一种基于连续特征群的点击率预测方法与流程
本发明为金融场景下的点击率预测方法创新,重点在于对连续特征群数据集的特征交互处理方法。
背景技术:
1、工业推荐系统主要分为召回和排序两个经典步骤。首先在召回阶段根据用户的兴趣和历史行为,从包含海量物品的数据仓库里,定位到小部分用户潜在感兴趣的物品。排序阶段需要融入大量用户端的特征、物品端的特征,使用较为复杂的模型,对召回阶段输出的物品集合进行排序,为用户做精准的个性化推荐。排序模型融入特征不仅需要考虑单独每一个特征,更需要考虑特征之间的交互信息。特征交互也叫特征组合,通过将两个或多个特征组合起来进行数学计算,实现对样本空间的非线性变换,增加模型的非线性能力,以达到对于不同的特征组合都能进行有效预测的目标。特征交互的方法一般包含枚举法、非深度特征交互和深度特征交互。现有的方法有以下缺点:
2、1.在处理连续型特征群的数据集时,autoint算法可能会面临一些挑战。由于连续型特征的连续性质,它们通常不能直接用于特征交互,因此autoint可能无法从这些特征中充分提取有用的交互信息来进行有效的客户分类。在这种情况下,autoint算法可能更多地依赖于其深度神经网络部分来提取潜在的信息,以尽可能地利用数据中的有用信息。然而,这种方法可能无法充分发挥autoint算法的核心优势,即高阶特征交互能力。
3、2.现有传统机器学习算法的特征提取能力有限,可能无法充分发掘数据中的有效特征,从而影响模型的训练效果。传统机器学习算法在处理特征之间的复杂交互时,往往难以准确捕捉和建模。传统机器学习算法对数据的质量和规模要求较高,如果数据存在缺失、异常值或数据量不足。传统机器学习算法的参数和超参数的选择对模型的性能影响较大,需要进行精细的调整和优化。
技术实现思路
1、本发明为了提升金融场景下的营销与风控预测准确率,提出了一种将金融数据集连续特征群应用于特征交互的点击率预测方法。可以有效解决背景技术中的问题。
2、为实现上述目的,本发明采取的技术方案为:
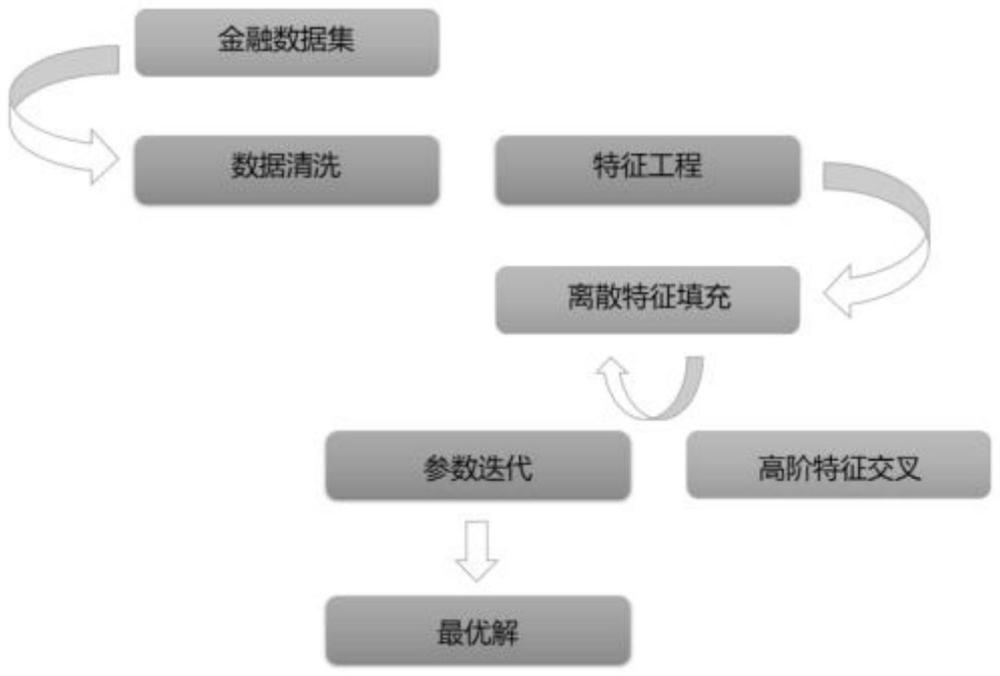
3、一种基于连续特征群的点击率预测方法,该方法针对金融行业数据集的连续特征群,通过自动选择部分连续型特征进行分箱,将连续特征转化为离散特征,以增强特征交互的效果,提高点击率预测模型的性能,该方法首先对金融行业数据集进行数据预处理,包括缺失值填充、异常值剔除和数据标准化等步骤,以确保数据的完整性和一致性。然后,通过自定义的特征分箱数量及模型参数的自动化迭代模块,对预处理后的数据进行特征衍生,得到离散特征群。这些离散特征群与原始连续特征群一起作为输入,输入至点击率预测模型进行训练,该方法可以在训练过程中自动调整模型参数和特征分箱数量,以得到最佳的模型性能。这种方法能够提高模型的预测精度和泛化能力,同时降低模型过拟合的风险,包含以下步骤:
4、步骤s1:金融数据集的数据清洗与缺失值填充;
5、步骤s2:特征标准化与标签编码;
6、步骤s3:最优分箱特征数量及模型参数迭代;
7、步骤s4:基线方法性能对比;
8、所述步骤s1在数据清洗阶段,我们首先对缺失值进行处理。对于那些缺失值率大于90%的特征,我们选择剔除它们。为了填补这些缺失值,我们采用了中位数填充的方法。此外,我们还识别并去除了那些方差过高的离群值,这些值可能代表着数据集中的异常值。为了使数据集中的数值具有可比性,我们采用了min-max标准化(也称为归一化)的策略。这种策略对每个属性进行操作,设定属性a的最小值和最大值分别为mina和maxa。然后,我们将属性a的一个原始值x通过min-max标准化映射到区间[0,1]中。公式如下:
9、新数据=(原数据-最小值)/(最大值-最小值)
10、通过这样的处理,我们可以确保数据集中的数值都在一个统一的范围内,便于后续的数据分析和建模。
11、在步骤s2中,我们进行了特征标准化和标签编码。对于那些最大值和最小值不明确的连续性特征,我们采用了z-score标准化的方法。这种方法是基于原始数据的均值和标准差来进行数据规范化的。具体来说,我们将属性a的原始值x通过z-score标准化映射到新的值x'。在进行z-score标准化时,我们使用以下公式:
