理解方法。该发明提供了一种融合外部知识丰富文本和问题特征的方法,包括获取数据并对数据进行预处理;将预处理后数据送入训练好的抽取式阅读理解模型,通过抽取式阅读理解模型输出针对数据的问题的最佳答案;抽取式阅读理解模型包括spanbert编码模块、外部知识融合模块以及片段选择模块。然而该方法虽然通过多头注意力机制使得外部知识丰富了文本和问题的特征,但仍然需要哨兵向量来判断外部知识是否为符合文本和问题所需要的知识,增加了模型的参数量和计算复杂度。
5、综上,现有的知识表示学习技术的对象是“实体-关系-实体”类型的三元组,旨在对知识图谱中的实体和关系进行编码,并将实体向量化表示出来。但该类型三元组在中文知识图谱中占比较少,仅引入实体及实体间的关系不能够充分反应实体蕴含的知识信息,还需加入实体自身属性的知识。知识图谱利用不充分,且蕴含知识的三元组的数据结构独立于机器阅读理解任务。现有技术在知识融合部分需引入哨兵向量判断是否引入外部知识,使得模型参数量增加,计算复杂度提升。
技术实现思路
1、本发明的目的在于提供一种融合知识图谱实体属性值的机器阅读理解方法及系统,以解决上述背景技术中存在的至少一项技术问题。
2、为了实现上述目的,本发明采取了如下技术方案:
3、一方面,本发明提供一种融合知识图谱实体属性值的机器阅读理解方法,包括:
4、获取知识表示向量矩阵;其中,所述知识表示向量矩阵通过双向lstm网络对知识图谱中“实体-属性-属性值”三元组中的属性和属性值一起编码并与实体编码进行相似度计算得到;
5、利用预先训练好的机器阅读理解模型,对待处理文本进行处理,得到文本的阅读理解答案;其中,预先训练好的机器阅读理解模型包括文本上下文编码网络、实体知识信息编码网络和融合输出网络;所述文本上下文编码网络用于对输入的文本整体进行编码;实体知识信息编码网络用于识别输入的文本中的实体词,利用知识表示向量矩阵对实体词进行嵌入编码;融合输出网络用于将输入文本的整体编码和对实体词的嵌入编码结合起来,并利用多层感知机结合后的编码向量进行预测输出,得到文本的机器阅读理解答案。
6、可选的,引入外部知识,通过构建“提及词-实体”字典选择相关实体,再利用过滤规则过滤无效实体,构建强相关外部知识源;利用针对“实体-属性-属性值”三元组的知识编码方法,用构建的强相关外部知识源训练得到知识表示向量矩阵。
7、其中,目标机器阅读理解数据集为非结构化文本,其中的实体词汇被称为提及词,存在一词多义的问题,歧义性较大。实体是指知识图谱中全部实体名称。同一表述的提及词根据其语义信息不同,往往会对应于知识图谱中的多个实体。“提及词-实体”字典需要分别从用于后续需训练模型的目标机器阅读理解数据集和作为外部知识源的知识图谱中获取提及词和其对应的全部实体,并对每个不同的“提及词-实体”对进行编号。经过编号后的“提及词-实体”对以结构化形式存储构成“提及词-实体”字典。
8、过滤规则综合考虑语义重要度、词性、词语常见度、词频等因素,设计了六条过滤规则:1)滤除与时间相关的实体。2)滤除词性为介词或动词的实体。3)滤除纯英文字符串。4)滤除包含中英文标点符号的实体。5)通过常用词词表(无需构建的通用词表),滤除常用名词。6)滤除在目标机器阅读理解数据集中出现频次等于一次或大于300次的实体。
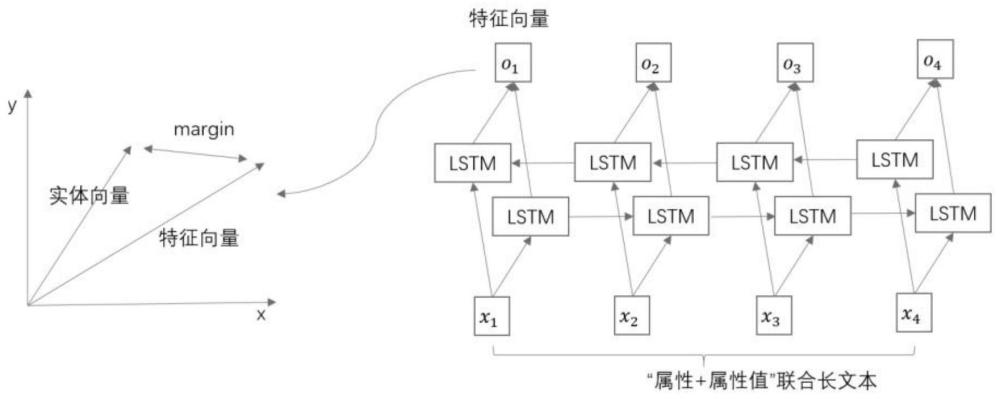
9、可选的,将“属性”和“属性值”的组合分词通过双向lstm网络后,编码成为特征向量,并且在向量表示空间中,这些特征向量要分布在实体向量的一定距离内。
