基于大语言模型的推理计算方法、装置、设备及存储介质与流程
本技术涉及计算机,尤其涉及一种基于大语言模型的推理计算方法、装置、设备及存储介质。
背景技术:
1、目前,随着深度学习的神经网络模型的发展,研究人员提出了用于识别语言文本的大语言模型。其中大语言模型是使用大量文本数据训练的深度学习模型,具备生成自然语言文本或理解语言文本含义的能力。具体地,大语言模型可以处理多种自然语言任务,如文本分类、问答以及对话,是当前深度学习模型领域的热点研究方向。
2、相关技术中,大语言模型会被应用至处理数学计算问题,例如企业税务计算,以实现税务管理人员的工作效率。但是在复杂计算的场景下推理过程涉及多算法共同计算,而大语言模型对多算法共同计算的数字推理能力差,导致大语言模型对推理计算的准确性低。
技术实现思路
1、本技术的主要目的在于提供一种基于大语言模型的推理计算方法、装置、设备及存储介质,旨在解决现有技术中大语言模型对推理计算的准确性低的技术问题。
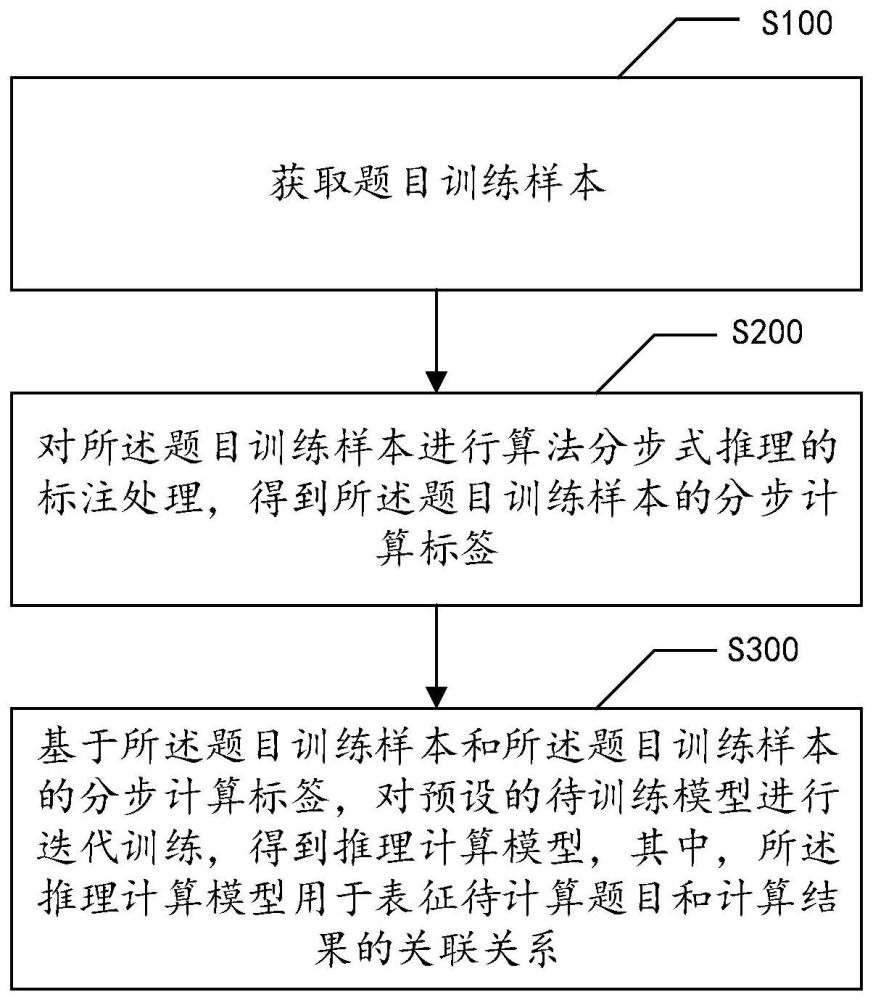
2、为实现以上目的,本技术提供一种基于大语言模型的推理计算方法,所述基于大语言模型的推理计算方法包括:
3、获取题目训练样本;
4、对所述题目训练样本进行算法分步式推理的标注处理,得到所述题目训练样本的分步计算标签;
5、基于所述题目训练样本和所述题目训练样本的分步计算标签,对预设的待训练模型进行迭代训练,得到推理计算模型,其中,所述推理计算模型用于表征待计算题目和计算结果的关联关系。
6、可选地,所述对所述题目训练样本进行算法分步式推理的标注处理,得到所述题目训练样本的分步计算标签的步骤,包括:
7、提取所述题目训练样本的特征信息;
8、基于所述特征信息,确定各分步算法和所述分步算法对应的数据变量;
9、基于所述分步算法和所述数据变量,生成所述题目训练样本的分步计算标签。
10、可选地,所述基于所述分步算法和所述数据变量,生成所述题目训练样本的分步计算标签的步骤,包括:
11、基于所述分步算法,对所述数据变量进行算法计算,得到当前推理周期的中间结果变量;
12、基于所述分步算法,对当前推理周期的中间结果变量进行算法计算,得到下一推理周期的中间结果变量,直至所述分步算法和所述数据变量计算结束,得到目标结果变量;
13、将所述分步算法、所述数据变量、中间结果变量以及目标结果变量进行记录,得到所述题目训练样本的分步计算标签。
14、可选地,所述基于所述分步算法,对所述数据变量进行算法计算,得到当前推理周期的中间结果变量的步骤之后,所述方法包括:
15、对所述中间结果变量进行标识处理,得到标识后的中间结果变量;
16、所述基于所述分步算法,对当前推理周期的中间结果变量进行算法计算,得到下一推理周期的中间结果变量,直至所述分步算法和所述数据变量计算结束,得到目标结果变量的步骤,包括:
17、基于所述分步算法,对当前推理周期的标识后的中间结果变量进行算法计算,得到下一推理周期的中间结果变量,直至所述分步算法和所述数据变量计算结束,得到目标结果变量。
18、可选地,所述基于所述分步算法,对当前推理周期的标识后的中间结果变量进行算法计算,得到下一推理周期的中间结果变量,直至所述分步算法和所述数据变量计算结束,得到目标结果变量的步骤,包括:
19、对标识后的中间结果变量进行标识信息识别,得到所述中间结果变量对应的数值信息;
20、基于所述分步算法,对所述中间结果变量对应的数值信息进行算法计算,得到下一推理周期的中间结果变量,直至所述分步算法和所述数据变量计算结束,得到目标结果变量。
21、可选地,所述基于所述特征信息,确定各分步算法和所述分步算法对应的数据变量的步骤,包括:
22、对所述特征信息进行分类处理,得到文字类别特征和数字类别特征;
