一种新闻事件脉络抽取方法及系统与流程
本发明属于新闻文本处理,具体涉及一种新闻事件脉络抽取方法及系统。
背景技术:
1、随着互联网的迅速普及和信息爆炸式增长,新闻信息的数量和多样性呈现出前所未有的规模。然而,当前传统的新闻事件抽取方法存在着一系列挑战与困难。首先,基于关键词匹配或规则模板的抽取方法往往容易受到文本表达方式的影响,无法很好地适应不同语言和文体的新闻报道,从而导致抽取结果的偏差。其次,随着信息时效性的要求越来越高,传统方法往往难以快速有效地捕获最新的事件动态,它们过于依赖先验的规则或模板,无法灵活适应不断变化的新闻语境。
2、此外,传统方法也常常忽视了词语之间的关联性和上下文的重要性,造成了对事件脉络的不准确提取。在大规模新闻信息处理中,忽略了词语在文本中的重要程度,容易导致事件的遗漏或者信息的冗余。此种情况在多样性较高的新闻内容中尤为显著,比如跨领域报道或跨文化传播的情况下。
3、综上所述,传统的新闻事件抽取方法面临着诸多困难与限制。它们往往无法适应不断变化的新闻语境,缺乏灵活性和自适应性。
技术实现思路
1、发明目的:为了解决上述问题,本发明提供了一种新闻事件脉络抽取方法及系统。
2、技术方案:一种新闻事件脉络抽取方法,包括以下步骤:
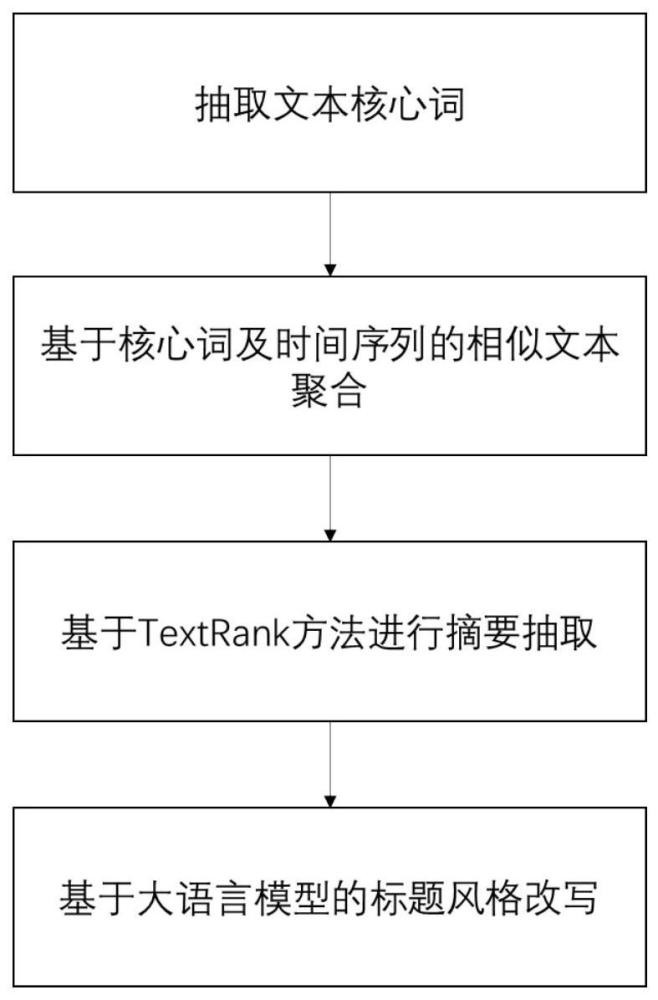
3、获取新闻事件的连续文本和发文时间,将所述连续文本拆分为离散文本;基于所述离散文本获取其中的关键词,得到关键词列表;
4、对新闻领域进行词性标定,得到词性标签;基于所述关键词、以及词性标签,筛选所述关键词列表中的核心词汇;其中,所述核心词汇至少包括:一级核心词、二级核心词;
5、对新闻事件进行合并,得到新闻集合,赋予新闻集合新的定义为类簇;利用相似判定条件,剔除类簇中相似的新闻事件;
6、对类簇中新闻事件所对应的连续文本进行分割,得到分割句;计算每个分割句的重要性得分;按照重要性得分降序的优先级顺序,筛选出n个分割句,并赋予该n个分割句新的定义为候选句;
7、基于所述词性标签,对类簇中新闻事件所对应的离散文本的词性进行统计并筛选出代表实体;赋予包含有代表实体的候选句新的定义为描述句。
8、进一步地,剔除类簇中相似的新闻事件,包括以下步骤:
9、将类簇中的新闻事件按照发文时间顺序进行排列,生成序列池;对所述序列池中的任意两个新闻事件进行判断,得到判断结果:若两个新闻事件所对应的核心词汇满足相似判定条件,则剔除其中一个新闻事件;反之,则保留两个新闻事件;
10、其中,所述相似判定条件为:两个新闻事件所对应的一级核心词完全一致,或一级核心词存在交叉且二级核心词重复数量大于阈值。
11、进一步地,所述关键词列表的获取包括以下步骤:
12、对所述离散文本中的词汇计算词频和逆文档频率;将词频和逆文档频率相乘,计算tf-idf值;
13、将所有词汇对应的tf-idf值按照降序排列,得到关键词列表;
14、其中,所述词频的计算公式为:
15、
16、所述逆文档频率的计算公式为:
17、
18、其中,k为常数。
19、进一步地,对新闻领域进行词性标定,包括以下步骤:
20、获取新闻领域中带有正确词性标签的训练数据集,每个句子中的词汇都与相应的词性标签配对;加入用于分隔句子的特殊标记;
21、将连续文本中的所有词汇映射为唯一的整数索引,并为每个词性标签分配一个唯一的整数;
22、选择bert模型作为预训练模型,载入预训练权重;修改网络结构:将bert模型的输出连接到一个全连接层,将bert的隐藏表示映射到词性标签的概率分布;
