一种茶叶分级识别的方法
本技术涉及图像目标检测,尤其涉及茶叶分级识别的方法。
背景技术:
1、茶叶作为传统的农业特色支柱产业,其在建设特色现代农业中扮演着至关重要的角色。由于茶园地形的复杂性和多样性,在一定程度上制约了茶园的机械化与自动化。要实现智能化、精准化的茶叶采摘,首先需要解决准确识别和定位的问题。
2、目前市场上的采摘机器人使用的目标识别方法主要基于颜色、几何形状、纹理等特征进行分类、检测和分割。基于颜色特征的目标识别是通过选取适当的颜色模型,利用目标与背景区域的像素颜色特征差异来分离目标和背景。然而,传统的图像处理方法无法满足高精度和实时性的要求。此外,传统方法中使用人工设计特征来编码视觉属性,对于目标多样形态的变化鲁棒性不足,无法满足机器人精确和实时采摘的要求。
技术实现思路
1、针对目前茶叶分级识别算法计算量较大、计算速度较慢且无法准确识别茶叶嫩芽,以及无法准确分类已识别嫩芽的问题,本技术提供一种茶叶分级识别的方法,该茶叶分级识别的方法,能够通过改进后的yolov7-bw网络模型对茶叶进行分级识别,解决目前茶叶分级识别算法计算量较大、计算速度较慢且无法准确识别茶叶嫩芽,以及无法准确分类已识别嫩芽的问题,通过损失函数改进和网络结构替换有效的降低yolov7-bw网络模型的延迟、减少浮点运算的数量、提升浮点运算效率,加速收敛,提高回归精度,通过添加基于双层路由的动态稀疏注意力机制实现更加灵活的计算分配和内容感知。
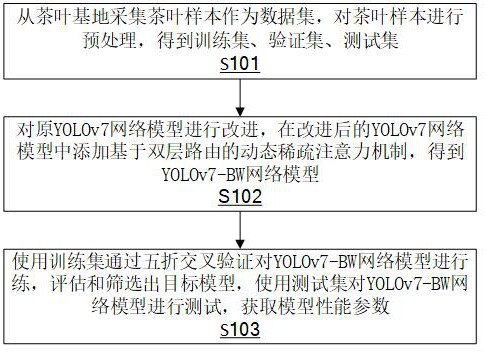
2、本技术第一方面提供一种茶叶分级识别的方法,包括:
3、从茶叶基地采集茶叶样本作为数据集,对茶叶样本进行预处理,得到训练集、验证集、测试集,其中茶叶样本为两个及以上茶叶基地不同时段、不同角度的茶叶图像;
4、在改进后的yolov7网络模型中添加基于双层路由的动态稀疏注意力机制,得到目标yolov7-bw网络模型,其中,对原yolov7网络模型进行的改进包括:对损失函数进行改进和采用部分卷积、fasternet模块对原yolov7网络模型的结构进行替换;
5、使用训练集通过五折交叉验证对yolov7-bw模型网络进行训练,评估和筛选出目标模型,使用测试集对yolov7-bw网络模型进行测试,获取模型性能参数,通过训练好的yolov7-bw网络模型进行茶叶分级检测。
6、第一方面可选的,采用部分卷积、fasternet模块对原yolov7网络模型的结构进行替换,包括:
7、将卷积部分替换为部分卷积,降低内存访问和计算的冗余;
8、在网络结构种添加逐点卷积,减少计算量;
9、采用部分卷积和逐点卷积构建特征提取层,在网络结构中插入4个特征提取层对部分网络结构进行替换;
10、在第一个特征提取层前插入一个步长为4的常规4×4卷积作为嵌入层;
11、在后三个特征提取层前插入一个步长为2的常规2×2卷积作为合并层;
12、加入全局池化层、卷积层和全连接层进行特征转换和分类。
13、第一方面可选的,在改进后的yolov7网络模型中添加基于双层路由的动态稀疏注意力机制,包括:动态稀疏注意力机制添加在yolov7网络模型颈部层的sppfcspc和第一个cbs模块后。
14、将茶叶样本图像划分为s×s个不重叠的区域,每个区域包含的特征向量为,其中h是原始图像的高度,w是原始图像的宽度。
15、对特征向量进行线性映射得到q、k、v,q、k、v表示为,
16、
17、式(5)(6)(7)中,,表示分割后的输入图像,分别表示查询、键、值的权重投影;
18、通过平均池化计算区域级特征,计算每个区域中q和k的平均值,,计算和的区域间相关性的邻接矩阵,
19、
20、式(8)中,表示相关性的邻接矩阵,表示区域级的查询,表示区域级的键,t表示转置操作;
21、进行粗粒度的区域级路由计算,采用路由索引矩阵,逐行保存前k个链接的索引,使修剪相关性图时只采用每个区域的前k个连接;
22、进行公钥规范化,聚集键和值的张量,聚集公式为,
23、
