一种基于核PCA和KMeans算法进行金融数据异常值检测的方法与流程
本发明涉及一种金融数据异常值检测的方法,具体为一种基于核pca和kmeans算法进行金融数据异常值检测的方法。
背景技术:
1、数据清洗是指在数据挖掘过程中,对于原始数据进行筛选、去除、变换等一系列操作,以达到数据质量的提高,从而提高数据挖掘的效果。数据清洗的目的是去除数据中的噪声和不一致性,使数据更加准确、完整、可靠,以便于后续的数据分析和挖掘。在数据清洗过程中,需要对数据进行去重、缺失值处理、异常值处理、数据类型转换、数据标准化等操作。
2、异常值处理是数据清洗的一项重要工作,其主要目的是去除数据中的异常值,以避免异常值对数据挖掘结果的影响。异常值处理的主要难点在于如何准确地检测出异常值。常用的异常值检测方法包括基于统计的方法、基于聚类的方法、基于分类的方法等。
3、基于统计的方法进行异常值检测的优点是简单易行,但缺点是对数据分布的假设较为严格,对于非正态分布的数据可能会产生误判。因此,在实际应用中,需要根据具体的数据类型和应用场景来选择合适的异常值检测方法。
4、基于聚类的方法是一种常用的异常值检测方法,其主要思想是通过聚类分析来检测异常值。常用的基于聚类的方法包括k-means算法、dbscan算法等。基于聚类的方法的优点是可以发现潜在的异常值,但缺点是对于高维数据和大规模数据的处理较为困难。
5、基于分类的方法是一种常用的异常值检测方法,其主要思想是通过分类模型来检测异常值。常用的基于分类的方法包括支持向量机、决策树等。基于分类的方法的优点是可以发现潜在的异常值,但缺点是对于非线性数据的处理较为困难,为此,我们提出一种基于核pca和kmeans算法进行金融数据异常值检测的方法。
技术实现思路
1、本发明的目的在于提供一种基于核pca和kmeans算法进行金融数据异常值检测的方法,以解决背景技术中需要解决的问题。
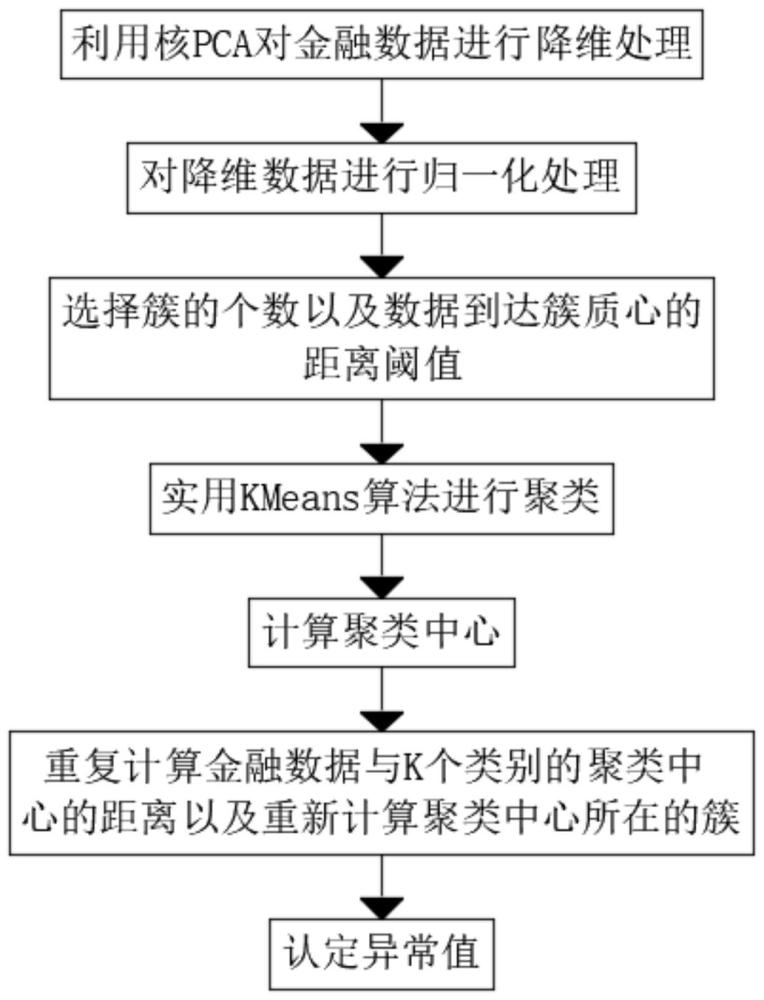
2、为实现上述目的,本发明提供如下技术方案:一种基于核pca和kmeans算法进行金融数据异常值检测的方法,所述金融数据异常值检测的方法包括以下步骤:
3、步骤一:采用主成分分析核pca对高维金融数据进行降维处理,将原始数据映射到高维空间,投影前k个主成分上,得到降维后的数据;
4、步骤二:对降维之后的数据进行归一化处理;
5、步骤三:选择簇的个数并规定异常值检测时数据到达簇质心的距离阈值;
6、步骤四:使用kmeans算法进行聚类,把数据归为k个类别,然后将n个数据样本分到k个类别中,使得每个样本到其所属类别的中心距离最小;
7、步骤五:对于需要检测的金融数据,计算金融数据与k个类别的聚类中心的距离,将金融数据归为距离最近的聚类中心所在的簇,再对于每个簇,重新计算其聚类中心;
8、步骤六:而后不断重复步骤四计算金融数据与k个类别的聚类中心的距离以及重新计算聚类中心所在的簇这两个步骤,直到目标函数的数值达到要求;
9、步骤七:最后计算每个金融数据到其所属簇的质心的距离,如果某个数据点到其所属簇的质心的距离大于某个阈值,则认为该数据点是异常值。
10、在数据清洗过程中,异常值处理是一项重要工作,其主要目的是去除数据中的异常值,以避免异常值对数据挖掘结果的影响。而异常值的检测是异常值处理的关键步骤,其主要难点在于如何准确地检测出异常值,本发明结合核pca和kmeans算法进行数据异常值检测,通过核pca对高维金融数据进行降维,再利用kmeans算法进行异常值检测,从而改善了kmeans算法在处理高维数据时时间复杂度偏高效率偏低的情况,有效地降低kmeans算法的时间复杂度,同时提高算法的准确性,从而提高了kmeans算法进行异常值处理的效果。
