一种利用样本选择进行无监督对比学习的图像理解方法
本发明属于无监督模型预训练领域,具体涉及一种利用样本选择进行无监督对比学习的图像理解方法。
背景技术:
1、无监督学习是计算机视觉领域的重要组成部分,它可以帮助计算机系统从大量未标记的数据中自动学习知识和模式。这种能力对于许多计算机视觉任务,如图像分割、图像检索、物体识别等具有重要意义。计算机视觉领域的大部分任务依赖于某种形式的数据标注信息来监督训练神经网络模型,如全监督、半监督以及弱监督的训练方法。然而,由于巨大的数据规模,对每张图像进行人为标注需要消耗极大的人力和物力。相比之下,无监督学习可以在无数据标注的情况下,学习图像特征的内在特性或规律。对比学习作为无监督学习的一种形式,通过增大类间距离、并同时减小类内距离的方式提高模型对训练图像的建模能力。自2020年何凯明团队发表里程碑式的论文momentum contrast for unsupervisedvisual representation learningm(moco)以来,对比学习理论和方法发展迅猛,涌现了如a simple framework for contrastive learning of visual representations(simclr)、exploring simple siamese representation learning(simsiam)等一系列创新性工作。
2、为学习到更好的特征表达,对比学习一般假设同类图像为正样本,不同类图像为负样本,然后根据正、负样本进行模型训练。由此可见,准确判断哪些图像对是正样本对,哪些图像对是负样本对至关重要。然而,在无监督条件下,训练数据集中的图像没有类别信息,因此无法根据类别信息判断正负样本。为了解决这个问题,传统的对比学习方法认为:任意一幅训练图像与其数据增强后的图像必定属于同一类别,因此将这对样本看成是一对正样本,而其它训练图像与这张图像属于不同类别,从而被判定为负样本对。
3、尽管这种正负样本判定方法被现有的无监督对比学习机制广泛采用,但仍然存在以下缺点:
4、(1)传统的对比学习方法使用数据增强获得正样本,并将其他图像作为负样本,这忽视了所有训练图像中可能存在某些训练图像与当前图像属于同一类别的客观事实。在这种情况下,传统方法会错误地将这些图像和当前图像判定为负样本。
5、(2)在传统正负样本对判定准则下,对比学习的损失函数定义为:
6、
7、其中q代表当前图像特征,ki,i∈{1,2,...,k}代表除q外的所有图像特征,k+为通过数据增强获得的正样本特征,τ代表温度系数。该损失函数使用q与k的点积衡量样本对的相似性,通过增强正样本对的相似性并减少负样本对的相似性,实现类内距离紧凑化和类间距离离散化。然而,在训练数据集中存在多张同类图像的情况下,该函数错误地将这些同类图像视为负样本。这导致在损失函数的优化过程中,错误地降低了它们之间的相似性,从而增加了类内距离。同时,该函数无法自适应地利用样本对间的相似性关系为它们进行重要性加权,从而无法充分利用具有可靠判断结果的样本对,并降低不可靠样本对的干扰。
技术实现思路
1、本发明针对上述现有技术存在的问题,提供一种利用样本选择进行无监督对比学习的图像理解方法,指在完全不利用任何形式标签信息的情况下训练模型对图像进行特征表达的能力。
2、为了实现上述目的,本发明采用以下技术方案:一种利用样本选择进行无监督对比学习的图像理解方法,所述方法包括:
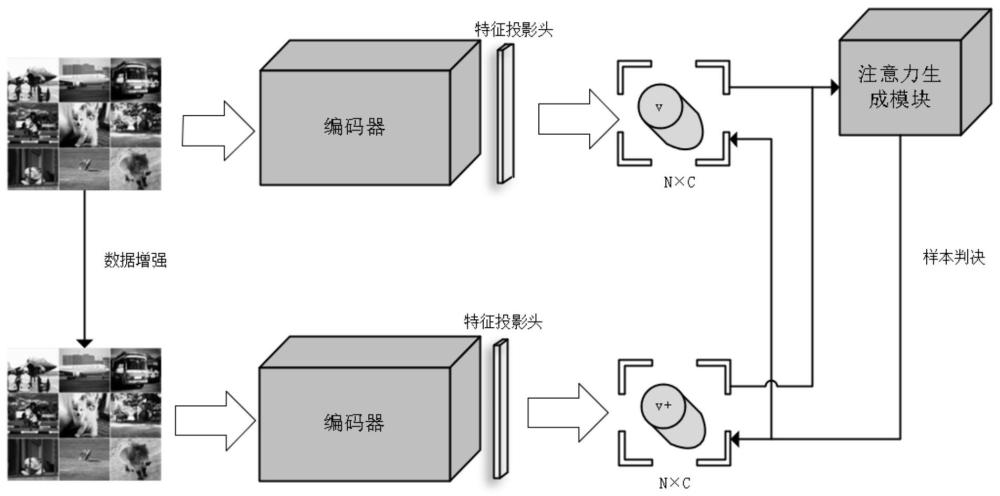
3、s1、假设共有n张训练图像xi,i∈{1,2,...,n},对所有训练图像进行数据增强,得到等数量的数据增强图像xi+,i∈{1,2,...,n};
4、s2、将原始图像和数据增强图像分别通过编码器网络进行编码,分别获得原始图像特征向量zi和数据增强图像特征向量zi+,i∈{1,2,...,n};
5、s3、编码器输出的原始图像特征向量zi和数据增强图像特征向量zi+分别通过特征投影头将特征映射至低维空间,分别生成低维度的原始图像特征向量vi和数据增强图像特征向量vi+,i∈{1,2,...,n};