23、将数字化的训练数据输入到bert模型中,通过反向传播算法优化模型参数,预测词性标签。
24、进一步地,新闻领域相关的词性标签至少包括:人名、地名、机构名、以及时间;
25、所述一级核心词被定义为其tf-idf权重位于关键词列表中前x位,且其词性属于人名、地名、机构名、或时间中的一种;
26、所述二级核心词被定义为其tf-idf权重位于关键词列表中前y位,且其词性属于人名、地名、机构名、时间、普通名词、处所名词、作品名、或其他专名中的一种;
27、所述一级核心词优先二级核心词被定义。
28、进一步地,计算每个分割句的重要性得分,包括以下步骤:
29、对每个分割句进行相似度计算,并构建相似度矩阵;将分割句作为图的节点,相似度作为边的权重,构建无向加权图;
30、利用textrank算法计算每个分割句的重要性得分,通过迭代计算,直至收敛。
31、进一步地,筛选出代表实体,包括以下步骤:
32、筛选出词性为人名、地名、机构名、或时间的单词,根据所述单词出现次数按降序排列,每种词性下出现次数最多的单词作为该类簇的代表实体。
33、进一步地,还包括以下步骤:判断所述描述句的长度,得到判断结果:
34、若所述描述句的长度大于m个单词的句子长度,则对所述描述句进行语义角色标注,进行主成分抽取,基于所述主成分,确定新的描述句;
35、其中,所述主成分抽取为于一级核心词、二级核心词中至少确定谓词、施事者、或受事者的词汇。
36、进一步地,还包括以下步骤:判断所述描述句中结尾的标点符号,得到判断结果:若所述标点符号至少为问号、或感叹号中的其中一个,则利用大语言模型对所述描述句进行改写。
37、在另一个技术方案中,提供了一种新闻事件脉络抽取系统,用于实现如上述的一种新闻事件脉络抽取方法,所述系统包括:
38、第一模块,被设置获取新闻事件的连续文本和发文时间,将所述连续文本拆分为离散文本;基于所述离散文本获取其中的关键词,得到关键词列表;
39、第二模块,被设置对新闻领域进行词性标定,得到词性标签;基于所述关键词、以及词性标签,筛选所述关键词列表中的核心词汇;其中,所述核心词汇至少包括:一级核心词、二级核心词;
40、第三模块,被设置对新闻事件进行合并,得到新闻集合,赋予新闻集合新的定义为类簇;利用相似判定条件,剔除类簇中相似的新闻事件;
41、第四模块,被设置对类簇中新闻事件所对应的连续文本进行分割,得到分割句;计算每个分割句的重要性得分;按照重要性得分降序的优先级顺序,筛选出n个分割句,并赋予该n个分割句新的定义为候选句;
42、第五模块,被设置基于所述词性标签,对类簇中新闻事件所对应的离散文本的词性进行统计并筛选出代表实体;赋予包含有代表实体的候选句新的定义为描述句。
43、有益效果:
44、本发明通过识别新闻文本中的关键信息,实现对大批量新闻文本的聚类以及事件脉络的抽取;利用自然语言处理技术对新闻文本进行分词、词性标注等预处理,建立词语与上下文之间的关联;结合时间顺序以及每篇新闻的关键词表示对文本进行聚类,整理出事件发展的脉络,并识别出关键节点;利用大语言模型对每个类簇的标题文本进行风格改写,形成准确、完整的事件描述。
45、相较于传统方法,本方法具有较强的通用性和适应性,能够在不同语言和文本表达方式下实现高效的事件抽取,为新闻信息处理提供了一种全新的解决方案。同时,该方法还可应用于其他领域,如舆情监测、知识图谱构建等,具有广泛的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!