一种基于元学习的跨域小样本CT图像语义分割系统及方法与流程
本发明涉及领域,尤其涉及一种基于元学习的跨域小样本ct图像语义分割系统及方法。
背景技术:
1、医学图像分析在现代医疗诊断中起着重要作用,其中ct(computed tomography,电子计算机断层扫描)医学图像的语义分割对于解剖结构和病变的准确定位具有关键意义。然而,由于医学影像数据属于临床医学资源,具有稀缺性和难以获取的特性,以及ct医学图像数据在同域和跨域情况下的分布差异,传统的深度学习方法在小样本场景下可能出现过拟合或泛化能力不足的问题。
2、近年来,元学习作为一种新兴的机器学习范式,引起了广泛关注。元学习旨在通过在不同任务上进行训练,使得模型能够更快速地适应新任务。元学习方法特别在解决小样本问题方面表现出色。具体而言,元学习包含元训练阶段和元测试阶段两个关键步骤。在元训练阶段,模型通过学习众多小样本任务,获得处理此类任务的通用能力。随后,在元测试阶段,模型能够利用这种能力以应对新的小样本任务。
3、然而,元训练阶段需要大量和元测试阶段数据同域的带标注样本来构建小样本训练任务。但在医学图像领域,尤其是ct医学图像语义分割领域,获取足够的带标注数据却相当困难。这是因为ct医学图像的获取不仅需要医学专家的参与,还涉及到罕见病例和病人隐私的保护。因此,目前如何实现在小样本ct医学图像语义分割领域应用元学习方法是当前亟待解决的技术问题。
技术实现思路
1、为了克服现有技术中相关产品的不足,本发明提出一种基于元学习的跨域小样本ct图像语义分割系统及方法。
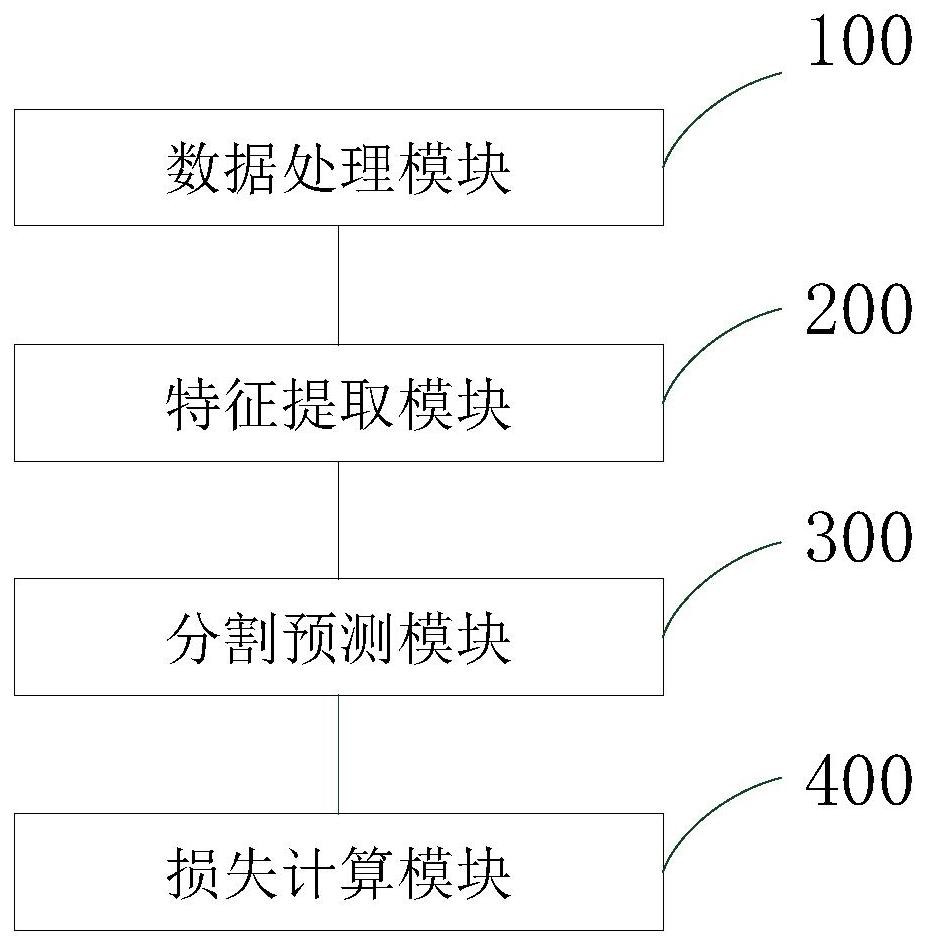
2、本发明提供了一种基于元学习的跨域小样本ct图像语义分割系统,包括:
3、数据处理模块:从带标注的源域图片数据中采样,组合为小样本分割任务集合,以及从目标域采样无标注图片作为训练数据;
4、特征提取模块:使用卷积神经网络获得源域图片数据的中层特征和原型特征,使用卷积神经网络获得目标域中图片的中层特征;
5、分割预测模块:利用余弦相似度计算小样本分割任务的分割结果;
6、损失计算模块:利用分割结果和真实标注数据计算分割损失,利用最大均值差异算法计算源域特征和目标域特征之间的差异损失进行域对齐,计算加权损失并优化模型。
7、在本发明的某些实施方式中,所述数据处理模块具体用于:
8、从带标注的源域图片数据中采样,组合为小样本分割任务集合,作为元训练的模型输入,在源域完成小样本分割任务;用于元训练的小样本分割任务为:其中,c表示小样本分割任务集合,n表示采样的小样本分割任务数量,s表示支持集,q表示查询集,支持集s中还包括k张带标注m的样本,即查询集q中包括查询图片xq和用来在训练时计算损失的标注mq;
9、从目标域采样部分无标注图片数据,添加到对应的每个小样本任务中,所述无标注图片数据用于进行数据域的对齐,即此时:ti表示添加到第i个小样本分割任务中的无标注图片数据。