6、s4、将低纬度的原始图像特征向量vi、低纬度的数据增强图像特征向量vi+输入注意力生成模块,通过注意力计算获得低纬度的原始图像特征之间以及低纬度的原始图像特征和低纬度的数据增强图像特征之间的相似度,生成相似度矩阵,即注意力图;
7、s5、根据相似度判定阈值α∈(0,1],利用注意力图对正负样本对进行判定;对于一个样本对,当θj∈(α,1]时,该样本对判定为正样本对;当θj∈(θ,α)时,判定为负样本对;当θj=0时,不参与对比损失计算;其中θj为当前样本与第j个样本之间的相似度;
8、s6、利用注意力图中的相似度信息对各个样本对进行重要性加权,对于正样本对,为其分配权重θj;对于负样本对,为其分配权重(1-θj),并计算对比损失函数,对网络进行训练,更新网络参数;
9、对比损失函数的表达式为:
10、
11、其中,q代表当前图像特征,k+为正样本特征,k-为负样本特征,ki,i∈{1,2,...,k}为除q外的所有图像特征,τ为温度系数。
12、进一步地,步骤2所述的编码器网络包括基于卷积神经网络和基于transformer的网络。
13、进一步地,步骤2所述的编码器网络为基于卷积神经网络的resnet-50架构,用于对输入图像进行特征提取、数据压缩和抽象表征学习,为后续的网络部分提供特征表达。
14、进一步地,步骤3所述的特征投影头由一个全连接层和一个relu激活层组成。
15、进一步地,步骤4中,具体步骤如下:
16、首先,对尺寸为n×c的低纬度的原始图像特征向量vi和低纬度的数据增强图像特征向量vi+进行矩阵组合,即将两个矩阵按行进行首尾相连,生成尺寸为2n×c的特征矩阵;
17、然后,利用低纬度的原始图像特征向量vi与特征矩阵进行注意力计算,得到尺寸为n×2n的相似度矩阵;
18、最后,将相似度矩阵中表示原始图像特征与其本身间的相似度元素,即前n行n列的子矩阵对角线置0,并对相似度矩阵进行以下行操作:
19、(1)softmax归一化;(2)对每个元素除以最大相似度元素,使相似度矩阵的所有元素取值范围均为[0,1]。
20、进一步地,注意力计算具体步骤如下:
21、首先,将特征矩阵进行转置;
22、然后,将低纬度的原始图像特征向量vi与转置后的特征矩阵进行矩阵点积运算,最终得到尺寸为n×2n的相似度矩阵;矩阵的点积计算公式如下:
23、
24、其中,矩阵a即低纬度原始特征向量vi的大小为m×c,矩阵b即转置后的特征矩阵的大小为c×p,则矩阵c的大小为m×p;矩阵c的元素c(x,y)是矩阵a的第x行与矩阵b的第y列对应元素的乘积之和。
25、本发明具有以下技术效果:(1)本发明设计了一种利用注意力图进行鲁棒性正负样本对选择的方案,为解决传统无监督对比学习中同类图像被错误地判断为负样本的问题提供了一种解决方案,通过注意力生成模块计算图像特征之间的相似度,得到注意力图;利用注意力图的相似度信息进行正负样本对判别,将相似度较高的样本对匹配为正样本对,进而有效避免了同类图像被误判为负样本的情况;同时,对传统的对比损失函数进行改进,新的函数可以适应同时存在多对正样本对的情况,并能自适应地为样本对分配权重,以更好地利用具有可靠判断结果的样本对,并减少不可靠样本对的干扰。
26、(2)本发明利用相似度计算,生成不同图像间的相似性图,即注意力图(attentionmap)。由于同类图像特征之间的相似度较大,可以根据注意力图中的相似度信息,将相似度较高的样本对判断为正样本对,而将相似度较低的样本对判断为负样本对,是一种可靠的正负样本选择机制。注意力图的使用在实现了无监督任务中生成伪标签(pseudo-label)的过程。
27、(3)本发明提出一种全新的无监督对比损失函数,适用于训练集中存在多张同类图像的场景;同时,利用正负样本对的相似度信息为相似度较大的正样本对、相似度较小的负样本对分配更大的权重,即为更可靠的样本对进行重要性加权处理。通过降低误判概率较大的样本对在损失函数中的权重,缓解函数优化过程中由于样本对类型判断错误而引起的类间紧凑和类内离散问题。
- 还没有人留言评论。精彩留言会获得点赞!