基于一致扩散的场景级多智能体轨迹生成方法及装置与流程
本技术涉及自动驾驶,具体涉及一种基于一致扩散的场景级多智能体轨迹生成方法及装置。
背景技术:
1、真实的场景级多智能体运动仿真对于开发和评估自动驾驶算法至关重要。交通仿真作为现实世界记录的交通场景的补充,提供了一种经济、安全的方法以在自动驾驶系统部署到现实世界之前对其进行评估。然而,智能体类型存在多样性(包括车辆、行人、自行车等),且多种类型的智能体之间存在复杂的相互作用;并且智能体运动具有不确定、多模态性质的问题,因此,此类场景的生成并不简单。
2、现有的技术方案中,通过定义智能体的运动规则来生出轨迹的解决方案,难以提供复杂、真实的交通场景。
3、利用运动预测任务的成果来生成多模态交通场景,大多为单一类型轨迹生成方法,不能简单直接拓展到场景级多智能体轨迹生成,因其无法处理多种类型智能体的生成轨迹间的不同交互及一致性。例如,将车辆的驾驶过程建模为马尔可夫过程,并利用深度神经网络实现状态分布和转移函数。利用多上下文门控模块来处理观测数据中的交互,并利用高斯混合模型来刻画生成轨迹的多样性。采用门控循环单元(gated recurrent unit,gru)和卷积神经网络(convolutional neural networks,cnn)从现实世界数据中学习多智能体行为,并使用隐变量模型制定智能体的联合运动策略。引入碰撞缓解策略来改进运动预测模型生成的轨迹。
4、利用生成模型来学习轨迹数据的概率分布并生成新的轨迹样本,最近的工作开始使用基于扩散模型的方法,如一种相关的技术中基于扩散模型的框架来实现行人轨迹预测,其中的场景扩散利用端到端可微架构中的潜在扩散来为智能体生成位置序列。一些相关的技术中还提出了一种条件扩散模型来实现可控的车辆轨迹生成,使得生成的轨迹具有所需的属性,例如速度限制。但这些基于扩散模型的方法仅考虑单一类型智能体的轨迹生成,并且无法保证生成轨迹像真实世界中的智能体轨迹一样的局部平滑特性,进而易产生不真实的智能体运动轨迹。
技术实现思路
1、本技术实施例提供了一种基于一致扩散的场景级多智能体轨迹生成方法,以解决现有技术中,无法处理多种类型智能体的生成轨迹间的交互及一致性,以及无法保证生成轨迹像真实世界中的智能体轨迹一样的局部平滑特性,进而易产生不真实的智能体运动轨迹的问题。
2、相应的,本技术实施例还提供了一种基于一致扩散的场景级多智能体轨迹生成装置、一种电子设备,用于保证上述方法的实现及应用。
3、为了解决上述技术问题,本技术实施例公开了一种基于一致扩散的场景级多智能体轨迹生成方法,所述方法包括:
4、在训练阶段:
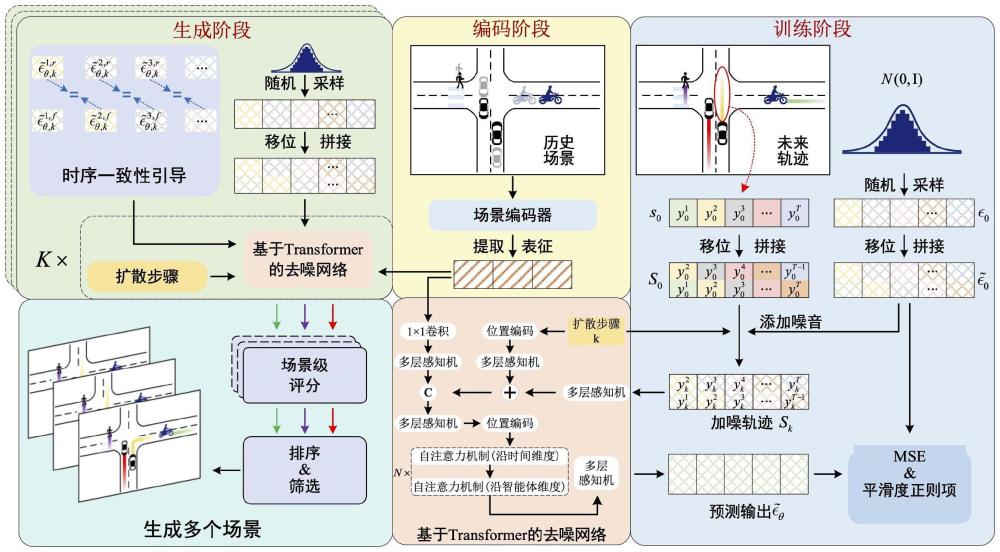
5、对预设训练集中真实的未来轨迹序列进行移位和拼接处理,获得增强轨迹序列;
6、对从高斯分布中采样获得的噪声序列进行移位和拼接处理,获得增强噪声序列,并将增强噪声序列依照高斯转移添加到增强轨迹序列,获得增强加噪轨迹序列;
7、利用场景编码器提取训练集中智能体的历史轨迹与上下文信息得到智能体的向量表征,并将智能体的向量表征、增强加噪轨迹序列和扩散步骤输入基于transformer的去噪网络,以通过高斯状态转移逐步预测所添加噪声来得到未来轨迹;
8、利用预设的损失函数优化场景编码器和去噪网络;
9、在生成阶段:
10、将从高斯分布中采样获得的噪声序列进行移位和拼接处理,获得增强加噪轨迹序列;
