基于数据分类的多因素延续性实时数据预测方法及装置与流程
本发明属于计算机,特别是涉及到一种基于数据分类的多因素延续性实时数据预测方法及装置。
背景技术:
1、数据预测,始终要求的是更高和更稳定的准确率,但是某些数据由于自身具有的特性,如关联相关因素多、数据本身存在延续性、会出现偶发的突变性等等,可能会导致预测时出现不满足即时性要求、难预测等情况。以日前电价数据的预测为例:电价数据与区域及全省的资源、市场负荷等多种要素息息相关;而由于市场变化、气候变化和用户行为的连续性,电价的变化也是延续的;由于极端天气、节假日用电情况不稳定或其他因素等都会引起供需的突变,因而会导致电价突变;这些都会引起电价的预测难以及不容易满足即时性要求的问题。
2、究其原因,主要在于以下几个方面:
3、1)数据质量问题:由于关联相关因素多,预测需要依赖大量数据来计算,其中数据的准确性、完整性、稳定性等严重影响预测结果;同时,有些数据可能已经过时或不准确,因此需要进行数据清洗和处理。
4、2)非线性问题:由于存在多因素延续性,数据预测模型需要考虑这些延续性因素才能实现更加准确地预测。
5、3)预测时间分辨率问题:延续性和突变性的存在,使得数据预测的时间分辨率要求很高,高分辨率的预测需要使用复杂的算法和模型,同时需要更多的数据和计算资源。
6、4)实时性问题:数据的实时预测存在于很多重要应用场景,需要对实时数据进行快速处理和分析,实时更新模型。如果预测结果延迟,可能会导致损失,因此实时性是非常关键的。
7、现有技术中的预测方法,倾向于运用单一模型:比如arima、bp神经网络等,这些模型通常只能考虑到单一的因素;缺乏实时反馈机制,缺少对特殊数据的处理;因此很难解决上述问题。
技术实现思路
1、本发明提出一种基于数据分类的多因素延续性实时数据预测方法及装置,主要解决数据突变性和数据预测的迟钝性,提高数据预测的精度和准确率。
2、为达到上述目的,本发明的技术方案是这样实现的:
3、一种基于数据分类的多因素延续性实时数据预测方法,包括:
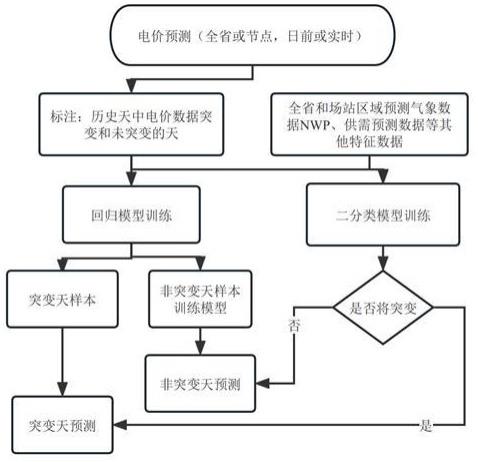
4、s1、对于待预测数据的历史数据根据离散程度定义突变天,进行标注;所述标注是在数据中增加表示“是否突变”的二值变量;
5、s2、获取用于预测的相关数据的历史数据,并进行常规数据处理;
6、s3、依据步骤s1中标注的突变天,对相关数据的历史数据分类,分成非突变天数据组和突变天数据组;对于非突变天数据组,采用lasso线性模型进行训练,得到待预测数据的非突变天预测模型;对于突变天数据组,采用随机森林回归算法进行训练,得到待预测数据的突变天预测模型;
7、s4、将步骤s1中增加的“是否突变”的二值变量作为目标变量,所述相关数据的历史数据作为特征,并对所有特征归一化处理后,利用逻辑回归算法进行二分类模型的建模;并使其调和均值最高;
8、s5、将预测日的相关数据输入所述二分类模型判断预测日是否为突变天,并根据判断结果,选择非突变天预测模型或突变天预测模型进行待预测数据的预测。
9、进一步的,步骤s1的具体方法包括:
10、使用变异系数描述待预测数据的历史数据每日的离散程度,设置阈值,大于阈值定义为突变天,小于阈值定义为非突变天,在数据中增加表示“是否突变”的二值变量;
11、所述变异系数的公式为:;其中cv为变异系数,σ为标准差,μ为平均值。
12、进一步的,步骤s2所述常规数据处理包括:异常值处理、缺失值处理、非平衡数据处理。
13、进一步的,步骤s4所述调和均值计算方法为:
14、;
15、其中f1表示调和均值, precision表示精确率, recall表示召回率;精确率和召回率的计算方式如下:
16、;
17、;
18、其中,tp为真正例,fp为假正例,fn为假负例。
19、本发明另一方面还提出了一种基于数据分类的多因素延续性实时数据预测装置,包括:
20、标注模块:对待于预测数据的历史数据根据离散程度定义突变天,进行标注;所述标注是在数据中增加表示“是否突变”的二值变量;