23、基于预设的筛选条件,分别对所述文字类别特征和所述数字类别特征进行筛选,得到筛选后的文字类别特征和筛选后的数字类别特征;
24、分别对筛选后的文字类别特征和筛选后的数字类别特征进行识别,得到各分步算法和所述分步算法对应的数据变量。
25、可选地,所述对所述题目训练样本进行算法分步式推理的标注处理,得到所述题目训练样本的分步计算标签的步骤之后,所述方法包括:
26、获取所述题目训练样本的目标伪标注数据;
27、所述基于所述题目训练样本和所述题目训练样本的分步计算标签,对预设的待训练模型进行迭代训练,得到推理计算模型的步骤,包括:
28、基于所述题目训练样本、所述题目训练样本的分步计算标签以及所述题目训练样本的目标伪标注数据,通过半监督学习的方式,对预设的待训练模型进行迭代训练,得到推理计算模型,其中,所述推理计算模型用于表征待计算题目和计算结果的关联关系。
29、可选地,所述获取所述题目训练样本的目标伪标注数据的步骤,包括:
30、获取所述题目训练样本的初始伪标注数据;
31、对所述初始伪标注数据进行筛选,得到筛选后的目标伪标注数据。
32、可选地,所述对所述初始伪标注数据进行筛选,得到筛选后的目标伪标注数据的步骤,包括:
33、确定所述题目训练样本的分步算法和所述分步算法对应的数据变量;
34、基于所述分步算法,对所述初始伪标注数据进行反向数据变量计算,得到待验证数据;
35、将所述待验证数据与所述数据变量数值相同的伪标注数据进行保留,得到筛选后的目标伪标注数据。
36、可选地,所述基于所述题目训练样本、所述题目训练样本的分步计算标签以及所述题目训练样本的目标伪标注数据,通过半监督学习的方式,对预设的待训练模型进行迭代训练,得到推理计算模型的步骤,包括:
37、将所述题目训练样本输入至预设的待训练模型,得到预测计算结果;
38、基于所述预测计算结果与所述题目训练样本的分步计算标签以及所述题目训练样本的目标伪标注数据,采用第一损失函数,计算得到误差值;
39、判断所述误差值是否满足预设误差阈值范围指示的误差标准;
40、若所述误差结果未满足所述误差标准,则返回将所述题目训练样本输入至预设的待训练模型,得到预测计算结果的步骤,直到所述误差结果满足所述误差标准后停止训练,得到推理计算模型,其中,所述推理计算模型用于表征待计算题目和计算结果的关联关系。
41、本技术还提供一种基于大语言模型的推理计算装置,所述基于大语言模型的推理计算装置包括:
42、获取模块,用于获取题目训练样本;
43、标注模块,用于对所述题目训练样本进行算法分步式推理的标注处理,得到所述题目训练样本的分步计算标签;
44、训练模块,用于基于所述题目训练样本和所述题目训练样本的分步计算标签,对预设的待训练模型进行迭代训练,得到推理计算模型,其中,所述推理计算模型用于表征待计算题目和计算结果的关联关系。
45、可选地,所述标注模块,包括:
46、特征提取模块,用于提取所述题目训练样本的特征信息;
47、数据确定模块,用于基于所述特征信息,确定各分步算法和所述分步算法对应的数据变量;
48、生成模块,用于基于所述分步算法和所述数据变量,生成所述题目训练样本的分步计算标签。
49、可选地,所述生成模块,包括:
50、第一计算模块,用于基于所述分步算法,对所述数据变量进行算法计算,得到当前推理周期的中间结果变量;
51、第二计算模块,用于基于所述分步算法,对当前推理周期的中间结果变量进行算法计算,得到下一推理周期的中间结果变量,直至所述分步算法和所述数据变量计算结束,得到目标结果变量;
52、记录模块,用于将所述分步算法、所述数据变量、中间结果变量以及目标结果变量进行记录,得到所述题目训练样本的分步计算标签。
53、可选地,所述基于大语言模型的推理计算装置还包括:
54、标记模块,用于对所述中间结果变量进行标识处理,得到标识后的中间结果变量;