11、优选的,所述步骤一中核pca对高维金融数据的降维处理方法包括以下步骤:
12、a1:设定要处理的金融数据矩阵为x,其中每一列是一个样本,共有n个样本,每个样本有k个特征,利用核函数计算核矩阵k,核矩阵k的元素为k(i,j)=k(x_i,x_j),其中k是核函数,x_i和x_j是两个样本,核矩阵k反映了原始空间中样本之间的相似度;
13、a2:对核矩阵k进行中心化处理,减去行均值、列均值和总均值,中心化后的核矩阵记为k';
14、a3:对中心化后的核矩阵k'进行特征值分解,求解k'v=lambda v,其中v是特征向量,lambda是特征值。由于k'是对称半正定矩阵,选择前d个最大的特征值对应的特征向量作为主成分方向;
15、a4:将原始的金融数据映射到主成分空间中,得到降维后的数据。
16、优选的,所述a4步骤中对于任意金融数据样本x,它在第i个主成分上的投影为a_i=v_i^t k(x,x),其中v_i是第i个主成分方向,k(x,x)是一个行向量,表示x与所有样本的核函数值,将所有主成分上的投影组合起来,就得到了x在主成分空间中的坐标a=[a_1,a_2,...,a_d]^t;重复这一过程,就可以得到所有金融数据样本在主成分空间中的坐标。
17、优选的,所述步骤a1中使用的核函数包括但不限于高斯核函数、多项式核函数和线性核函数。
18、优选的,所述步骤三中阈值和簇的个数通过交叉验证确定。
19、优选的,所述步骤四中kmeans算法的聚类步骤包括以下步骤:
20、步骤b1:随机选择k个数据点作为初始的聚类中心;
21、步骤b2:对于每个数据点,计算其与k个聚类中心的距离,将其归为距离最近的聚类中心所在的簇;
22、步骤b3:对于每个簇,重新计算其聚类中心;
23、步骤b4:重复步骤b2和步骤b3,直到聚类中心不再发生变化或达到预定的迭代次数。
24、优选的,所述kmeans算法的目标函数如下所示:
25、
26、其中rik表示当样本,xi划分为簇类k时为1,否则为0,
27、rik=1,xi∈k
28、
29、uk表示簇类k的均值向量;目标函数在刻画了簇内样本围绕簇均值向量的紧密程度,j值越小则簇内样本相似度越高,k-means聚类运用em算法思想实现模型的最优化:初始化k个簇的均值向量,即uk是常数,求j最小化时的rik,当数据点划分到离该数据点最近的簇类时,目标函数j取最小;
30、已知rik,求最小化j时相应的uk,令目标函数j对uk的偏导数等于0:
31、
32、从而得出
33、其中,uk表达式的含义是簇类中心等于所属簇类样本的均值,实现了kmeans算法的参数更新。
34、与现有技术相比,本发明具有以下有益效果:
35、1、本发明结合核pca和kmeans算法进行数据异常值检测,通过核pca对高维金融数据进行降维,再利用kmeans算法进行异常值检测,从而改善了kmeans算法在处理高维数据时时间复杂度偏高效率偏低的情况,有效地降低kmeans算法的时间复杂度,同时提高算法的准确性,从而提高了kmeans算法进行异常值处理的效果;
36、2、并且采用核pca代替pca进行数据降维,核主成分分析(kpca)可以通过一个非线性映射函数将原始数据映射到一个高维特征空间,然后在特征空间上进行pca,从而能够发现数据的非线性结构;
37、3、而在kmeans算法进行异常值检测的过程中,降维可以帮助我们解决高维数据的处理问题,将高维数据转换成低维数据,从而降低算法的时间复杂度。
- 还没有人留言评论。精彩留言会获得点赞!