11、利用优化后的场景编码器提取目标历史场景中智能体的历史轨迹与上下文信息得到智能体的向量表征,并将智能体的向量表征、增强加噪轨迹序列和扩散步骤输入优化后的去噪网络,输出获得多个智能体的联合未来轨迹;
12、其中,在生成阶段,去噪网络在逐步高斯状态转移过程中通过时序一致性引导确保增强加噪轨迹序列中同一状态的信息一致。
13、本技术实施例还公开了一种一致扩散的场景级多智能体轨迹生成装置,所述装置包括训练模块和生成模块;
14、训练模块包括:
15、轨迹增强模块,用于对预设训练集中真实的未来轨迹序列进行移位和拼接处理,获得增强轨迹序列;
16、加噪模块,用于对从高斯分布中采样获得的噪声序列进行移位和拼接处理,获得增强噪声序列,并将增强噪声序列依照高斯转移添加到增强轨迹序列,获得增强加噪轨迹序列;
17、去噪模块,用于利用场景编码器提取训练集中智能体的历史轨迹与上下文信息得到智能体的向量表征,并将智能体的向量表征、增强加噪轨迹序列和扩散步骤输入基于transformer的去噪网络,以通过高斯状态转移逐步预测所添加噪声来得到未来轨迹;
18、优化模块,用于利用预设的损失函数优化场景编码器和去噪网络;
19、生成模块包括:
20、噪声序列采集模块,用于将从高斯分布中采样获得的噪声序列进行移位和拼接处理,获得增强加噪轨迹序列;
21、轨迹预测模块,用于利用优化后的场景编码器提取目标历史场景中智能体的历史轨迹与上下文信息得到智能体的向量表征,并将智能体的向量表征、增强加噪轨迹序列和扩散步骤输入优化后的去噪网络,输出获得多个智能体的联合未来轨迹;
22、其中,在生成模块,去噪网络在逐步高斯状态转移过程中通过时序一致性引导确保增强加噪轨迹序列中同一状态的信息一致。
23、本技术实施例还公开了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时实现本技术实施例中一个或多个所述的方法。
24、本技术实施例中,在训练阶段,对预设训练集中真实的未来轨迹序列进行移位和拼接处理,获得增强轨迹序列,使得增强轨迹序列中的相邻元素之间存在部分重叠。然后采用相同的方法对从高斯分布中采样获得的噪声序列进行移位和拼接处理,获得增强噪声序列,并将增强噪声序列依照高斯转移添加到增强轨迹序列,以使得增轨迹强序列中相邻元素重叠的部分被加以相同的噪声,通过上述构造增强轨迹序列和特定的加噪方式可以提升扩散模型中生成的智能体轨迹的平滑性。然后利用场景编码器提取训练集中智能体的历史轨迹与上下文信息得到智能体的向量表征,并将智能体的向量表征、增强加噪轨迹序列和扩散步骤输入基于transformer的去噪网络,以通过高斯状态转移逐步预测所添加噪声来得到未来轨迹;并利用预设的损失函数优化场景编码器和去噪网络。在生成阶段,直接将从高斯分布中采样获得的噪声序列进行移位和拼接处理,获得增强加噪轨迹序列,然后将场景编码器提取到的智能体的向量表征、增强加噪轨迹序列和扩散步骤输入优化后的去噪网络,可以输出获得多个智能体的联合未来轨迹,确保场景一致性。其中,在生成阶段,去噪网络在逐步高斯状态转移过程中通过时序一致性引导确保增强加噪轨迹序列中同一状态的信息一致,确保去噪过程中的时序一致性,以提升生成的联合未来轨迹的局部平滑度。
25、本技术实施例附加的方面和优点将在下面的描述部分中给出,这些将从下面的描述中变得明显,或通过本技术的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!