55、目标结果变量计算模块,用于基于所述分步算法,对当前推理周期的标识后的中间结果变量进行算法计算,得到下一推理周期的中间结果变量,直至所述分步算法和所述数据变量计算结束,得到目标结果变量。
56、可选地,所述目标结果变量计算模块,包括:
57、标识信息识别模块,用于对标识后的中间结果变量进行标识信息识别,得到所述中间结果变量对应的数值信息;
58、第三计算模块,基于所述分步算法,对所述中间结果变量对应的数值信息进行算法计算,得到下一推理周期的中间结果变量,直至所述分步算法和所述数据变量计算结束,得到目标结果变量。
59、可选地,所述数据确定模块,包括:
60、分类模块,用于对所述特征信息进行分类处理,得到文字类别特征和数字类别特征;
61、第一筛选模块,用于基于预设的筛选条件,分别对所述文字类别特征和所述数字类别特征进行筛选,得到筛选后的文字类别特征和筛选后的数字类别特征;
62、识别模块,用于分别对筛选后的文字类别特征和筛选后的数字类别特征进行识别,得到各分步算法和所述分步算法对应的数据变量。
63、可选地,所述基于大语言模型的推理计算装置还包括:
64、伪标注数据获取模块,用于获取所述题目训练样本的目标伪标注数据;
65、半监督训练模块,用于基于所述题目训练样本、所述题目训练样本的分步计算标签以及所述题目训练样本的目标伪标注数据,通过半监督学习的方式,对预设的待训练模型进行迭代训练,得到推理计算模型,其中,所述推理计算模型用于表征待计算题目和计算结果的关联关系。
66、可选地,所述伪标注数据获取模块,包括:
67、初始伪标注数据获取模块,用于获取所述题目训练样本的初始伪标注数据;
68、筛选模块,用于对所述初始伪标注数据进行筛选,得到筛选后的目标伪标注数据。
69、可选地,所述筛选模块,包括:
70、算法确定模块,用于确定所述题目训练样本的分步算法和所述分步算法对应的数据变量;
71、验证模块,用于基于所述分步算法,对所述初始伪标注数据进行反向数据变量计算,得到待验证数据;
72、伪标注数据筛选模块,用于将所述待验证数据与所述数据变量数值相同的伪标注数据进行保留,得到筛选后的目标伪标注数据。
73、可选地,所述半监督训练模块,包括:
74、预测模块,用于将所述题目训练样本输入至预设的待训练模型,得到预测计算结果;
75、误差计算模块,用于基于所述预测计算结果与所述题目训练样本的分步计算标签以及所述题目训练样本的目标伪标注数据,采用第一损失函数,计算得到误差值;
76、判断模块,用于判断所述误差值是否满足预设误差阈值范围指示的误差标准;
77、迭代训练模块,用于若所述误差结果未满足所述误差标准,则返回将所述题目训练样本输入至预设的待训练模型,得到预测计算结果的步骤,直到所述误差结果满足所述误差标准后停止训练,得到推理计算模型,其中,所述推理计算模型用于表征待计算题目和计算结果的关联关系。
78、本技术还提供一种基于大语言模型的推理计算设备,所述基于大语言模型的推理计算设备包括:存储器、处理器以及存储在存储器上的用于实现所述基于大语言模型的推理计算方法的程序,
79、所述存储器用于存储实现基于大语言模型的推理计算方法的程序;
80、所述处理器用于执行实现所述基于大语言模型的推理计算方法的程序,以实现所述基于大语言模型的推理计算方法的步骤。
81、本技术还提供一种存储介质,所述存储介质上存储有实现基于大语言模型的推理计算方法的程序,所述实现基于大语言模型的推理计算方法的程序被处理器执行以实现所述基于大语言模型的推理计算方法的步骤。
82、本技术通过对用于模型训练的题目训练样本进行算法分步式推理的标注处理,将复杂的大型算法计算公式拆分为多步简单的算法计算公式,以实现深度学习模型对推理计算的充分学习,提高训练完成的推理计算模型对推理计算的准确性。
- 还没有人留言评论。精彩留言会获得点赞!