12、新数据=(原数据-均值)/标准差。
13、这种标准化方法非常适合于那些最大值和最小值未知,或者存在超出取值范围的离群数据的情况。通过这种方法,我们可以确保不同特征之间的数值具有可比性,同时也能保留数据的原有分布。
14、所述步骤s3最优分箱特征数量及模型参数迭代是在模型选择上,使用autoint利用带残差连接的多头自注意力机制显式的进行交互特征的获取,能够自动学习高阶特征交叉。核心部分是interacting layer,将输入的张量e∈rd转换为wqurey、wkey、wvalue,对于第h个attention head,当第m个嵌入向量em作为query时,其对应输出为:
15、
16、
17、
18、其中,为可自定义的相似度计算函数,本文的方法选择向量内积的计算方式,对于em,拼接它的h个attention head的输出,使用标准残差连接,得到最终输出通过自注意力的方式计算每个特征与其他特征的相似度,加权求和得到新特征。模型也包含多个注意力层以构造更高阶的组合特征,隐藏层部分利用embedding层+mlp层组成深度神经网络(dnn)来隐式地建模特征交互的高阶关系,来解决显式特征交互带来的问题。将高维离散特征转换为固定长度的连续特征,然后通过多个全连接层(fully connected),最后通过一个激活函数得到点击的概率,特征工程部分,金融数据集包含m个离散型特征和n个连续型特征,对于n个连续型特征进行部分分箱处理,首先选择参与分箱的特征数量为n的特征,通过特征分箱转换为离散型特征,与m个离散特征进行融合,此m+n个离散特征被用来输入至注意力层(attention layer)进行特征交互的点积计算,n个连续性特征除了通过注意力层的求和计算得到加权结果,也会输入至深度神经网络(hidden layer)进行矩阵运算,两部分的结果通过sigmoid激活函数进行统一输出得到最终结果。通过自动化迭代模块,设置n的迭代范围,对以上步骤进行迭代,每次迭代保留最优分箱方案及参数,该方法在下文进行基线方法对比时称为sparse filling autoint。
19、所述步骤s4我们进行了基线方法性能对比。为了获得最优的连续型特征分箱方案和对应的模型性能,我们采用了自动化部分特征分箱和迭代步骤。在相同的数据集、清洗、填充和编码方式下,我们输出了基线方法的性能,然后与本文方法进行了性能指标对比。
20、所述特征交互点击率预测模型在金融数据集上,特征交互点击率预测模型在预测精度和泛化能力上超越了传统的机器学习方法,如评分卡。传统方法主要考虑单个特征对预测目标的影响,而未涉及特征间的交互信息。然而,在实际金融场景中,特征间的复杂交互作用对预测结果有着重要影响。特征交互点击率预测模型通过数学计算将两个或多个特征组合,实现样本空间的非线性变换,增加模型的非线性能力。这种方法能挖掘出不同特征组合的特征信息,更有效地预测点击率。此外,此模型还能自动选择重要的特征和组合,避免人工选择的繁琐过程,提高模型的自动化程度和可解释性。在连续性特征群金融数据集上应用此模型,能更充分地利用数据中的信息,捕捉特征之间的交互作用,提高预测的准确性和可靠性。这对金融行业的风险评估、客户分群、广告投放等应用场景具有重大意义。
21、所述方法创新性地自动选择部分连续型特征进行分箱操作,以填充离散特征群。这种方法突破了传统的异常值检测和缺失值处理方式,引入了连续特征的离散化处理,并通过网格化搜索模块进行自动迭代,以寻找最佳的特征转换方式。对于深度学习模型,通常只需要对连续特征进行标准化处理,并对离散特征进行标签化即可。然而,对于金融数据集中的连续特征群,这种方法无法充分发挥点击率预测模型中的高阶特征交互优势。为了解决这个问题,该方法选择了适量的连续性特征进行离散化处理,以填充离散特征群。这种离散特征填充方法在保留深度神经网络(dnn)的特征提取深度的同时,通过增加注意力点积模块的高阶特征交互组合能力,对模型结果的权重进行了进一步优化。这种方法提升了点击率预测模型的性能,使其更准确地捕捉和理解金融数据中的复杂模式和趋势。总的来说,这种方法通过创新地处理连续性特征,增强了点击率预测模型的特征交互能力,提高了模型的预测精度和泛化能力。这种自动化的特征工程方法为金融数据分析提供了一种新的、有效的工具,有助于更好地理解和管理金融风险,优化决策制定。