10、可选的,采用正样本和负样本组成一组搭配训练lstm网络,实体知识表示向量矩阵随着训练不断更新;其中,score用来衡量三元组中“属性+属性值”与“实体”的相关性。
11、可选的,输入的知识文本分别经过词元嵌入、段嵌入和位置嵌入;段嵌入标记输入的知识文本中问题和答案的部分;将三种编码的相加和作为一组完整的编码输入到文本上下文编码网络进行编码,得到上下文特征编码;其中,所述三种编码包括文本的词元编码、段编码和位置编码;
12、输入的知识文本经过实体链接模块将文本中的实体识别出来得到实体表示序列,实体表示序列再经过知识表示向量矩阵进行实体嵌入得到实体信息编码。其中,本发明采用基于规则和字典的方式实现实体链接模块。基于上述构建的“提及词-实体”字典,对输入文本采用正向最长匹配原则,将输入文本中的实体与字典中的提及词进行匹配以实现实体链接。正向最长匹配原则,即以文本中某个下标为起点递增查词的过程中,优先输出更长的词。具体实现过程中,设置最大查询长度为8,最小查询长度为2。
13、可选的,在融合输出网络中,实体信息编码经过一个全连接网络进行线性变换使其向量维度和文本的上下文编码保持一致,得到实体知识编码;将上下文信息编码和实体知识编码相加送入两个独立的多层感知机网络,分别得到抽取的结果文本段起始和结束位置概率分布。
14、第二方面,本发明提供一种融合知识图谱实体属性值的机器阅读理解系统,包括:
15、获取模块,用于获取知识表示向量矩阵;其中,所述知识表示向量矩阵通过双向lstm网络对知识图谱中“实体-属性-属性值”三元组中的属性和属性值一起编码并与实体编码进行相似度计算得到;
16、处理模块,用于利用预先训练好的机器阅读理解模型,对待处理文本进行处理,得到文本的阅读理解答案;其中,预先训练好的机器阅读理解模型包括文本上下文编码网络、实体知识信息编码网络和融合输出网络;所述文本上下文编码网络用于对输入的文本整体进行编码;实体知识信息编码网络用于识别输入的文本中的实体词,利用知识表示向量矩阵对实体词进行嵌入编码;融合输出网络用于将输入文本的整体编码和对实体词的嵌入编码结合起来,并利用多层感知机结合后的编码向量进行预测输出,得到文本的机器阅读理解答案。
17、第三方面,本发明提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质用于存储计算机指令,所述计算机指令被处理器执行时,实现如上所述的融合知识图谱实体属性值的机器阅读理解方法。
18、第四方面,本发明提供一种计算机程序产品,包括计算机程序,所述计算机程序当在一个或多个处理器上运行时,用于实现如上所述的融合知识图谱实体属性值的机器阅读理解方法。
19、第五方面,本发明提供一种电子设备,包括:处理器、存储器以及计算机程序;其中,处理器与存储器连接,计算机程序被存储在存储器中,当电子设备运行时,所述处理器执行所述存储器存储的计算机程序,以使电子设备执行实现如上所述的融合知识图谱实体属性值的机器阅读理解方法的指令。
20、本发明有益效果:提升了在评价指标精确匹配分数(exact match,em)和f1分数(f1 score),融合了更丰富的知识信息,减少了模型参数量,降低了模型的计算复杂度。
21、本发明附加方面的优点,将在下述的描述部分中更加明显的给出,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!