10、在本发明的某些实施方式中,所述特征提取模块具体用于:
11、获得源域图片数据的中层特征,其公式分别为:
12、fs=e(xs),fq=e(xq),ft=e(xt),
13、目标域图片数据为xt,再通过标签全局平均池化来分别提取目标类别原型以及背景类别原型,其中提取目标类别原型时i取1,提取背景类别原型时i取0,则其公式为:
14、
15、式中,p表示原型特征,x和y分别表示空间坐标,函数δ为指示函数,当参数为真时取1,否则取0;若有多个支持集样本,则计算多次原型,再求平均原型。
16、在本发明的某些实施方式中,所述分割预测模块具体用于:
17、通过有参或无参的度量工具完成原型特征p和图片特征f_q的度量分割,基于无参的度量工具采用余弦相似度来度量原型特征和图片特征的相似度,然后完成分割,先计算前景原型特征和背景原型特征分别与图片特征的余弦相似度为:
18、
19、式中,pred表示相似度值,α为调节乘子;
20、通过argmax函数得到分割结果,其公式为:
21、
22、在本发明的某些实施方式中,所述损失计算模块具体用于:
23、监督源域的小样本分割任务,其损失计算基于交叉熵损失函数,具体为:
24、
25、式中,中层特征fq∈rc×h×w,中层特征ft∈rc×h×w,c为通道数,h,w分别为特征图的高和宽;
26、将中层特征fq,ft,分别变换维度为:fq∈rhw×c,ft∈rhw×c;再从中层特征fq,ft中分别抽取m和n个通道特征向量作为数据域样本,分别得到公式:
27、
28、
29、再利用抽取的通道特征向量和最大均值差异算法来计算对齐损失为:
30、其中,k代表高斯核函数计算得到的核矩阵;
31、终的加权总损失计算为:
32、l=lseg+βlmmd,其中β为乘子。
33、本发明还提供一种基于元学习的跨域小样本ct图像语义分割方法,应用于上述任一项的基于元学习的跨域小样本ct图像语义分割系统,包括如下步骤:
34、步骤s1:从带标注的源域图片数据中采样,组合为小样本分割任务集合,以及从目标域采样无标注图片作为训练数据;
35、步骤s2:使用卷积神经网络获得源域图片数据的中层特征和原型特征,使用卷积神经网络获得目标域中图片的中层特征;
36、步骤s3:利用余弦相似度计算小样本分割任务的分割结果;
37、步骤s4:利用分割结果和真实标注数据计算分割损失,利用最大均值差异算法计算源域特征和目标域特征之间的差异损失进行域对齐,计算加权损失并优化模型。
38、在本发明的某些实施方式中,步骤s1具体包括:
39、从带标注的源域图片数据中采样,组合为小样本分割任务集合,作为元训练的模型输入,在源域完成小样本分割任务;用于元训练的小样本分割任务为:其中,c表示小样本分割任务集合,n表示采样的小样本分割任务数量,s表示支持集,q表示查询集,支持集s中还包括k张带标注m的样本,即查询集q中包括查询图片xq和用来在训练时计算损失的标注mq;