22、所述搭建网格化搜索模块进行自动化迭代的过程中,该方法特别针对算法模型的参数和连续型特征分箱数量的组合进行了设计,通过设定参与分箱的特征数量范围变化n和模型网络深度h的不同组合,模型能够自动化迭代所有参数组合下的性能结果,这种方法允许模型在连续性特征群金融数据集上进行全面搜索,以找到最优的分箱特征数量和网络深度的组合,它通过细致的参数调整和性能评估,使模型能够更好地适应数据集的特性和需求,网格化搜索模块的设计与实现,使得模型的优化过程更加系统、高效,它通过自动化迭代,将特征分箱数量和模型网络深度作为重要参数进行考虑,从而更准确地定位最优参数组合,最终,该方法能够输出最优结果及对应的n和h,这些信息对于在该连续性特征群金融数据集上获得最优模型性能至关重要,通过这种方法,我们能够更加准确地理解和预测金融数据中的复杂模式,提高风险评估、客户分群等关键金融应用的性能。
23、与现有技术相比,本发明具有如下有益效果:
24、1.本文选取了logistic regression、lightgbm、autoint作为基线方法,本文方法为sf-autoint(sparse filling autoint)在auc,ks,precision,recall性能指标上的表现如下所示:
25、
26、本文的方法(sf autoint)相对于autoint算法,添加了自动化特征分箱预处理部分。在precision保持稳定的情况下,auc、ks和recall指标均有显著提升。这是因为在连续型特征群数据集上,autoint算法无法获得足够的特征交互信息用于客群分类,它几乎仅仅依靠深度神经网络部分进行潜在信息提取。而本文的方法通过选取部分连续型特征进行分箱,用来填充离散特征群,可以在不损失深度神经网络的信息的情况下,发挥该算法的核心部分interacting的高阶特征交互能力。通过这种特征分箱方法,我们可以获得特征的高阶交互信息,这些信息可以协助分类,从而提高模型的性能。
27、具体来说,对于连续型特征,它们通常具有较高的信息含量,但在autoint算法中,由于其基于深度学习模型的特性,它难以直接利用这些特征的信息。通过将连续型特征进行分箱处理,我们可以将这些特征转换为离散型特征,从而使得autoint算法可以更好地利用这些特征的信息。
28、此外,对于一些特殊的连续型特征,比如时间序列数据或者具有特定分布的数值型数据,它们的特征交互往往比较复杂,难以直接被模型所捕捉。通过自动化特征分箱方法,我们可以对这些特征进行适当的处理,从而更好地发掘它们与目标变量之间的关系。
29、总的来说,自动化特征分箱方法是一种有效的特征处理技术,它可以提高autoint算法的性能,同时也可以扩展autoint算法的应用范围。通过该方法,我们可以更好地发掘连续型特征的信息,从而进一步提高模型的性能。
30、2.相比于传统机器学习算法,深度学习方法在整体模型性能上有着明显的提升。这种提升主要得益于其对高阶特征交互的自动挖掘和自动化特征分箱方法。在传统机器学习算法中,通常需要对特征进行逐个分析,这种方法不仅繁琐,而且容易遗漏一些重要的特征组合。相比之下,深度学习算法能够自动地挖掘特征之间的交互组合,从而获取更丰富的特征信息。
31、通过挖掘特征交互组合的信息,深度学习算法能够更好地提升模型的正负样本区分度。在许多应用场景中,正负样本的区分度往往会对模型的性能产生重要影响。如果模型能够准确地识别出正样本和负样本,那么它的性能就会更好。而深度学习算法在这方面具有较大的优势,因为它能够自动地学习和挖掘特征之间的复杂关系,从而更好地区分正负样本。
32、总之,深度学习算法在整体模型性能上的提升效果之所以明显,主要是得益于其对高阶特征交互的自动挖掘和自动化特征分箱方法。这些方法不仅提高了模型的精度和泛化能力,还降低了人工干预的强度,使得模型更具有可扩展性和可维护性。
- 还没有人留言评论。精彩留言会获得点赞!