24、式(9)(10)中,表示键聚集后的张量,k表示键,表示路由索引矩阵,表示值聚集后的张量, v表示值;
25、收集散布的键值对,对于聚集后的键-值对使用的注意力操作,进行细粒度的标记到标记的注意力计算,
26、
27、式(11)中, o表示细粒度的标记到标记的注意力,表示局部上下文增强项。
28、第一方面可选的,损失函数进行改进,包括:
29、采用边界框回归损失函数替换原yolov7网络模型的目标框回归损失函数,边界框回归损失函数包括重叠和非重叠的边界框的回归、中心点距离损失、宽度和高度的偏差损失,边界框回归损失函数惩罚项公式表示为,
30、
31、式(1)(2)(3)(4)中,表示回归边界,a和b分别表示预测框与真实框,和分别表示边界框a的左上角和右下角坐标,和分别表示边界框b的左上角和右下角坐标。
32、第一方面可选的,使用训练集通过五折交叉验证对yolov7-bw网络模型进行训练,包括:
33、将训练集平均划分成五个大小相同的子集;
34、依次遍历五个子集,每次将当前子集作为验证集,其他所有子集合并作为训练集;
35、模型训练,通过外部验证集对训练完成的模型进行验证,选择平均精度值最高的模型作为最终模型。
36、第一方面可选的,对茶叶样本进行预处理,包括:
37、对不同等级的茶叶样本进行标注、对数据集中的茶叶样本图像进行亮度、对比度和锐度调节,扩充数据集。
38、第一方面可选的,对不同等级的茶叶样本进行标注,包括:
39、使用labelimg工具对不同等级的茶叶样本进行标注。
40、第一方面可选的,对数据集中的茶叶样本图像进行亮度、对比度和锐度调节,包括:
41、设置随机函数,使用所述随机函数与亮度调节类将原始图像亮度随机增强为1.1至2倍;
42、设置随机函数,使用所述随机函数与亮度调节类将原始图像亮度随机降低为0.5至0.9倍;
43、设置随机函数,使用所述随机函数和色彩饱和度调节类随机调整图像的颜色均衡;
44、设置随机函数,使用所述随机函数和对比度调节类随机调整图像的对比度;
45、设置随机函数,使用所述随机函数与锐度调节类随机调整图像的锐度;
46、将生成的图像自动添加到原始数据集中。
47、第一方面可选的,训练集、验证集、测试集包括:
48、随机选取80%的数据集茶叶样本图像作为训练集,10%的数据集茶叶样本图像作为外部验证集,10%的数据集茶叶样本图像作为测试集。
49、本技术提供的技术方案可以包括以下有益效果:
50、通过改进后的yolov7-bw网络模型对茶叶进行分级识别,解决目前茶叶分级识别算法计算量较大、计算速度较慢且无法准确识别茶叶嫩芽,以及无法准确分类已识别嫩芽的问题,通过损失函数改进和网络结构替换有效的降低yolov7-bw网络模型的延迟、减少浮点运算的数量、提升浮点运算效率,加速收敛,提高回归精度,通过添加基于双层路由的动态稀疏注意力机制实现更加灵活的计算分配和内容感知。
51、采用边界框回归损失函数替换原yolov7网络模型的损失函数,简化了计算过程,提高了模型收敛速度,使回归结果更加准确;
52、通过部分卷积和fasternet模块对原有的网络结构进行替换,减少浮点运算的数量,实现更高的每秒浮点运算效率,降低了yolov7网络模型的延迟。
53、通过基于双层路由的动态稀疏注意力机制,实现更灵活的计算分配和内容感知,解决yolov7网络模型在识别有遮挡的茶树嫩芽时的效果较差的问题。
54、通过折交叉验证对yolov7-bw网络模型进行练,进一步提升了模型在不同数据分布下的泛化能力,提高模型的可靠性和鲁棒性。
55、且本技术通过引入亮度增强、亮度减弱、颜色均衡调节、对比度进行样本预处理,生成更多的样本,使模型更好地学习到各级茶叶的特征,提高模型的泛化能力,增加模型的鲁棒性,更好地适应各种场景和环境的变化,有效减少过拟合的风险,提高模型在实际应用中的性能和稳定性。
56、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!