21、处理模块:获取用于预测的相关数据的历史数据,并进行常规数据处理;
22、预测模型模块:依据步骤s1中标注的突变天,对相关数据的历史数据分类,分成非突变天数据组和突变天数据组;对于非突变天数据组,采用lasso线性模型进行训练,得到待预测数据的非突变天预测模型;对于突变天数据组,采用随机森林回归算法进行训练,得到待预测数据的突变天预测模型;
23、二分类模型模块:将步骤s1中增加的“是否突变”的二值变量作为目标变量,所述相关数据的历史数据作为特征,并对所有特征归一化处理后,利用逻辑回归算法进行二分类模型的建模;并使其调和均值最高;
24、预测模块、将预测日的相关数据输入所述二分类模型判断预测日是否为突变天,并根据判断结果,选择非突变天预测模型或突变天预测模型进行待预测数据的预测。
25、进一步的,所述标注模块包括:
26、变异系数单元:使用变异系数描述待预测数据的历史数据每日的离散程度,设置阈值,大于阈值定义为突变天,小于阈值定义为非突变天,在数据中增加表示“是否突变”的二值变量;所述变异系数的公式为:;其中cv为变异系数,σ为标准差,μ为平均值。
27、进一步的,所述处理模块包括:异常值处理、缺失值处理、非平衡数据处理。
28、进一步的,所述二分类模型模块包括调和均值单元,计算调和均值:
29、;
30、其中f1表示调和均值, precision表示精确率, recall表示召回率;
31、;
32、;
33、其中,tp为真正例,fp为假正例,fn为假负例。
34、与现有技术相比,本发明具有如下的有益效果:
35、1、本发明针对历史数据按天作为分辨率定义突变,再进行分类模型训练,此方法能够首先对预测日进行判断是否突变,然后对训练数据进行区分,能够大大减少突变数据对非突变天的影响,也可以提高突变天的预测精度;
36、2、本发明在突变天模型训练前,根据某特征对样本进行不同程度的加强,可使突变点预测到的概率增大;
37、3、本发明解决数据突变性和数据预测的迟钝性,提高数据预测的精度和准确率。
技术特征:
1.一种基于数据分类的多因素延续性实时数据预测方法,其特征在于,包括:
2.根据权利要求1所述的基于数据分类的多因素延续性实时数据预测方法,其特征在于,步骤s1的具体方法包括:
3.根据权利要求1所述的基于数据分类的多因素延续性实时数据预测方法,其特征在于,步骤s2所述常规数据处理包括:异常值处理、缺失值处理、非平衡数据处理。
4.根据权利要求1所述的基于数据分类的多因素延续性实时数据预测方法,其特征在于,步骤s4所述调和均值计算方法为:
5.一种基于数据分类的多因素延续性实时数据预测装置,其特征在于,包括:
6.根据权利要求5所述的基于数据分类的多因素延续性实时数据预测装置,其特征在于,所述标注模块包括:
7.根据权利要求5所述的基于数据分类的多因素延续性实时数据预测装置,其特征在于,所述处理模块包括:异常值处理、缺失值处理、非平衡数据处理。
8.根据权利要求5所述的基于数据分类的多因素延续性实时数据预测装置,其特征在于,所述二分类模型模块包括调和均值单元,计算调和均值:
技术总结
本发明提出一种基于数据分类的多因素延续性实时数据预测方法及装置,对于待预测数据的历史数据根据离散程度定义突变天,进行标注;获取用于预测的相关数据的历史数据,并进行常规数据处理;依据步骤S1中标注的突变天,对相关数据的历史数据分类,分成非突变天数据组和突变天数据组;分别建立预测模型;利用逻辑回归算法进行二分类模型的建模;并使其调和均值最高;将预测日的相关数据输入所述二分类模型判断预测日是否为突变天,并根据判断结果,选择非突变天预测模型或突变天预测模型进行待预测数据的预测。本发明主要解决数据突变性和数据预测的迟钝性,提高数据预测的精度和准确率。
技术研发人员:向婕,廖云涛,付越
受保护的技术使用者:国能日新科技股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!