40、从目标域采样部分无标注图片数据,添加到对应的每个小样本任务中,所述无标注图片数据用于进行数据域的对齐,即此时:ti表示添加到第i个小样本分割任务中的无标注图片数据。
41、在本发明的某些实施方式中,步骤s2具体包括:
42、获得源域图片数据的中层特征,其公式分别为:
43、fs=e(xs),fq=e(xq),ft=e(xt),
44、目标域图片数据为xt,再通过标签全局平均池化来分别提取目标类别原型以及背景类别原型,其中提取目标类别原型时i取1,提取背景类别原型时i取0,则其公式为:
45、
46、式中,p表示原型特征,x和y分别表示空间坐标,函数δ为指示函数,当参数为真时取1,否则取0;若有多个支持集样本,则计算多次原型,再求平均原型。
47、在本发明的某些实施方式中,步骤s3具体包括:
48、通过有参或无参的度量工具完成原型特征p和图片特征f_q的度量分割,基于无参的度量工具采用余弦相似度来度量原型特征和图片特征的相似度,然后完成分割,先计算前景原型特征和背景原型特征分别与图片特征的余弦相似度为:
49、
50、式中,pred表示相似度值,α为调节乘子;
51、通过argmax函数得到分割结果,其公式为:
52、
53、在本发明的某些实施方式中,步骤s4具体包括:
54、监督源域的小样本分割任务,其损失计算基于交叉熵损失函数,具体为:
55、
56、式中,中层特征fq∈rc×h×w,中层特征ft∈rc×h×w,c为通道数,h,w分别为特征图的高和宽;
57、将中层特征fq,ft,分别变换维度为:fq∈rhw×c,ft∈rhw×c;再从中层特征fq,ft中分别抽取m和n个通道特征向量作为数据域样本,分别得到公式:
58、
59、
60、再利用抽取的通道特征向量和最大均值差异算法来计算对齐损失为:
61、其中,k代表高斯核函数计算得到的核矩阵;
62、终的加权总损失计算为:
63、l=lseg+βlmmd,其中β为乘子。
64、与现有技术相比,本发明有以下优点:
65、本发明实施例所述基于元学习的跨域小样本ct图像语义分割系统相较于现有技术,通过元学习算法用来实现在源域上的小样本分割任务,最大均值差异算法用来将源域和ct图像域跨域对齐;在进行跨域对齐时,基于骨干网络输出的中层特征,随机抽取源域和目标域中层特征的通道向量,使用最大均值差异算法来进行跨域的对齐;在完成在源域的小样本分割任务时,设计了一个骨干网络,使用中层特征作为骨干网络的输出,使用原型替代三维特征进行度量操作;使用无参的余弦相似度函数进行特征的分割,在源域训练的小样本分割模型被迁移到目标域测试时,模型的预测性能不会大幅度下降,从而解决带标注的ct医学图像数量在源域不足以支持元训练的问题,可以在医疗领域中提供ct图像语义分割数据,快速定位目标区域,以支持更精准的疾病诊断和治疗决策,具有较好的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!